Linking Artificial Intelligence Principles
Artificial Intelligence principles define social and ethical considerations to develop future AI. They come from research institutes, government organizations and industries. All versions of AI principles are with different considerations covering different perspectives and making different emphasis. None of them can be considered as complete and can cover the rest AI principle proposals. Here we introduce LAIP, an effort and platform for linking and analyzing different Artificial Intelligence Principles. We want to explicitly establish the common topics and links among AI Principles proposed by different organizations and investigate on their uniqueness. Based on these efforts, for the long-term future of AI, instead of directly adopting any of the AI principles, we argue for the necessity of incorporating various AI Principles into a comprehensive framework and focusing on how they can interact and complete each other.
💡 Research Summary
The paper addresses the growing fragmentation of Artificial Intelligence (AI) governance documents. Over the past decade, research institutes, governmental bodies, and industry consortia have each published their own AI principle sets, resulting in a landscape of dozens of overlapping yet distinct guidelines. While many comparative studies have examined subsets of these documents, none have attempted a systematic, large‑scale linking of all existing proposals. To fill this gap, the authors introduce LAIP (Linking Artificial Intelligence Principles), an analytical platform that extracts, maps, and visualizes the semantic relationships among AI principles worldwide.
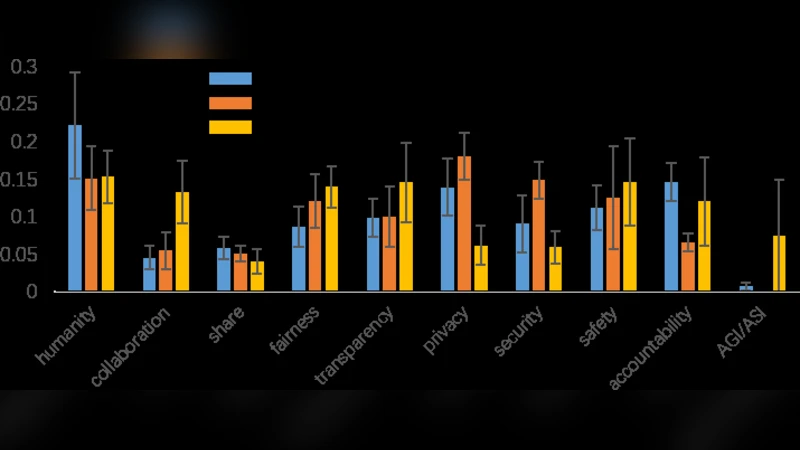
Data collection began with a comprehensive crawl of publicly available AI principle statements, yielding roughly thirty‑plus documents spanning continents and sectors. Each text underwent rigorous preprocessing: tokenization, stop‑word removal, and part‑of‑speech tagging, followed by contextual embedding generation using multilingual BERT models. To capture both term frequency importance and contextual nuance, the authors combined TF‑IDF weighting with BERT embeddings, producing a hybrid feature space for topic extraction. Hierarchical clustering on this space identified a stable set of 20–30 thematic clusters, the most salient of which included Transparency, Accountability, Fairness, Privacy Protection, Safety, Sustainability, and Human Rights.
With topics in hand, the platform constructs a weighted graph where nodes represent individual principle documents and edges encode shared topics. Edge weights are calculated as the product of the number of shared topics and the aggregate importance of those topics (derived from node centrality scores). Graph‑theoretic analysis—using NetworkX for centrality metrics (degree, betweenness, eigenvector) and community detection algorithms—revealed a dense core of principles that repeatedly emphasize Transparency, Accountability, and Fairness. These core topics exhibit high degree and eigenvector centrality, indicating they act as “glue” across the entire corpus. Conversely, peripheral clusters such as Environmental Sustainability or Cultural Diversity appear only in a handful of documents (e.g., European Union guidelines, specific corporate policies) and occupy low‑centrality positions, highlighting their specialized nature.
To quantify the distinctiveness of each principle set, the authors propose a “Uniqueness Score.” This metric combines the proportion of exclusive topics within a document and the weighted significance of those topics in the overall network. High uniqueness scores flag documents that embed region‑specific, sector‑specific, or culturally nuanced considerations—information that can be crucial for policymakers seeking to tailor global standards to local contexts.
The paper then leverages these insights to outline a modular, hierarchical framework for future AI governance. Core topics form a “mandatory set” that should be codified into law or binding regulation, while peripheral topics constitute a “supplementary set” that can be adopted voluntarily or contextually. By explicitly mapping how mandatory and supplementary elements interact, the framework encourages a composable approach: stakeholders can assemble a principle bundle that satisfies universal ethical imperatives while also addressing domain‑specific concerns.
Limitations are candidly discussed. The reliance on English‑centric multilingual BERT models may under‑represent subtle semantic variations in non‑English documents, potentially biasing topic extraction. Moreover, edge weight calibration currently depends on researcher‑defined parameters, introducing subjectivity. The authors suggest future work on incorporating truly multilingual language models (e.g., XLM‑R) and employing meta‑learning techniques to automatically optimize weighting schemes.
In summary, LAIP offers a reproducible, data‑driven methodology for linking disparate AI principle statements, revealing both the common ethical backbone and the unique contributions of individual proposals. By visualizing these relationships and providing quantitative metrics of overlap and uniqueness, the platform equips scholars, regulators, and industry leaders with the tools needed to construct a more coherent, inclusive, and adaptable global AI governance architecture.
Comments & Academic Discussion
Loading comments...
Leave a Comment