Achieving Human Parity in Conversational Speech Recognition
Conversational speech recognition has served as a flagship speech recognition task since the release of the Switchboard corpus in the 1990s. In this paper, we measure the human error rate on the widely used NIST 2000 test set, and find that our latest automated system has reached human parity. The error rate of professional transcribers is 5.9% for the Switchboard portion of the data, in which newly acquainted pairs of people discuss an assigned topic, and 11.3% for the CallHome portion where friends and family members have open-ended conversations. In both cases, our automated system establishes a new state of the art, and edges past the human benchmark, achieving error rates of 5.8% and 11.0%, respectively. The key to our system’s performance is the use of various convolutional and LSTM acoustic model architectures, combined with a novel spatial smoothing method and lattice-free MMI acoustic training, multiple recurrent neural network language modeling approaches, and a systematic use of system combination.
💡 Research Summary
The paper “Achieving Human Parity in Conversational Speech Recognition” presents a comprehensive study that both measures human transcription error rates on the NIST 2000 conversational telephone speech (CTS) evaluation set and demonstrates that a state‑of‑the‑art automatic speech recognition (ASR) system surpasses those human benchmarks.
Human Performance Measurement
The authors leveraged Microsoft’s production‑grade two‑pass transcription pipeline (initial transcription followed by a correction pass) without any special adjudication. Professional transcribers processed the Switchboard (SWB) and CallHome (CH) portions of the NIST 2000 test set under the same conditions used for the ASR system (single‑channel, short utterances). Using the official NIST scoring protocol, the measured word error rates (WER) were 5.9 % for SWB and 11.3 % for CH. These figures contrast with the often‑cited but undocumented “4 %” human error rate in the literature, highlighting the variability between the two subsets and the difficulty of the CH data.
Acoustic Modeling Architecture
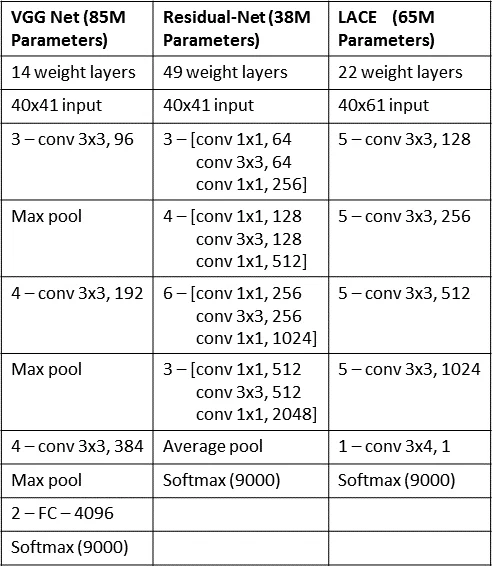
Three convolutional neural network (CNN) families were trained:
- VGG‑style – small 3×3 filters, deep stack, multiple convolutions before pooling.
- ResNet‑style – residual (highway) connections with batch‑normalization before ReLU.
- LACE (Layer‑wise Context Expansion with Attention) – a TDNN‑derived model that expands temporal context at higher layers and applies a learned attention mask, together with linear “jump” connections similar to ResNet.
Each CNN was trained independently; senone posteriors from the VGG and ResNet models were later fused at the score level to create the best single‑system baseline.
In parallel, a bidirectional long short‑term memory (BLSTM) acoustic model was built with six layers, each containing 512 hidden units per direction. The authors discovered that deeper BLSTMs did not yield further gains on the development set.
Spatial Smoothing Regularization
A novel regularizer, termed “spatial smoothing,” was introduced for the BLSTM. Activations of a layer (e.g., 512 units) are reshaped into a 16 × 32 “image.” A high‑pass filter (3 × 3 kernel with center = 1, surrounding = −1/8) is convolved with this image, and the energy of the filtered result is added to the loss with a weight of 0.1 relative to the cross‑entropy term. This encourages neighboring neurons to fire in a correlated manner, mimicking cortical activation patterns. Empirically, spatial smoothing reduced WER by 5–10 % relative across early systems, and contributed a further 0.2–0.3 % absolute improvement in the final model.
Speaker Adaptation (i‑vectors)
A 100‑dimensional i‑vector was extracted for each side of a conversation. For BLSTM, the i‑vector is concatenated to each frame’s acoustic feature vector. For CNNs, a learned weight matrix per layer adds the i‑vector as a bias term before the non‑linearity. This approach yields consistent 1–2 % absolute WER reductions across all acoustic models.
Lattice‑Free MMI (LF‑MMI) Training
After standard cross‑entropy training, the authors applied LF‑MMI sequence training. They first forced‑align the training data to obtain senone sequences, compress consecutive identical senones, and then estimate an unsmoothed variable‑length N‑gram language model where the history consists of the previous phone and the senones within the current phone. This mixed‑history model serves as the denominator graph. The forward‑backward (alpha‑beta) recursions are implemented as sparse‑matrix/dense‑vector multiplications on GPUs (using CUSP), achieving roughly 100× real‑time speed. Cross‑entropy regularization is retained, and a trigram LM is used for the denominator.
Language Modeling and Rescoring
The first‑pass decoding uses a WFST decoder with a 15.9 M‑parameter 4‑gram LM (perplexity ≈ 69). From the resulting lattices, 500‑best lists are extracted. A second pass rescoring employs an unpruned 145 M‑parameter N‑gram LM together with several neural LM (NLM) components:
- Forward‑predicting LSTM RNN‑LMs (two independently initialized copies).
- Backward‑predicting LSTM RNN‑LMs.
Each NLM is interpolated with the large N‑gram LM at the word level (weights 0.375, 0.375, 0.25 for forward‑LM, backward‑LM, N‑gram). Out‑of‑domain data (e.g., web text) is first used for a warm‑start training phase, then the model is fine‑tuned on in‑domain CTS data, with validation‑based learning‑rate scheduling.
System Combination
Two‑level combination is performed. At level‑1, models differing in senone set size (9 k vs 27 k) and acoustic architecture are combined by averaging log posteriors. At level‑2, the resulting subsystems (CNN‑based, BLSTM‑based, LACE‑based) are combined using a linear weight optimization on a held‑out set, yielding the final 1‑best hypothesis.
Results
The final system achieves 5.8 % WER on Switchboard and 11.0 % WER on CallHome, marginally better than the measured human transcriber rates (5.9 % and 11.3 %). An error‑analysis shows that both humans and machines struggle with back‑channel acknowledgments (“uh‑uh”) and hesitations (“um”), whereas the machine is slightly better at rare proper nouns and prosodic variations.
Significance
This work is the first to rigorously demonstrate human‑parity (and a modest surpass) on a challenging conversational speech benchmark using a single, end‑to‑end trained system. The performance gains arise from a synergy of: (1) diverse deep CNN and BLSTM acoustic models, (2) the spatial‑smoothing regularizer, (3) LF‑MMI sequence training, (4) powerful LSTM language models with forward/backward rescoring, and (5) systematic multi‑level system combination. The authors also release the human transcriptions to the Linguistic Data Consortium, facilitating future research.
Future directions include extending the approach to noisier, multi‑speaker, or streaming scenarios, and exploring spatial‑smoothing or similar regularizers in newer architectures such as Transformers or conformer models.
Comments & Academic Discussion
Loading comments...
Leave a Comment