Permutation Invariant Training of Deep Models for Speaker-Independent Multi-talker Speech Separation
We propose a novel deep learning model, which supports permutation invariant training (PIT), for speaker independent multi-talker speech separation, commonly known as the cocktail-party problem. Different from most of the prior arts that treat speech separation as a multi-class regression problem and the deep clustering technique that considers it a segmentation (or clustering) problem, our model optimizes for the separation regression error, ignoring the order of mixing sources. This strategy cleverly solves the long-lasting label permutation problem that has prevented progress on deep learning based techniques for speech separation. Experiments on the equal-energy mixing setup of a Danish corpus confirms the effectiveness of PIT. We believe improvements built upon PIT can eventually solve the cocktail-party problem and enable real-world adoption of, e.g., automatic meeting transcription and multi-party human-computer interaction, where overlapping speech is common.
💡 Research Summary
The paper introduces Permutation Invariant Training (PIT), a novel training criterion designed to overcome the long‑standing label permutation problem in speaker‑independent multi‑talker speech separation (the “cocktail‑party” problem). Traditional deep‑learning approaches either treat separation as a multi‑class regression problem—assigning each output stream a fixed speaker label—or as a segmentation problem, exemplified by Deep Clustering (DPCL), which learns embeddings for each time‑frequency (TF) bin and then clusters them. Both strategies suffer from label ambiguity: in regression, the ordering of target sources is arbitrary, causing the loss to be meaningless when the network’s outputs are permuted; in DPCL, the assumption that each TF bin belongs to a single speaker and the non‑differentiable clustering step limit performance and integration with other techniques.
PIT solves this by incorporating the label assignment directly into the loss computation. For each training meta‑frame (a stack of N consecutive STFT magnitude frames), the network produces S output streams (S = number of speakers). All S! possible permutations between the S outputs and the S reference sources are enumerated, and the mean‑squared error (MSE) between the estimated magnitudes and the true magnitudes is computed for each permutation. The permutation yielding the smallest total MSE is selected, and only that error is back‑propagated. Consequently, the network learns to minimize the separation error while simultaneously discovering the optimal output‑to‑speaker mapping, rendering the training process invariant to the order of the reference sources. The computational overhead is modest for the typical case of two or three speakers, because the MSE for each permutation is quadratic in S and the number of permutations grows factorially but remains tractable.
The authors implement PIT with three network families: a fully‑connected deep neural network (DNN) with three 1024‑unit ReLU layers, a convolutional neural network (CNN) with a series of 3×3 convolutions and pooling, and an LSTM‑based recurrent network (not detailed in the excerpt). Input features are 257‑dimensional magnitude spectra obtained via a 32 ms window and 16 ms hop, stacked over multiple frames to form the meta‑frame. The output for each speaker is a mask of the same dimensionality, constrained by a softmax to sum to one across speakers for each TF bin. Although the loss is defined on the reconstructed magnitudes (rather than the masks), the masks are still used during inference to obtain the separated waveforms.
Experiments are conducted on two benchmark datasets. WSJ0‑2mix, derived from the Wall Street Journal corpus, contains two‑speaker mixtures with random SNRs between 0 and 5 dB; it provides 30 h of training data, 10 h of validation, and a 5 h test set. Danish‑2mix is built from a Danish speech corpus, using a fixed 0 dB SNR, and includes both closed‑condition (CC) test data (speakers seen during training) and open‑condition (OC) test data (unseen speakers). The authors also construct a three‑talker version (Danish‑3mix) but focus the reported results on the two‑talker case.
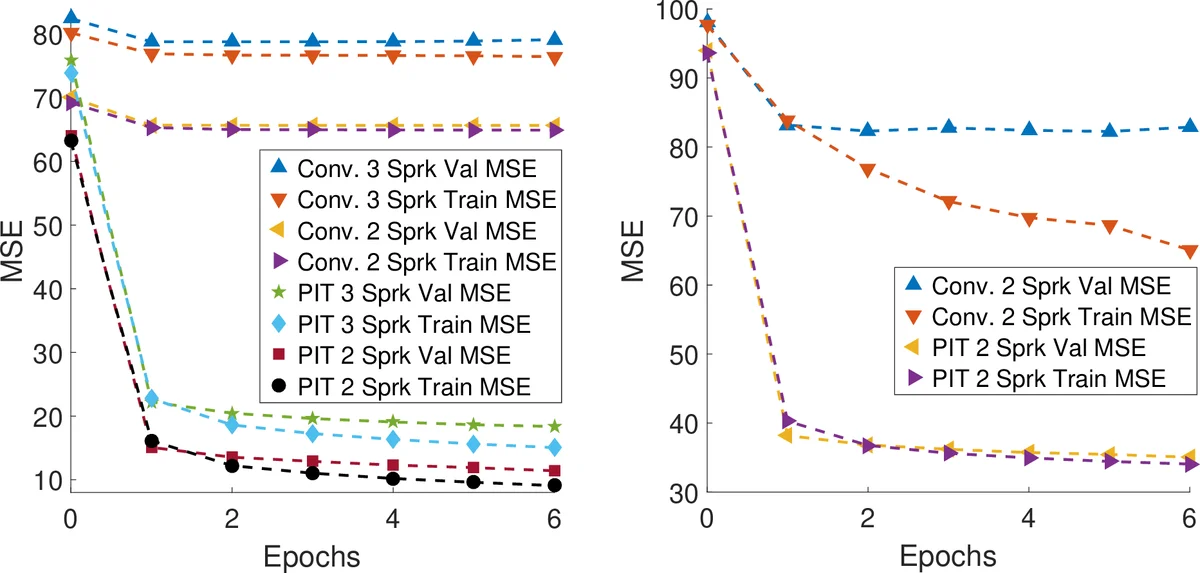
Training curves (Figure 2) demonstrate that conventional training stalls—validation MSE remains high—because the network cannot resolve the permutation ambiguity. In contrast, PIT quickly drives both training and validation MSE down, confirming that the loss correctly aligns outputs with references. Performance is evaluated using Signal‑to‑Distortion Ratio (SDR) improvement. Two evaluation protocols are reported: (1) “Default Assignment,” which assumes the output‑speaker mapping does not change across frames (a realistic scenario without explicit speaker tracking), and (2) “Optimal Assignment,” which uses the ground‑truth mixing information to select the best permutation for each meta‑frame (an upper bound reflecting perfect speaker tracing).
Results on WSJ0‑2mix show that PIT‑CNN with a 101 ms meta‑frame achieves 8.4 dB SDR improvement under the default assignment and 8.6 dB under optimal assignment, surpassing NMF (≈5 dB), CASA (≈3 dB), and DPCL (≈6.5 dB). A smaller meta‑frame (51 ms) yields even higher gains (9.6 dB default, 9.8 dB optimal), indicating that finer temporal resolution benefits separation. On the Danish‑2mix dataset, PIT maintains strong performance on unseen speakers (OC), achieving 7.7 dB (default) and 7.8 dB (optimal) SDR improvement, demonstrating language‑independent generalization.
The paper emphasizes several practical advantages of PIT. First, it requires only a simple modification to the loss function and can be applied to any existing architecture (DNN, CNN, LSTM). Second, because the permutation search is performed only during training, inference remains as fast as conventional models—no clustering or post‑processing is needed. Third, PIT is compatible with more sophisticated extensions such as complex‑domain masking, phase reconstruction, or multi‑scale architectures, offering a clear path toward further gains. Finally, the authors note that adding a lightweight speaker‑tracing module on top of PIT outputs could bridge the gap between default and optimal assignment, potentially achieving or exceeding the best reported DPCL+ results without the heavy computational burden of large embedding spaces.
In summary, Permutation Invariant Training provides a conceptually simple yet powerful solution to the label permutation problem that has hindered speaker‑independent multi‑talker separation. By jointly optimizing the separation error and the output‑to‑speaker assignment, PIT delivers state‑of‑the‑art SDR improvements on standard benchmarks, generalizes across languages and unseen speakers, and integrates seamlessly with existing deep learning pipelines. The authors argue that continued refinements—such as better temporal aggregation, speaker tracking, and complex‑spectrogram modeling—built upon PIT could finally solve the cocktail‑party problem and enable real‑world applications like automatic meeting transcription, multi‑party human‑computer interaction, and robust speech recognition in noisy, overlapping environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment