Feature Learning in Deep Neural Networks - Studies on Speech Recognition Tasks
Recent studies have shown that deep neural networks (DNNs) perform significantly better than shallow networks and Gaussian mixture models (GMMs) on large vocabulary speech recognition tasks. In this paper, we argue that the improved accuracy achieved by the DNNs is the result of their ability to extract discriminative internal representations that are robust to the many sources of variability in speech signals. We show that these representations become increasingly insensitive to small perturbations in the input with increasing network depth, which leads to better speech recognition performance with deeper networks. We also show that DNNs cannot extrapolate to test samples that are substantially different from the training examples. If the training data are sufficiently representative, however, internal features learned by the DNN are relatively stable with respect to speaker differences, bandwidth differences, and environment distortion. This enables DNN-based recognizers to perform as well or better than state-of-the-art systems based on GMMs or shallow networks without the need for explicit model adaptation or feature normalization.
💡 Research Summary
The paper investigates why deep neural networks (DNNs) consistently outperform shallow neural networks and Gaussian mixture model (GMM) based acoustic models on large‑vocabulary speech recognition tasks. The authors argue that the key advantage of DNNs lies in their ability to learn internal representations that are both discriminative for phonetic classification and invariant to many sources of variability in speech (speaker differences, bandwidth changes, environmental noise, etc.).
Conceptual view of a DNN
A CD‑DNN‑HMM is interpreted as a two‑step model: (1) a stack of L nonlinear transforms that map the raw acoustic feature vector x into a high‑level representation vL, and (2) a log‑linear soft‑max classifier that estimates posterior probabilities p(y|x) from vL. When the lower L layers are fixed, training the soft‑max layer is equivalent to training a conditional maximum‑entropy model on learned features, thus eliminating manual feature engineering.
Depth improves performance
Experiments on the Switchboard Hub5’00 test set (309 h training data) show a monotonic reduction in word error rate (WER) as the number of hidden layers increases from 1 to 9, with a 7‑layer network (7 × 2048 units) achieving 17.1 % WER compared with 23.6 % for a strong GMM‑HMM baseline—a 28 % relative reduction. Even when the total number of parameters is held constant, deep but narrower networks outperform shallow, wide networks, confirming that depth, not merely capacity, drives the gains. Gains saturate after about 7–9 layers, indicating a trade‑off between additional depth and computational cost.
Feature invariance to small perturbations
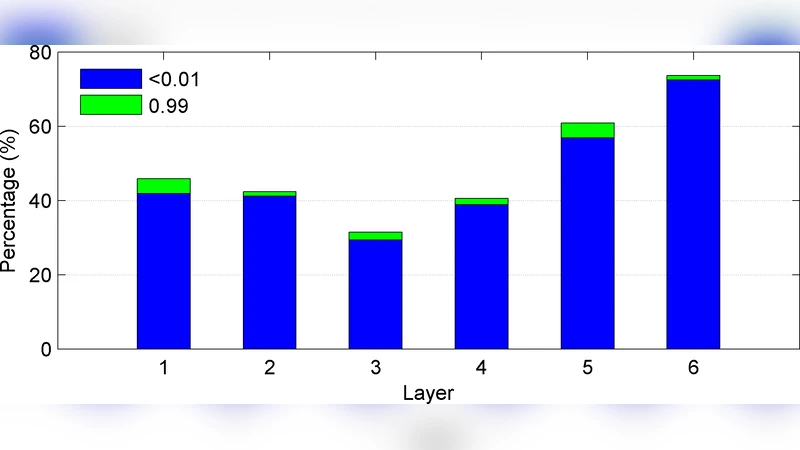
A theoretical analysis shows that a small input perturbation δ propagates through each layer as δℓ+1 ≈ diag(σ′(zℓ)) Wℓᵀ δℓ. Because most weights in a well‑trained DNN are small (≈98 % < 0.5) and the derivative of the sigmoid is bounded by 0.25, the norm of the perturbation shrinks at each successive layer. Empirically, the authors observe a high proportion of saturated (inactive) neurons and a decreasing average norm of the Jacobian term across layers, confirming that higher‑layer representations become progressively less sensitive to input variations while still amplifying differences near decision boundaries.
“Learning by seeing” – the need for representative training data
The invariance property holds only for perturbations that are small relative to the training distribution. When test data differ substantially (e.g., narrow‑band vs. wide‑band speech), a DNN trained solely on wide‑band data suffers a dramatic WER increase (53.5 % on 8 kHz test versus 27.5 % on 16 kHz). Adding a modest amount of narrow‑band data (mixed‑bandwidth training) restores performance on both domains (≈28 % WER). Layer‑wise Euclidean distances and top‑layer KL divergences show that the mixed‑bandwidth DNN learns to treat the bandwidth difference as an irrelevant variation, suppressing it through successive nonlinear transforms. This experiment underscores that DNNs cannot extrapolate to unseen conditions; they must be exposed to the full range of variability during training.
Robustness to speaker variation
Traditional speaker adaptation techniques (VTLN, fMLLR) operate directly on acoustic features and can be applied to DNN inputs. However, the authors demonstrate that a well‑trained DNN already learns speaker‑invariant representations, achieving comparable or better WER than GMM‑HMM systems that employ explicit adaptation. The deep architecture automatically normalizes speaker‑specific spectral characteristics, reducing the need for separate adaptation pipelines.
Noise robustness (Aurora 4)
In the Aurora 4 benchmark, which includes additive noise and channel distortion, the DNN matches state‑of‑the‑art GMM‑based systems without any explicit noise adaptation (e.g., VTS, MLLR). This further validates the claim that deep nonlinear feature learning yields representations that are intrinsically robust to common acoustic degradations.
Practical implications and limitations
The findings suggest that deep acoustic models can simplify ASR system design: fewer hand‑crafted adaptation steps, lower latency, and reduced engineering effort. Nevertheless, the models are still data‑hungry; comprehensive coverage of speaker, channel, noise, and bandwidth conditions in the training set is essential. When such coverage is lacking, performance degrades sharply. Future work should explore data‑augmentation, domain‑adaptive pre‑training, and methods to increase the extrapolation capability of deep models.
Conclusion
Depth in neural networks provides powerful nonlinear feature transformations that progressively attenuate small input perturbations, yielding internal representations that are both discriminative and invariant to many sources of speech variability. When the training corpus adequately samples the variability space, DNN‑based recognizers achieve or surpass the performance of sophisticated GMM‑HMM systems without explicit adaptation or feature normalization. The primary limitation remains the need for representative training data; without it, DNNs cannot generalize to substantially different test conditions.
Comments & Academic Discussion
Loading comments...
Leave a Comment