Singing Voice Separation Using a Deep Convolutional Neural Network Trained by Ideal Binary Mask and Cross Entropy
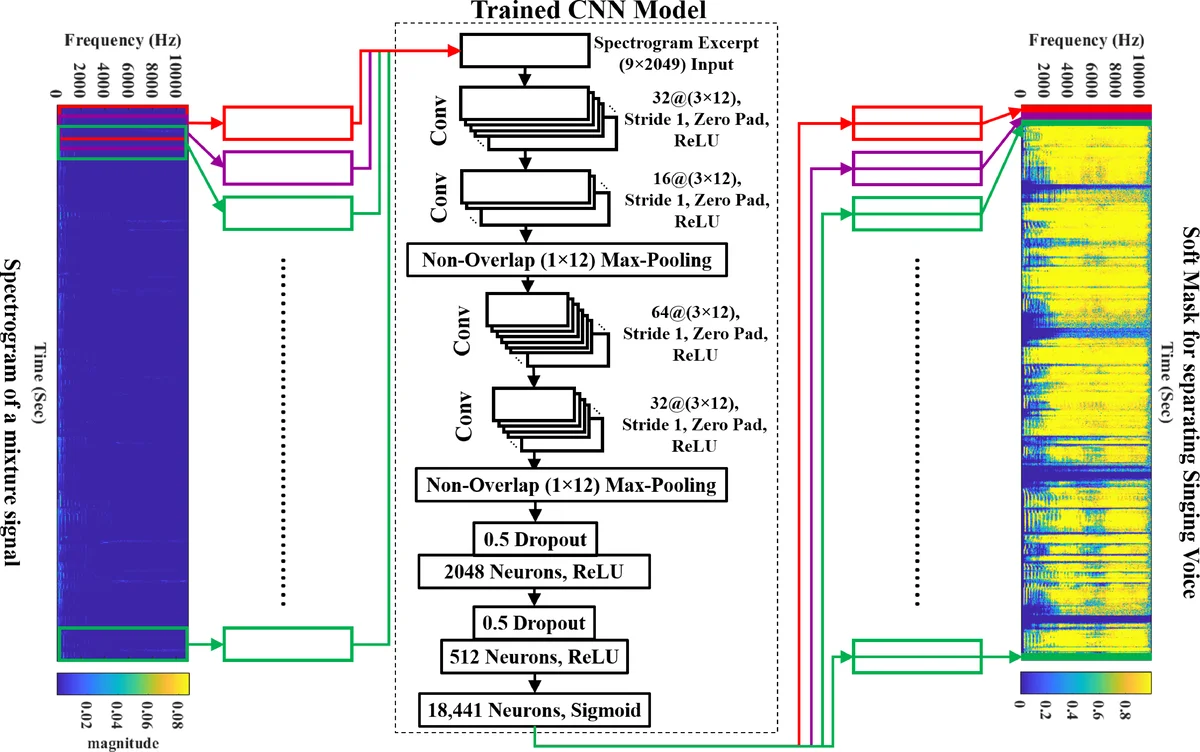
Separating a singing voice from its music accompaniment remains an important challenge in the field of music information retrieval. We present a unique neural network approach inspired by a technique that has revolutionized the field of vision: pixel-wise image classification, which we combine with cross entropy loss and pretraining of the CNN as an autoencoder on singing voice spectrograms. The pixel-wise classification technique directly estimates the sound source label for each time-frequency (T-F) bin in our spectrogram image, thus eliminating common pre- and postprocessing tasks. The proposed network is trained by using the Ideal Binary Mask (IBM) as the target output label. The IBM identifies the dominant sound source in each T-F bin of the magnitude spectrogram of a mixture signal, by considering each T-F bin as a pixel with a multi-label (for each sound source). Cross entropy is used as the training objective, so as to minimize the average probability error between the target and predicted label for each pixel. By treating the singing voice separation problem as a pixel-wise classification task, we additionally eliminate one of the commonly used, yet not easy to comprehend, postprocessing steps: the Wiener filter postprocessing. The proposed CNN outperforms the first runner up in the Music Information Retrieval Evaluation eXchange (MIREX) 2016 and the winner of MIREX 2014 with a gain of 2.2702 ~ 5.9563 dB global normalized source to distortion ratio (GNSDR) when applied to the iKala dataset. An experiment with the DSD100 dataset on the full-tracks song evaluation task also shows that our model is able to compete with cutting-edge singing voice separation systems which use multi-channel modeling, data augmentation, and model blending.
💡 Research Summary
The paper introduces a novel deep learning approach for separating singing voice from musical accompaniment, inspired by pixel‑wise image classification techniques that have transformed computer vision. The authors treat each time‑frequency (T‑F) bin of a spectrogram as a pixel and formulate the separation task as a binary classification problem: for each bin, decide whether the vocal energy dominates the accompaniment. To generate ground‑truth labels they compute the Ideal Binary Mask (IBM), assigning a value of 1 when the vocal magnitude exceeds the accompaniment magnitude, and 0 otherwise.
A convolutional neural network (CNN) is designed to predict directly a soft mask for the vocal source. The network receives as input a short spectrogram excerpt of 9 consecutive frames (≈104 ms) with 2049 frequency bins, analogous to a small image patch. Before the main classification stage, the CNN weights are pretrained as an auto‑encoder on isolated vocal spectrograms, allowing the model to learn a compact representation of vocal characteristics. The main architecture consists of several convolution‑pooling blocks followed by a 1×1 convolution and a sigmoid activation, producing a probability for each T‑F bin. The loss function is binary cross‑entropy between the predicted probabilities and the IBM, which encourages the network to output a mask that closely matches the ideal binary decision. This eliminates the need for the commonly used Wiener filter post‑processing step that many prior deep‑learning SVS systems rely on.
Experimental evaluation is performed on two benchmark datasets: iKala (≈76 min of audio) and DSD100 (≈216 min). On iKala, the proposed model achieves a Global Normalized Source‑to‑Distortion Ratio (GNSDR) improvement of 2.27 – 5.96 dB over the best existing systems, surpassing the MIREX 2014 winner and the 2016 runner‑up. On DSD100, the model’s performance is statistically indistinguishable from state‑of‑the‑art systems that employ multi‑channel modeling, extensive data augmentation, and model blending, despite being trained on a comparatively modest amount of data.
The authors discuss several advantages of their approach: (1) direct pixel‑wise mask prediction simplifies the pipeline and reduces computational overhead; (2) the IBM + cross‑entropy combination proves highly effective for mask learning; (3) pretraining as an auto‑encoder improves convergence and robustness, especially when training data are limited. They also acknowledge limitations: the binary nature of IBM can cause label ambiguity in bins where vocal and accompaniment energies are similar, and the current CNN does not explicitly model temporal dependencies, which recurrent networks (RNN, BLSTM) could capture.
Future work is suggested in three directions: extending the framework to multi‑label masks for separating multiple instrument sources, integrating recurrent or attention mechanisms to exploit temporal context, and designing lightweight architectures for real‑time deployment. By successfully transferring pixel‑wise classification concepts from vision to audio source separation, the paper offers a fresh perspective that could inspire further advances in music information retrieval and related audio processing fields.
Comments & Academic Discussion
Loading comments...
Leave a Comment