Analyzing Partitioned FAIR Health Data Responsibly
It is widely anticipated that the use of health-related big data will enable further understanding and improvements in human health and wellbeing. Our current project, funded through the Dutch National Research Agenda, aims to explore the relationship between the development of diabetes and socio-economic factors such as lifestyle and health care utilization. The analysis involves combining data from the Maastricht Study (DMS), a prospective clinical study, and data collected by Statistics Netherlands (CBS) as part of its routine operations. However, a wide array of social, legal, technical, and scientific issues hinder the analysis. In this paper, we describe these challenges and our progress towards addressing them.
💡 Research Summary
The paper “Analyzing Partitioned FAIR Health Data Responsibly” presents a multidisciplinary effort to combine two highly sensitive data sources—the Maastricht Study (a prospective clinical cohort) and Statistics Netherlands (CBS, a national statistical agency)—in order to investigate how socio‑economic factors influence the development of type‑2 diabetes. The authors frame the work within the FAIR principles (Findable, Accessible, Interoperable, Reusable) and organize the project into three interlocking work packages (WPs): Scientific, Technical, and Ethics‑Law‑Society (ELSI).
The Scientific WP defines the research question and selects variables from both data owners. From CBS they request hospitalization records, health‑care costs, and medication use; from the Maastricht Study they obtain lifestyle information, physical activity, diabetes status, functional health scores, and education level. The goal is twofold: (1) to test the hypothesized associations between lifestyle, health‑care utilization, and diabetes progression, and (2) to use this concrete use‑case as a benchmark for the privacy‑preserving infrastructure developed in the Technical WP.
The ELSI WP tackles the legal and ethical landscape, focusing primarily on the EU General Data Protection Regulation (GDPR) and its national implementation in the Netherlands. A central obstacle is the prohibition on using the Dutch national identifier (BSN) for research, which would otherwise provide a reliable linkage key. The authors therefore adopt a pseudonymisation strategy that replaces direct identifiers with hashed values salted with shared random strings. They discuss GDPR Article 4 (definition of personal data) and Article 87 (member‑state discretion on national identifiers), arguing that “compatible processing” may permit secondary use of already collected data if it aligns with the original legal basis. The ELSI team also engages in public outreach and regulatory dialogue to ensure that their interpretations of ambiguous legal provisions are socially acceptable and legally robust.
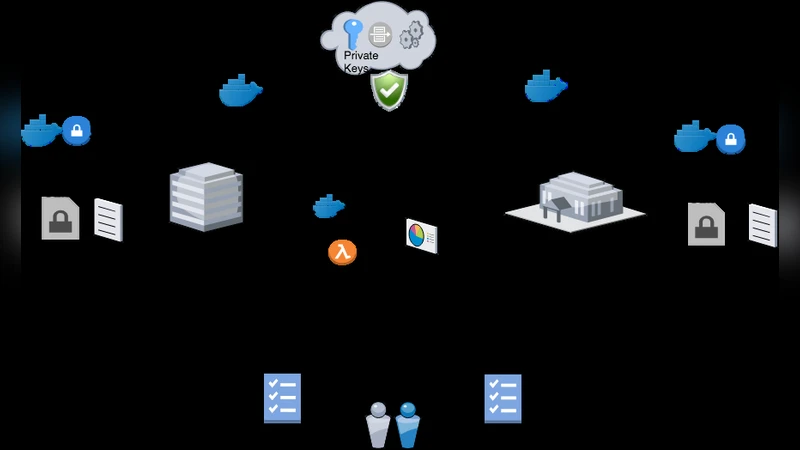
The Technical WP implements a distributed learning architecture based on the Personal Health Train (PHT) concept. In PHT, algorithmic “trains” (Docker containers) travel to data “stations” (CBS, Maastricht Study, and a Trusted Secure Environment (TSE) hosted within CBS). Each station authenticates the train, extracts the required variables, applies the shared hashing‑and‑salting routine to pseudonymise identifiers, encrypts the entire dataset with a public key, and forwards the ciphertext to the TSE. The TSE, isolated from external networks, decrypts the data using the corresponding private key and runs the analytical algorithms. This design eliminates the need to move raw data, reduces duplication, and provides a clear audit trail for data access. The authors also address the challenge of non‑unique matches caused by the size disparity between CBS (nation‑wide) and the Maastricht Study (a few thousand participants). By restricting the CBS sample to the same age range (40‑75) and geographic region (South Limburg), they shrink the candidate pool while acknowledging the increased re‑identification risk, which is mitigated by the strong pseudonymisation and encryption measures.
To evaluate the system, the authors propose three criteria: (1) security – verification of cryptographic protocols and access controls; (2) privacy – measurement of re‑identification risk and compliance with data minimisation; and (3) technical performance – assessment of analytical accuracy, scalability, and stability compared with a traditional centralized approach. Preliminary results suggest that the PHT‑based pipeline can reproduce the scientific findings while preserving privacy guarantees, though further benchmarking is required.
In conclusion, the paper demonstrates that, even under the stringent constraints of GDPR and national law, it is feasible to link and analyse partitioned health data responsibly. By integrating legal analysis, ethical engagement, and cutting‑edge distributed computing, the project offers a reusable blueprint for future big‑data health research that respects individual privacy, maintains public trust, and enables high‑impact scientific discovery.
Comments & Academic Discussion
Loading comments...
Leave a Comment