Private Topic Modeling
We develop a privatised stochastic variational inference method for Latent Dirichlet Allocation (LDA). The iterative nature of stochastic variational inference presents challenges: multiple iterations are required to obtain accurate posterior distrib…
Authors: Mijung Park, James Foulds, Kamalika Chaudhuri
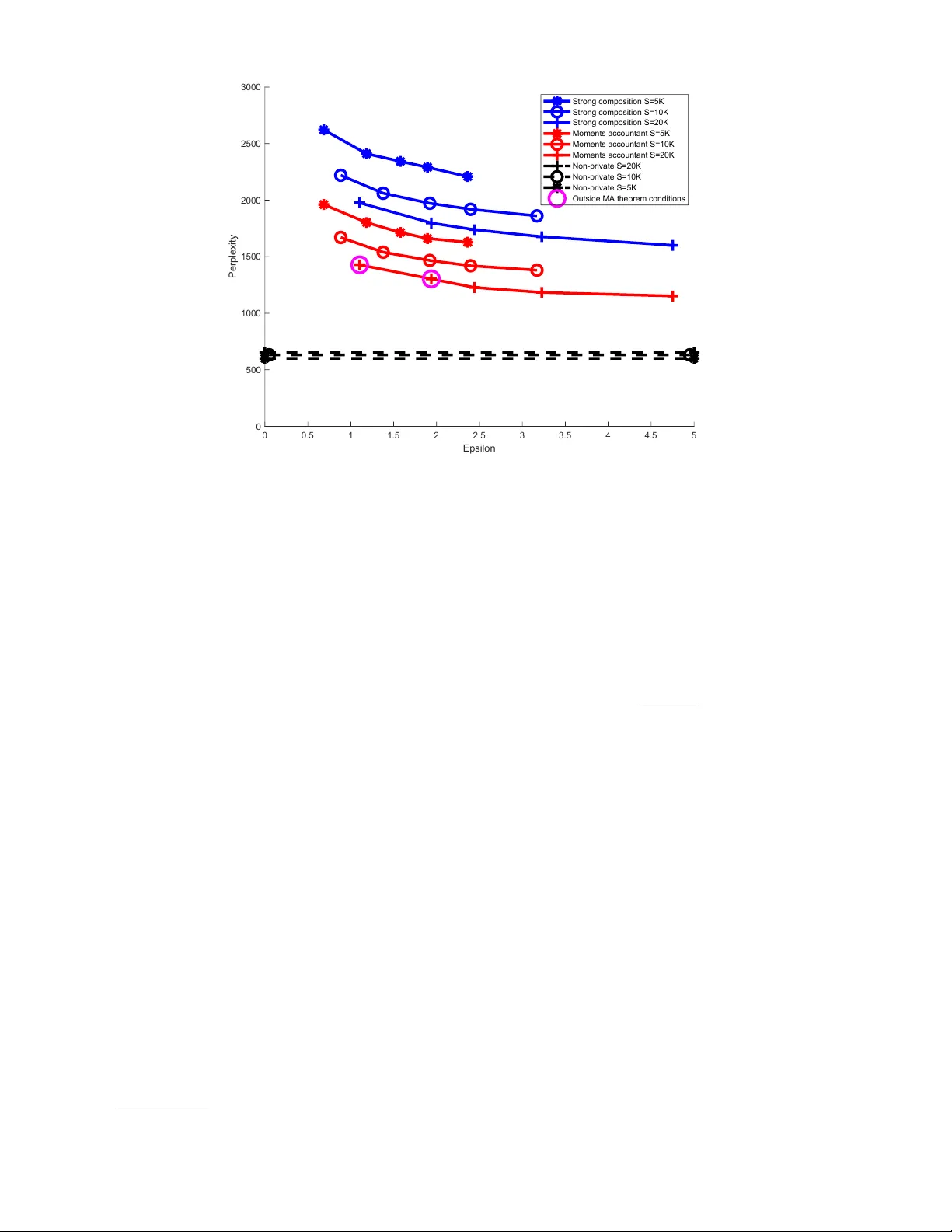
Priv ate T opic Mo deling Mijung P ark, Max Planck Institute for Intel ligent Systems & University of T¨ ubingen James F oulds, University of Maryland, Baltimor e County Kamalik a Chaudh uri, University of California, San Die go Max W elling, University of Amster dam Abstract W e dev elop a priv atised sto c hastic v ariational inference metho d for Laten t Dirichlet Allo cation (LD A). The iterativ e nature of sto chastic v ariational inference presen ts challenges: multiple itera- tions are required to obtain accurate p osterior distributions, yet each iteration increases the amount of noise that m ust b e added to achiev e a reasonable degree of priv acy . W e prop ose a practical algorithm that o v ercomes this c hallenge b y com bining: (1) an improv ed comp osition metho d for dif- feren tial priv acy , called the moments ac c ountant , which pro vides a tight bound on the priv acy cost of m ultiple v ariational inference iterations and thus significan tly decreases the amoun t of additiv e noise; and (2) priv acy amplification resulting from subsampling of large-scale data. F o cusing on conjugate exp onen tial family mo dels, in our priv ate v ariational inference, all the p osterior distributions will b e priv atised b y simply p erturbing exp ected sufficient statistics. Using Wikip edia data, w e illustrate the effectiv eness of our algorithm for large-scale data. 1 Bac kground Differen tial Priv acy (DP) is a formal definition of the priv acy prop erties of data analysis algo- rithms [1, 2]. A randomized algorithm M ( X ) is said to b e ( , δ )-differentially priv ate if P r ( M ( X ) ∈ S ) ≤ exp( ) P r ( M ( X 0 ) ∈ S ) + δ (1) for all measurable subsets S of the range of M and for all datasets X , X 0 differing by a single entry (either by excluding that entry or replacing it with a new entry). Here, an entry usually corresp onds to a single individual’s priv ate v alue. If δ = 0, the algorithm is said to b e -differentially priv ate, and if δ > 0, it is said to b e appr oximately differentially priv ate. In tuitiv ely , the definition states that the probabilit y of an y ev ent do es not change v ery m uc h when a single individual’s data is mo dified, thereb y limiting the amoun t of information that the algorithm rev eals ab out any one individual. W e observ e that M is a randomized algorithm, and randomization is ac hiev ed by either adding external noise, or by subsampling. In this pap er, w e use the “ include/exclude ” version of DP , in whic h differing by a single entry refers to the inclusion or exclusion of that entry in the dataset. V ariational inference for the conjugate exp onential mo dels V ariational inference is an optimization-based p osterior inference metho d, whic h simplifies to a tw o-step pro cedure when the mo del falls in to the Conjugate-Exp onen tial (CE) class of models. CE family mo dels satisfy t w o 1 conditions [3]: (1) The complete-data likelihoo d is in the exp onential family : p ( D n , l n | m ) = g ( m ) f ( D n , l n ) exp( n ( m ) > s ( D n , l n )) , (2) (2) The prior ov er m is conjugate to the complete-data lik eliho o d : p ( m | τ , ν ) = h ( τ , ν ) g ( m ) τ exp( ν > n ( m )) . (3) where natural parameters and sufficien t statistics of the complete-data lik eliho o d are denoted by n ( m ) and s ( D n , l n ), resp ectiv ely , and g , f , h are some known functions. The h yp erparameters are denoted b y τ (a scalar) and ν (a vector). The v ariational inference algorithm for a CE family mo del optimises the low er b ound on the mo del log marginal likelihoo d given by , L ( q ( l ) q ( m )) = Z d m d l q ( l ) q ( m ) log p ( l , D , m ) q ( l ) q ( m ) , (4) where we assume that the join t appro ximate p osterior distribution o v er the laten t v ariables and mo del parameters q ( l , m ) is factorised via the mean-field assumption as q ( l , m ) = q ( l ) q ( m ) = q ( m ) Q N n =1 q ( l n ) , and that eac h of the v ariational distributions also has the form of an exp onential family distribution. Computing the deriv atives of the v ariational lo w er b ound in Eq. 4 with respect to eac h of these v ariational distributions and setting them to zero yield the following tw o-step procedure. (1) First, given exp ected natural parameters ¯ n , the E-step computes: q ( l ) = N Y n =1 q ( l n ) ∝ N Y n =1 f ( D n , l n ) exp( ¯ n > s ( D n , l n )) = N Y n =1 p ( l n |D n , ¯ n ) . (5) Using q ( l ), it outputs exp ected sufficient statistics, the exp ectation of s ( D n , l n ) with probability density q ( l n ) : ¯ s ( D ) = 1 N N X n =1 h s ( D n , l n ) i q ( l n ) . (2) Second, given exp ected sufficient statistics ¯ s ( D ), the M-step computes: q ( m ) = h ( ˜ τ , ˜ ν ) g ( m ) ˜ τ exp( ˜ ν > n ( m )) , where ˜ τ = τ + N , ˜ ν = ν + N ¯ s ( D ) . (6) Using q ( m ), it outputs exp ected natural parameters ¯ n = h n ( m ) i q ( m ) . 2 Priv acy preserving VI algorithm for CE family The only place where the algorithm lo oks at the data is when computing the expected sufficient statistics ¯ s ( D ) in the first step. The exp ected sufficient statistics then dictates the exp ected nat- ural parameters in the second step. So, p erturbing the sufficient statistics leads to p erturbing b oth p osterior distributions q ( l ) and q ( m ). P erturbing sufficient statistics in exp onential fami- lies is also used in [4]. Existing work fo cuses on priv atising p osterior distributions in the context of p osterior sampling [5, 6, 7, 8], while our work fo cuses on priv atising appro ximate p osterior dis- tributions for optimisation-based approximate Bay esian inference. Supp ose there are tw o neigh- b ouring datasets D and D 0 , where there is only one datap oin t difference among them. W e also assume that the dataset is pre-pro cessed such that the L2 norm of any datapoint is less than 1. The maximum difference in the exp ected sufficient statistics given the datasets, e.g., the L- 1 sensitivity of the exp ected sufficien t statistics is given b y (assuming s is a vector of length L) ∆ s = max D , D 0 ,q ( l ) ,q ( l 0 ) P L l =1 1 N | E q ( l ) s l ( D , l ) − E q ( l 0 ) s l ( D 0 , l 0 ) | .Under some mo dels lik e LDA b elo w, ex- p ected sufficient statistic has a limited sensitivit y , in which case we add noise to each co ordinate of the exp ected sufficient statistics to comp ensate the maxim um change. 2 3 Priv acy preserving laten t Diric hlet allo cation (LD A) The most successful topic mo deling is based on LD A, where the generative pro cess is giv en by [9]. Its generativ e pro cess is given by • Dra w topics β k ∼ Diric hlet ( η 1 V ), for k = { 1 , . . . , K } , where η is a scalar hyperarameter. • F or each do cument d ∈ { 1 , . . . , D } – Dra w topic prop ortions θ d ∼ Diric hlet ( α 1 K ), where α is a scalar h yp erarameter. – F or each word n ∈ { 1 , . . . , N } ∗ Dra w topic assignments z dn ∼ Discrete( θ d ) ∗ Dra w w ord w dn ∼ Discrete( β z dn ) where each observ ed w ord is represented b y an indicator vector w dn ( n th word in the d th do cument) of length V , and where V is the n um b er of terms in a fixed vocabulary set. The topic assignment laten t v ariable z dn is also an indicator vector of length K , where K is the num b er of topics. The LD A model falls in the CE family , viewing z d, 1: N and θ d as tw o types of laten t v ariables: l d = { z d, 1: N , θ d } , and β as mo del parameters m = β . The conditions for CE are satisfied: (1) the complete-data likelihoo d is in exp onen tial family: p ( w d, 1: N , z d, 1: N , θ d | β ) ∝ f ( D d , z d, 1: N , θ d ) exp( P n P k [log β k ] > [ z k dn w dn ]) , where f ( D d , z d, 1: N , θ d ) ∝ exp([ α 1 K ] > [log θ d ] + P n P k z k dn log θ k d ); and (2) we hav e a conjugate prior o v er β k : p ( β k | η 1 V ) ∝ exp([ η 1 V ] > [log β k ]) , for k = { 1 , . . . , K } . F or simplicity , w e assume hyperpa- rameters α and η are set manually . Under the LD A mo del, we assume the v ariational p osteriors are giv en by • Discrete : q ( z k dn | φ k dn ) ∝ exp( z k dn log φ k dn ), with v ariational parameters for capturing the p oste- rior topic assignment, φ k dn ∝ exp( h log β k i q ( β k ) > w dn + h log θ k d i q ( θ d ) ) . • Diric hlet : q ( θ d | γ d ) ∝ exp( γ d > log θ d ) , where γ d = α 1 K + P N n =1 h z dn i q ( z dn ) , where these tw o distributions are computed in the E-step b ehind the priv acy wall. The exp e cted sufficien t statistics are ¯ s v k = 1 D P d P n h z k dn i q ( z dn ) w v dn = 1 D P d P n φ k dn w dn . Then, in the M-step, we compute the p osterior • Diric hlet : q ( β k | λ k ) ∝ exp( λ k > log β k ) , where λ k = η 1 V + P d P n h z k dn i q ( z dn ) w dn . Sensitivit y analysis In a large-scale data setting, it is imp ossible to handle the entire dataset at once. In such case, sto c hastic learning using noisy sufficient statistics computed on mini-batches of data. A t each learning step with a freshly drawn mini-batch of data (size S ), w e perturb the exp ected sufficient statistics. While each do cument has a different do cument length N d , we limit the maxim um length of any document to N by randomly selecting N w ords in a do cument if the num b er of w ords in the do cument is longer than N . W e add Gaussian noise to eac h comp onent of the exp ected sufficient statistics, which is a matrix of size K × V , ˜ ¯ s v k = ¯ s v k + Y v k , where Y v k ∼ N (0 , σ 2 (∆ ¯ s ) 2 ) , (7) where ¯ s v k = 1 S P d P n φ k dn w v dn , and ∆ ¯ s is the sensitivity . W e then map the p erturb ed comp onents to 3 0 if they b ecome negative. F or LDA, the worst-case sensitivity is given by ∆ ¯ s = max |D\D 0 | =1 s X k X v ( ¯ s v k ( D ) − ¯ s v k ( D 0 )) 2 , = max |D\D 0 | =1 v u u t X k X v 1 S X n S X d =1 φ k dn w v dn − 1 S − 1 X n S − 1 X d =1 φ k dn w v dn ! 2 , = max |D\D 0 | =1 v u u t X k X v S − 1 S 1 S − 1 X n S − 1 X d =1 φ k dn w v dn + 1 S X n φ k S n w v S n − 1 S − 1 X n S − 1 X d =1 φ k dn w v dn 2 , = max φ k S n , w v S n v u u t X k X v 1 S X n φ k S n w v S n − 1 S 1 S − 1 X n S − 1 X d =1 φ k dn w v dn ! 2 , = max φ k S n , w v S n v u u t X k X v 1 S X n φ k S n w v S n 2 , since 0 ≤ φ k dn ≤ 1, w v dn ∈ { 0 , 1 } , and we assume 0 ≤ 1 S − 1 P n P S − 1 d =1 φ k dn w v dn ≤ P n φ k S n w v S n , ≤ max φ k S n , w v S n 1 S X n ( X k φ k S n )( X v w v S n ) ≤ N S , (8) since P k φ k S n = 1, and P v w v S n = 1. This sensitivit y accoun ts for the worst case in which all N S words in the minibatch are assigned to the same entry of ¯ s , i.e. they all hav e the same word t yp e v , and are hard-assigned to the same topic k in the v ariational distribution. In our practical implemen tation, w e impro ve the sensitivit y b y exploiting the fact that most typical sufficien t statistic matrix ¯ s giv en a minibatch (where the size of the matrix is the n um b er of topics b y the n um b er of w ords in the v o cabulary set) has a m uc h smaller norm than this w orst case. Sp ecifically , inspired b y [10], w e apply a norm clipping strategy , in which the matrix ¯ s is clipp ed (or pro jected) suc h that the F robenious norm of the matrix is b ounded by | ¯ s | ≤ a N S , for a user-sp ecified a ∈ (0 , 1]. F or eac h minibatc h, if this criterion is not satisfied, w e pro ject the exp ected sufficient statistics down to the required norm via ¯ s := a N S ¯ s | ¯ s | . (9) After this the pro cedure, the sensitivity of the entire matrix b ecomes a ∆ ¯ s (i.e., aN /S ), and we add noise on this scale to the clipp ed exp ected sufficien t statistics. W e set a = 0 . 1 in our exp eriments, whic h empirically resulted in clipping b eing applied to around 3 / 4 of the do cuments. The resulting algorithm is summarised in Algorithm 1. 4 Priv acy analysis of priv ate LD A W e use the Moments A c c ountant (MA) comp osition me tho d [10] for accounting for priv acy loss incurred b y successiv e iterations of an iterativ e mec hanism. W e choose this metho d as it pro vides tigh t priv acy b ounds (cf., [11]). The momen ts accountan t metho d is based on the concept of a privacy loss r andom variable , whic h allows us to consider the en tire sp ectrum of likelihoo d ratios P r ( M ( X )= o ) P r ( M ( X 0 )= o ) induced b y a priv acy mechanism M . Sp ecifically , the priv acy loss random v ariable corresp onding to a mec hanism M , datasets X and X 0 , and an auxiliary parameter w is a random v ariable defined as follo ws: L M ( X , X 0 , w ) := log P r ( M ( X ,w )= o ) P r ( M ( X 0 ,w )= o ) , with lik eliho o d P r ( M ( X , w ) = o ) , where o lies in the range of M . Observe that if M is ( , 0)-differen tially priv ate, then the absolute v alue of L M ( X , X 0 , w ) is at most with probabilit y 1. The moments accountan t metho d exploits prop erties of this priv acy loss random v ariable to account for the priv acy loss incurred b y applying mechanisms M 1 , . . . , M t successiv ely to a dataset X ; this is 4 Algorithm 1 Priv ate LDA Require: Data D . Define D (do cumen ts), V (v o cabulary), K (num b er of topics). Define ρ t = ( τ 0 + t ) − κ , mini-batc h size S , h yp erparameters α, η , σ 2 , and a Ensure: Priv atised exp ected natural parameters h log β k i q ( β k ) and sufficien t statistics ˜ ¯ s . Compute the sensitivity of the exp ected sufficient statistics given in Eq. 8. for t = 1 , . . . , J do (1) E-step : Given exp ected natural parameters h log β k i q ( β k ) for d = 1 , . . . , S do Compute q ( z k dn ) parameterised by φ k dn ∝ exp( h log β k i q ( β k ) > w dn + h log θ k d i q ( θ d ) ). Compute q ( θ d ) parameterised by γ d = α 1 K + P N n =1 h z dn i q ( z dn ) . end for Compute the exp ected sufficient statistics ¯ s v k = 1 S P d P n φ k dn w v dn . if | ¯ s | > aN/S then ¯ s := a N S ¯ s | ¯ s | end if Output the p erturb ed exp ected sufficient statistics ˜ ¯ s v k = ¯ s + Y v k , where Y v k is Gaussian noise giv en in Eq. 7, but using sensitivity aN /S . Clip negativ e entries of ˜ ¯ s to 0. Up date the log-moment functions. (2) M-step : Given p erturb ed exp ected sufficient statistics ˜ ¯ s k , Compute q ( β k ) parameterised by λ ( t ) k = η 1 V + D ˜ ¯ s k . Set λ ( t ) ← [ (1 − ρ t ) λ ( t − 1) + ρ t λ ( t ) . Output exp ected natural parameters h log β k i q ( β k ) . end for done b y b ounding prop erties of the log of the momen t generating function of the priv acy loss random v ariable. Sp ecifically , the log moment function α M t of a mechanism M t is defined as: α M t ( λ ) = sup X , X 0 ,w log E [exp( λL M t ( X , X 0 , w ))] , (10) where X and X 0 are datasets that differ in the priv ate v alue of a single p erson. [10] sho ws that if M is the combination of mec hanisms ( M 1 , . . . , M k ) where each mechanism addes indep endent noise, then, its log moment generating function α M has the prop erty that: α M ( λ ) ≤ k X t =1 α M t ( λ ) (11) Additionally , given a log moment function α M , the corresp onding mechanism M satisfies a range of priv acy parameters ( , δ ) connected by the following equation: δ = min λ exp( α M ( λ ) − λ ) (12) These prop erties immediately suggest a pro cedure for tracking priv acy loss incurred by a com bination of mechanisms M 1 , . . . , M k on a dataset. F or each mec hanism M t , first compute the log moment function α M t ; for simple mechanisms such as the Gaussian mechanism this can b e done by simple algebra. Next, compute α M for the combination M = ( M 1 , . . . , M k ) from (11), and finally , recov er the priv acy parameters of M using (12) by either finding the b est for a target δ or the b est δ for a target . In some sp ecial cases such as comp osition of k Gaussian mechanisms, the log moment functions can b e calculated in closed form; the more common case is when closed forms are not a v ailable, and then a grid search may b e p erformed ov er λ . 5 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 Epsilon 0 500 1000 1500 2000 2500 3000 Perplexity Strong composition S=5K Strong composition S=10K Strong composition S=20K Moments accountant S=5K Moments accountant S=10K Moments accountant S=20K Non-private S=20K Non-private S=10K Non-private S=5K Outside MA theorem conditions Figure 1: Epsilon v ersus p erplexity , v arying σ and S , Wikip edia data, one ep o c h. The parameters for the t w o data p oints indicated b y the pink circles do not satisfy the conditions of the momen ts accoun tan t comp osition theorem, so those v alues are not formally prov ed. In Algorithm 1, observe that iteration t of the algorithm subsamples a ν = S/D fraction of the dataset, computes the sufficient statistics based on this subsample, and p erturbs it using the Gaussian mec hanism with v ariance σ 2 I d . T o simplify the priv acy calculations, we assume that each example in the dataset is included in a minibatc h according to an indep endent coin flip with probability ν . F rom Prop osition 1.6 in [12] along with simple algebra, the log moment function of the Gaussian Mec hanism M applied to a query with L 2 -sensitivit y ∆ is α M ( λ ) = λ ( λ +1)∆ 2 2 σ 2 . T o compute the log moment function for the subsampled Gaussian Mec hanism, we follow [10]. Let β 0 and β 1 b e the densities N (0 , ( σ / ∆) 2 ) and N (1 , ( σ / ∆) 2 ), and let β = (1 − ν ) β 0 + ν β 1 b e the mixture density; then, the log moment function at λ is max log( E 1 , E 2 ) where E 1 = E z ∼ β 0 [( β 0 ( z ) /β ( z )) λ ] and E 2 = E z ∼ β [( β ( z ) /β 0 ( z )) λ ]. E 1 and E 2 can b e n umerically calculated for any λ , and we main tain the log momen ts ov er a grid of λ v alues. Note that our algorithms are run for a prespecified n umber of iterations, and with a presp ecified σ ; this ensures a certain level of ( , δ ) guarantee in the released exp ected sufficient statistics from Algorithm 1. 5 Exp erimen ts using Wikip edia data W e do wnloaded a random D = 400 , 000 do cuments from Wikip edia to test our algorithm. W e used 50 topics and a vocabulary set of approximately 8000 terms. The algorithm w as run for one ep o ch in eac h exp eriment. W e compared our moments accountan t approach with a baseline metho d using the str ong c omp o- sition (Theorem 3.20 of [1]), resulting from the max divergence of the priv acy loss random v ari- able b eing b ounded b y a total budget including a slack v ariable δ , whic h yields ( J 0 ( e 0 − 1) + p 2 J log (1 /δ 00 ) 0 , δ 00 + J δ 0 )-DP . 6 As our ev aluation metric, we compute an upp er b ound on the perplexity on held-out do cumen ts. P erplexit y is an information-theoretic measure of the predictiv e p erformance of probabilistic mo dels whic h is commonly used in the context of language mo deling [13]. The p erplexity of a probabilistic mo del p model ( x ) on a test set of N data p oin ts x i (e.g. words in a corpus) is defined as p erplexit y( D test , λ ) ≤ exp − X i h log p ( n test , θ i , z i | λ ) i q ( θ i , z i ) − h log q ( θ , z ) i q ( θ , z ) ! / X i,n n test i,n , where n test i is a v ector of w ord counts for the i th do cument, n test = { n test i } I i =1 . In the ab ov e, we use the λ that was calculated during training. W e compute the p osteriors o v er z and θ by p erforming the first step in our algorithm using the test data and the p erturb ed sufficient statistics we obtain during training. W e adapted the p ython implementation b y the authors of [14] for our exp erimen ts. Figure 1 shows the trade-off b et w een and p er-word p erplexit y on the Wikip edia dataset for the dif- feren t metho ds under a v ariet y of conditions, in which we v aried the v alue of σ ∈ { 1 . 0 , 1 . 1 , 1 . 24 , 1 . 5 , 2 } and the minibatch size S ∈ { 5 , 000 , 10 , 000 , 20 , 000 } . W e found that the moments accountan t com- p osition substantially outp erformed strong comp osition in eac h of these settings. Here, we used relativ ely large minibatches, which were necessary to control the signal-to-noise ratio in order to obtain reasonable results for priv ate LDA. Larger minibatc hes th us had low er p erplexity . How ever, due to its impact on the subsampling rate, increasing S comes at the cost of a higher for a fixed n um b er of do cumen ts pro cessed (in our case, one ep o c h). The minibatch size S is limited b y the conditions of the moments accountan t comp osition theorem shown by [10], with the largest v alid v alue b eing obtained at around S ≈ 20 , 000 for the small noise regime where σ ≈ 1. In T able 1, for eac h metho d, w e show the top 10 w ords in terms of assigned probabilities for 3 example topics. Non-priv ate LD A results in the most coherent words among all the metho ds. F or the priv ate LD A mo dels with a total priv acy budget = 2 . 44 ( S = 20 , 000 , σ = 1 . 24), as w e mov e from moments accoun tan t to strong comp osition, the amoun t of noise added gets larger, and the topics b ecome less coheren t. W e als o observe that the probability mass assigned to the most probable w ords decreases with the noise, and thus strong comp osition ga v e less probability to the top w ords compared to the other metho ds. 6 Conclusion W e ha v e developed a practical priv acy-preserving topic mo deling algorithm whic h outputs accurate and priv atized expected sufficien t statistics and exp ected natural parameters. Our approac h uses the moments accountan t analysis com bined with the priv acy amplification effect due to subsampling of data, which significantly decrease the amoun t of additive noise for the same exp ected priv acy guaran tee compared to the standard analysis. 7 T able 1: P osterior topics from priv ate ( = 2 . 44) and non-priv ate LD A Non-priv ate Momen ts Acc. Strong Comp. topic 33: topic 33: topic 33: german 0.0244 function 0.0019 resolution 0.0003 system 0.0160 domain 0.0017 north w ard 0.0003 group 0.0109 german 0.0011 deeply 0.0003 based 0.0089 windo ws 0.0011 messages 0.0003 science 0.0077 soft ware 0.0010 researc h 0.0003 systems 0.0076 band 0.0007 dark 0.0003 computer 0.0072 mir 0.0006 riv er 0.0003 soft w are 0.0071 pro duct 0.0006 sup erstition 0.0003 space 0.0061 resolution 0.0006 don 0.0003 p o wer 0.0060 iden tity 0.0005 found 0.0003 topic 35: topic 35: topic 35: station 0.0846 station 0.0318 station 0.0118 line 0.0508 line 0.0195 line 0.0063 railw a y 0.0393 railw a y 0.0149 railwa y 0.0055 op ened 0.0230 op ened 0.0074 op ened 0.0022 services 0.0187 services 0.0064 services 0.0015 lo cated 0.0163 closed 0.0056 stations 0.0015 closed 0.0159 code 0.0054 closed 0.0014 o wned 0.0158 coun try 0.0052 section 0.0013 stations 0.0122 lo cated 0.0051 platform 0.0012 platform 0.0109 stations 0.0051 company 0.0010 topic 37: topic 37: topic 37: b orn 0.1976 b orn 0.0139 b orn 0.0007 american 0.0650 p eople 0.0096 american 0.0006 p eople 0.0572 notable 0.0092 street 0.0006 summer 0.0484 american 0.0075 c harles 0.0004 notable 0.0447 name 0.0031 said 0.0004 canadian 0.0200 moun tain 0.0026 ev en ts 0.0004 ev en t 0.0170 japanese 0.0025 people 0.0003 writer 0.0141 fort 0.0025 station 0.0003 dutc h 0.0131 c haracter 0.0019 written 0.0003 actor 0.0121 actor 0.0014 p oin t 0.0003 References [1] Cyn thia Dwork and Aaron Roth. The algorithmic foundations of differential priv acy . F ound. T r ends The or. Comput. Sci. , 9:211–407, August 2014. [2] Cyn thia Dwork, F rank McSherry , Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in priv ate data analysis. In The ory of Crypto gr aphy Confer enc e , pages 265–284. Springer, 2006. [3] M. J. Beal. V ariational A lgorithms for Appr oximate Bayesian Infer enc e . PhD thesis, Gatsby Unit, Univ ersity College London, 2003. [4] Mijung Park, James R. F oulds, Kamalik a Chaudh uri, and Max W elling. DP-EM: Differen tially priv ate exp ectation maximization. In Pr o c e e dings of the 20th International Confer enc e on Artificial Intel ligenc e and Statistics (AIST A TS) , 2017. 8 [5] Zuhe Zhang, Benjamin Rubinstein, and Christos Dimitrak akis. On the differen tial priv acy of Ba yesian inference. In Pr o c e e dings of the Thirtieth AAAI Confer enc e on Artificial Intel ligenc e (AAAI) , 2016. [6] Christos Dimitrak akis, Blaine Nelson, Aik aterini Mitrokotsa, and Benjamin I.P . Rubinstein. Robust and priv ate Bay esian inference. In Algorithmic L e arning The ory (AL T) , pages 291–305. Springer, 2014. [7] James R. F oulds, Joseph Geumlek, Max W elling, and Kamalik a Chaudhuri. On the theory and practice of priv acy-preserving Bay esian data analysis. In Pr o c e e dings of the 32nd Confer enc e on Unc ertainty in A rtificial Intel ligenc e (UAI) , 2016. [8] Gilles Barthe, Gian Pietro F arina, Marco Gab oardi, Emilio Jes ´ us Gallego Arias, Andy Gordon, Justin Hsu, and Pierre-Yves Strub. Differen tially priv ate Bay esian programming. In Pr o c e e dings of the 2016 A CM SIGSAC Confer enc e on Computer and Communic ations Se curity , pages 68–79. ACM, 2016. [9] Da vid M. Blei, Andrew Y. Ng, and Michael I. Jordan. Laten t Dirichlet allo cation. Journal of Machine L e arning R ese ar ch , 3(Jan):993–1022, 2003. [10] M. Abadi, A. Chu, I. Go o dfello w, H. Brendan McMahan, I. Mironov, K. T alw ar, and L. Zhang. Deep learning with differential priv acy. In Pr o c e e dings of the 2016 ACM SIGSA C Confer enc e on Computer and Communic ations Se curity , pages 308–318. July 2016. [11] Cyn thia Dwork, Guy N Roth blum, and Salil V adhan. Bo osting and differential priv acy . In F oundations of Computer Scienc e (FOCS), 2010 51st Annual IEEE Symp osium on , pages 51–60. IEEE, 2010. [12] Mark Bun and Thomas Steinke. Concentrated differential priv acy: Simplifications, extensions, and lo wer b ounds. In The ory of Crypto gr aphy Confer enc e , pages 635–658. Springer, 2016. [13] F red Jelinek, Rob ert L Mercer, Lalit R Bahl, and James K Baker. Perplexit y–a measure of the difficulty of sp eec h recognition tasks. The Journal of the A c oustic al So ciety of Americ a , 62(S1):S63–S63, 1977. [14] Matthew Hoffman, F rancis R. Bach, and David M. Blei. Online learning for latent Dirichlet allo cation. In J. D. Lafferty , C. K. I. Williams, J. Shaw e-T a ylor, R. S. Zemel, and A. Culotta, editors, A dvanc es in Neur al Information Pr o c essing Systems 23 , pages 856–864. Curran Asso ciates, Inc., 2010. 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment