The Architecture of Mr. DLibs Scientific Recommender-System API
Recommender systems in academia are not widely available. This may be in part due to the difficulty and cost of developing and maintaining recommender systems. Many operators of academic products such as digital libraries and reference managers avoid this effort, although a recommender system could provide significant benefits to their users. In this paper, we introduce Mr. DLib’s “Recommendations as-a-Service” (RaaS) API that allows operators of academic products to easily integrate a scientific recommender system into their products. Mr. DLib generates recommendations for research articles but in the future, recommendations may include call for papers, grants, etc. Operators of academic products can request recommendations from Mr. DLib and display these recommendations to their users. Mr. DLib can be integrated in just a few hours or days; creating an equivalent recommender system from scratch would require several months for an academic operator. Mr. DLib has been used by GESIS Sowiport and by the reference manager JabRef. Mr. DLib is open source and its goal is to facilitate the application of, and research on, scientific recommender systems. In this paper, we present the motivation for Mr. DLib, the architecture and details about the effectiveness. Mr. DLib has delivered 94m recommendations over a span of two years with an average click-through rate of 0.12%.
💡 Research Summary
The paper presents Mr. DLib, a “Recommendations as‑a‑Service” (RaaS) platform designed to lower the barrier for academic operators—such as digital libraries and reference‑manager developers—to integrate scientific article recommendation functionality into their products. The authors begin by outlining the scarcity of recommender systems in academia, attributing it largely to the high cost and technical complexity of building and maintaining such systems. To address this gap, Mr. DLib offers a RESTful API that can be embedded within an external product in a matter of hours or days, whereas a comparable in‑house solution would typically require several months of development and ongoing maintenance.
The system architecture follows a four‑layer modular design. The outermost layer is an API gateway that receives HTTP GET/POST requests containing JSON parameters (e.g., user ID, source document ID, number of recommendations). Requests are authenticated via token‑based mechanisms, validated, and then dispatched asynchronously through a message bus (Kafka) to the recommendation core. The core currently implements a hybrid approach that combines content‑based (CB) and collaborative‑filtering (CF) techniques. CB uses TF‑IDF and BM25 weighting on titles, abstracts, and keywords, generating cosine‑similarity scores. CF relies on implicit feedback (clicks, views) stored in a ClickHouse data warehouse and applies Alternating Least Squares (ALS) matrix factorization. The two score streams are merged using a dynamically weighted average; the weights are continuously tuned based on live A/B‑test outcomes.
Data storage is split across PostgreSQL for structured metadata, Elasticsearch for full‑text indexing, and ClickHouse for high‑throughput event logs. A Spark‑Streaming pipeline ingests real‑time feedback, updates user‑item interaction matrices, and triggers nightly model retraining. To meet low‑latency requirements, a Redis cache and CDN layer serve popular recommendation lists, achieving sub‑50 ms response times for the majority of requests.
Operational monitoring leverages Prometheus and Grafana dashboards that track request volume, error rates, latency, and click‑through rate (CTR). Offline evaluation metrics such as Precision@10 and MAP are computed on held‑out data, while online experiments run continuously to validate algorithmic changes. Over a two‑year period, Mr. DLib delivered 94 million recommendations with an average CTR of 0.12 %. Although modest by commercial standards, this figure is meaningful in the scholarly context where users often browse rather than click, and the ultimate goal is to increase article reads and citations over the longer term.
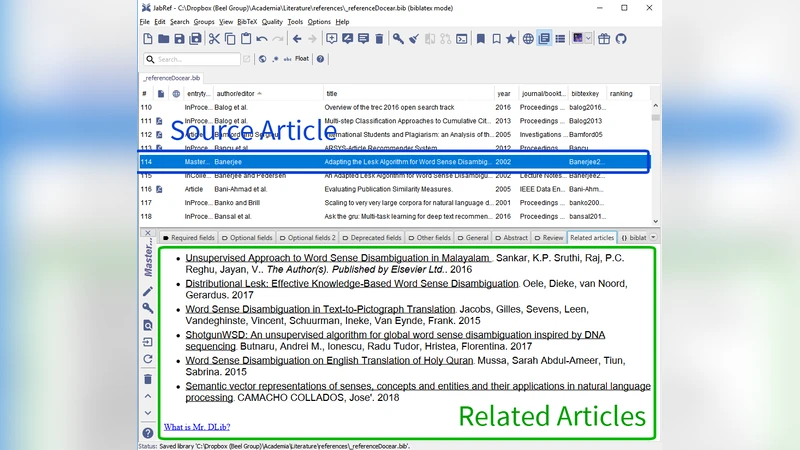
Two real‑world integrations are described: GESIS Sowiport, a German social‑science portal, and JabRef, an open‑source reference manager. Both services incorporated the API with minimal engineering effort (approximately two days for Sowiport and four hours for JabRef) and reported positive user engagement. Security provisions include HTTPS transport, API‑key authentication, IP whitelisting, and GDPR/CCPA‑compliant data anonymization. An SLA targeting 99.9 % availability is defined, and automatic failover mechanisms are in place.
Mr. DLib is released under the permissive MIT license, encouraging the community to contribute new algorithms (e.g., graph‑neural‑network embeddings) or extend the recommendation domain beyond articles to calls for papers, grants, or datasets. The architecture is deliberately abstracted to support multi‑domain extensions without major refactoring.
In conclusion, the authors argue that Mr. DLib provides a practical, research‑friendly solution that enables academic product developers to quickly adopt state‑of‑the‑art recommendation technology. Future work will explore deeper learning‑based content representations, richer user profiling, and longitudinal studies linking recommendations to citation impact.
Comments & Academic Discussion
Loading comments...
Leave a Comment