Boosting in Image Quality Assessment
In this paper, we analyze the effect of boosting in image quality assessment through multi-method fusion. Existing multi-method studies focus on proposing a single quality estimator. On the contrary, we investigate the generalizability of multi-method fusion as a framework. In addition to support vector machines that are commonly used in the multi-method fusion, we propose using neural networks in the boosting. To span different types of image quality assessment algorithms, we use quality estimators based on fidelity, perceptually-extended fidelity, structural similarity, spectral similarity, color, and learning. In the experiments, we perform k-fold cross validation using the LIVE, the multiply distorted LIVE, and the TID 2013 databases and the performance of image quality assessment algorithms are measured via accuracy-, linearity-, and ranking-based metrics. Based on the experiments, we show that boosting methods generally improve the performance of image quality assessment and the level of improvement depends on the type of the boosting algorithm. Our experimental results also indicate that boosting the worst performing quality estimator with two or more additional methods leads to statistically significant performance enhancements independent of the boosting technique and neural network-based boosting outperforms support vector machine-based boosting when two or more methods are fused.
💡 Research Summary
The paper investigates the impact of boosting—specifically, multi‑method fusion—on image quality assessment (IQA). While prior works on multi‑method IQA typically propose a single hybrid estimator, this study treats fusion as a general framework and evaluates its generalizability across a broad set of quality metrics and databases.
Eleven representative IQA algorithms are selected, covering five conceptual groups: (1) fidelity‑based (MSE, PSNR), (2) perceptually‑extended fidelity (PSNR‑HA, PSNR‑HMA, PSNR‑HVS‑M), (3) structural similarity (SSIM, MS‑SSIM, CW‑SSIM, IW‑SSIM, SR‑SIM, plus a spectral similarity measure), (4) color‑based (FSIMc, PerSIM), and (5) learning‑based (UNIQUE, an unsupervised sparse‑representation model). These span traditional pixel‑wise error, human‑visual‑system‑informed extensions, multi‑scale and complex‑domain similarity, chroma‑aware metrics, and data‑driven approaches.
Two off‑the‑shelf regression models are employed for fusion: a linear‑kernel Support Vector Machine (SVM) using Sequential Minimal Optimization, and a shallow feed‑forward neural network (NN) with a single hidden layer whose neuron count equals the number of IQA algorithms. Both models use mean‑square error as the loss function; the NN is trained with the Levenberg‑Marquardt algorithm. No elaborate hyper‑parameter tuning or deep architectures are introduced, emphasizing the pure effect of the fusion strategy itself.
The experimental protocol uses three widely accepted IQA databases: LIVE, MULTI‑LIVE (multiply distorted), and TID2013. These datasets collectively contain 7 distortion categories (compression, noise, communication, blur, color, global, local) and over 3,000 distorted images. A 5‑fold cross‑validation scheme is repeated 100 times, yielding 2,200 runs for each baseline method and 200 runs for each boosted configuration. Before performance evaluation, a non‑linear mapping (a five‑parameter logistic function) aligns predicted scores with subjective mean opinion scores, following standard practice.
Four performance metrics are reported: (i) Root Mean Square Error (RMSE) for absolute accuracy, (ii) Pearson Linear Correlation Coefficient (PLCC) for linearity, (iii) Spearman Rank‑Order Correlation Coefficient (SROCC) for monotonic ranking, and (iv) statistical significance testing based on ITU‑T P.1401 to assess whether differences between correlation values are meaningful.
Key findings:
-
Baseline performance – Across the three databases, the best single methods differ. PSNR‑HMA leads on LIVE, SR‑SIM on MULTI‑LIVE, and the learning‑based UNIQUE on TID2013, achieving the lowest RMSE and highest PLCC/SROCC in their respective settings.
-
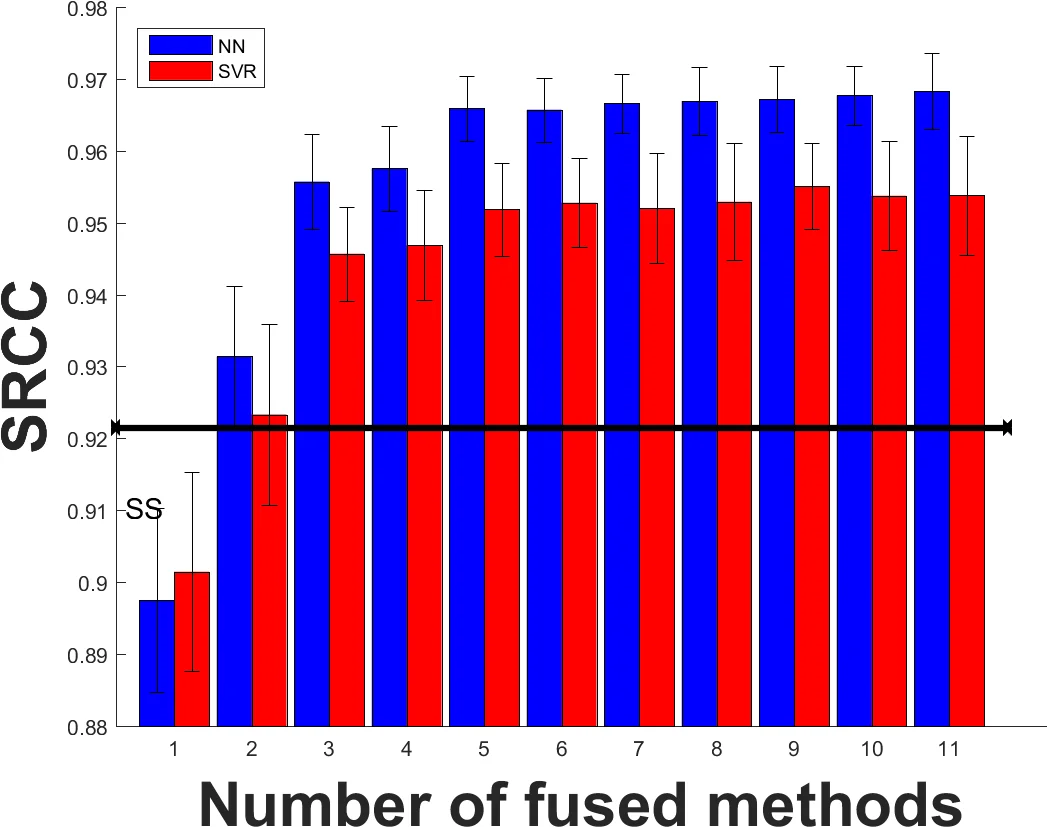
Effect of boosting – Fusion consistently improves all three metrics compared with any individual estimator. The magnitude of improvement depends on the fusion algorithm and the number of fused methods. Notably, when two or more methods are combined, the NN‑based booster outperforms the SVM‑based booster in both PLCC and SROCC.
-
Boosting the weakest estimator – Adding two or more complementary methods to the poorest performing estimator yields statistically significant gains, regardless of whether the booster is an SVM or NN. This demonstrates that even “weak learners” contain useful, non‑redundant information that can be harvested through fusion.
-
Method‑specific observations – Neural‑network regression particularly benefits structural (SSIM family), spectral (SR‑SIM), and learning‑based (UNIQUE) metrics, sometimes turning them into the top‑performing methods after fusion (e.g., IW‑SSIM becomes best on LIVE and MULTI‑LIVE in RMSE/PLCC after NN fusion).
The authors conclude that multi‑method boosting is a robust, database‑agnostic strategy for enhancing IQA. Importantly, the study shows that sophisticated deep‑learning pipelines are not a prerequisite for achieving strong performance; a modest NN architecture can already surpass traditional SVM fusion. This has practical implications for real‑time or resource‑constrained applications (e.g., streaming, mobile photography) where computational budget is limited but high‑fidelity quality prediction is still required.
Overall, the paper provides a thorough empirical validation of boosting in IQA, establishes neural networks as a superior fusion engine for most scenarios, and underscores the value of integrating diverse quality cues rather than relying on a single handcrafted metric.
Comments & Academic Discussion
Loading comments...
Leave a Comment