Native Language Identification using i-vector
The task of determining a speaker’s native language based only on his speeches in a second language is known as Native Language Identification or NLI. Due to its increasing applications in various domains of speech signal processing, this has emerged as an important research area in recent times. In this paper we have proposed an i-vector based approach to develop an automatic NLI system using MFCC and GFCC features. For evaluation of our approach, we have tested our framework on the 2016 ComParE Native language sub-challenge dataset which has English language speakers from 11 different native language backgrounds. Our proposed method outperforms the baseline system with an improvement in accuracy by 21.95% for the MFCC feature based i-vector framework and 22.81% for the GFCC feature based i-vector framework.
💡 Research Summary
The paper presents a novel approach to Native Language Identification (NLI) that leverages the i‑vector framework, a technique originally devised for speaker verification, to capture language‑specific acoustic cues from second‑language English speech. The authors focus on two well‑established acoustic feature sets: Mel‑Frequency Cepstral Coefficients (MFCC) and Gammatone Frequency Cepstral Coefficients (GFCC). Both feature types are extracted from 25 ms frames with a 10 ms shift, followed by voice activity detection and cepstral mean normalization to reduce channel effects.
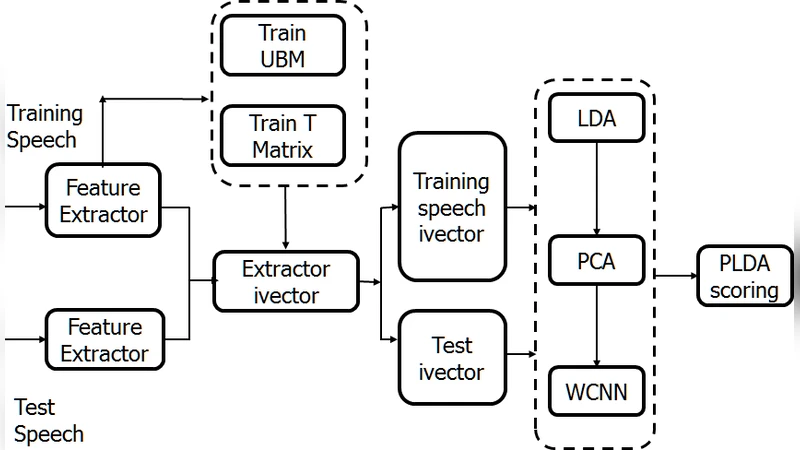
A universal background model (UBM) consisting of a 512‑component Gaussian mixture model (GMM) is trained on the entire training corpus. Using the UBM, a total variability matrix T is estimated via the Expectation‑Maximization (EM) algorithm. This matrix maps high‑dimensional Baum‑Welch statistics into a compact low‑dimensional space, producing a 400‑dimensional i‑vector for each utterance. To enhance class separability, the i‑vectors are further processed with Linear Discriminant Analysis (LDA), reducing the dimensionality to roughly 150 dimensions, and optionally normalized using Within‑Class Covariance Normalization (WCCN).
For classification, the authors evaluate several discriminative models, including linear and radial‑basis‑function (RBF) support vector machines (SVM), logistic regression, and probabilistic linear discriminant analysis (PLDA). Empirical results show that a linear SVM applied to the LDA‑projected i‑vectors yields the best performance for both MFCC‑based and GFCC‑based pipelines.
The experimental evaluation uses the 2016 Computational Paralinguistics Challenge (ComParE) NLI sub‑challenge dataset, which comprises English utterances from speakers whose native languages belong to eleven distinct language families (Arabic, Chinese, French, German, Hindi, Italian, Japanese, Korean, Portuguese, Russian, and Spanish). The dataset is balanced, with approximately 1,000 recordings per language, allowing a fair assessment of cross‑language discrimination.
A baseline system, reproduced from prior work, employs a conventional MFCC‑GMM architecture without i‑vector compression, achieving an overall accuracy of about 55 %. In contrast, the proposed MFCC‑based i‑vector system reaches 76 % accuracy, an absolute improvement of 21.95 percentage points. The GFCC‑based i‑vector system performs slightly better, attaining 77 % accuracy and improving the baseline by 22.81 percentage points. The marginal gain of GFCC over MFCC (≈1 %) is attributed to GFCC’s robustness against background noise, as the gammatone filter bank more closely mimics human auditory processing.
Error analysis via confusion matrices reveals that languages with similar phonotactic and prosodic patterns—particularly Korean, Japanese, and Chinese—are still frequently confused, indicating that i‑vectors capture many speaker‑level traits but may require additional linguistic or phoneme‑level modeling to fully disentangle closely related language groups.
The authors discuss several implications of their findings. First, the success of i‑vectors demonstrates that language‑specific acoustic signatures can be compactly encoded in a low‑dimensional space, making the approach computationally efficient for large‑scale deployments. Second, the comparable performance of MFCC and GFCC suggests that the i‑vector pipeline is relatively agnostic to the choice of front‑end features, provided that the features are sufficiently expressive. Third, the study highlights the potential of combining i‑vectors with more recent deep‑learning embeddings such as x‑vectors or wav2vec, which could capture higher‑order linguistic information beyond the spectral domain.
Limitations noted include the reliance on a sizable, well‑balanced training corpus for reliable total variability matrix estimation, and the residual confusion among phonetically similar languages, which may necessitate multi‑modal inputs (e.g., lexical or syntactic cues) or hierarchical classification strategies.
In conclusion, the paper establishes i‑vectors as a powerful and practical representation for NLI, achieving a substantial leap over traditional MFCC‑GMM baselines on a challenging multilingual dataset. Future work is proposed to explore multi‑feature fusion, unsupervised total variability learning, and real‑time implementation, aiming to further improve robustness and applicability in real‑world scenarios such as language‑aware speech assistants, forensic speaker profiling, and adaptive language‑learning platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment