Analysis of Multilingual Sequence-to-Sequence speech recognition systems
This paper investigates the applications of various multilingual approaches developed in conventional hidden Markov model (HMM) systems to sequence-to-sequence (seq2seq) automatic speech recognition (ASR). On a set composed of Babel data, we first sh…
Authors: Martin Karafiat, Murali Karthick Baskar, Shinji Watanabe
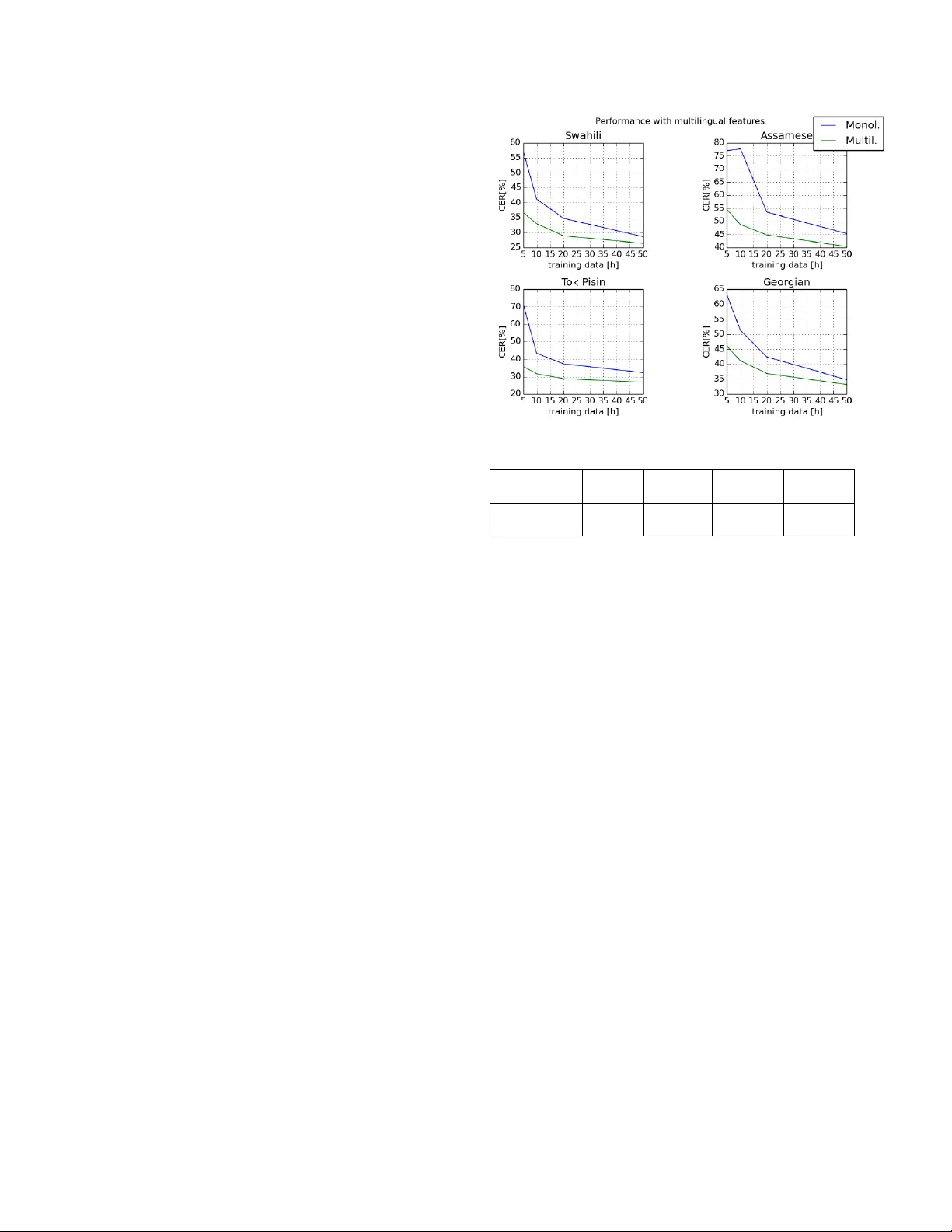
ANAL YSIS OF MUL TILINGU AL SEQUENCE-T O-SEQUENCE SPEECH RECOGNITION SYSTEMS Martin Karafi ´ at 1 , Murali Karthic k Baskar 1 , Shinji W atanabe 2 , T akaaki Hori 3 Matthew W iesner 2 and J an “Honza” ˇ Cernock ´ y 1 Brno Uni versity of T echnology 1 , John Hopkins Uni versity 2 Mitsubishi Electric Research Laboratories (MERL) 3 ABSTRA CT This paper in vestigates the applications of v arious multilingual ap- proaches de veloped in con ventional hidden Markov model (HMM) systems to sequence-to-sequence (seq2seq) automatic speech recog- nition (ASR). On a set composed of Babel data, we first sho w the ef- fectiv eness of multi-lingual training with stacked bottle-neck (SBN) features. Then we explore various architectures and training strate- gies of multi-lingual seq2seq models based on CTC-attention net- works including combinations of output layer, CTC and/or atten- tion component re-training. W e also inv estigate the effectiv eness of language-transfer learning in a very low resource scenario when the target language is not included in the original multi-lingual training data. Interestingly , we found multilingual features superior to mul- tilingual models, and this finding suggests that we can efficiently combine the benefits of the HMM system with the seq2seq system through these multilingual feature techniques. Index T erms — sequence-to-sequence, CTC, multilingual train- ing, language-transfer , ASR. 1. INTR ODUCTION The sequence-to-sequence (seq2seq) model proposed in [1, 2, 3] is a neural network (NN) architecture for performing sequence clas- sification. Later , it w as also adopted to perform speech recogni- tion [4, 5, 6]. The model allows to integrate the main blocks of ASR (acoustic model, alignment model and language model) into a single neural network architecture. The recent ASR advancements in connectionist temporal classification (CTC) [6, 5] and attention [4, 7] based approaches hav e generated significant interest in speech community to use seq2seq models. Ho wever , outperforming con- ventional hybrid RNN/DNN-HMM models with seq2seq requires a huge amount of data [8]. Intuitiv ely , this is due to the range of roles this model needs to perform: alignment and language model- ing along with acoustic to character label mapping. The work reported here was carried out during the 2018 Jelinek Memo- rial Summer W orkshop on Speech and Language T echnologies, supported by Johns Hopkins Univ ersity via gifts from Microsoft, Amazon, Google, Face- book, and MERL/Mitsubishi Electric. It was also supported by Czech Min- istry of Education, Y outh and Sports from the National Programme of Sus- tainability (NPU II) project ”IT4Innov ations excellence in science - LQ1602” and by the Of fice of the Director of National Intelligence (ODNI), Intelli- gence Advanced Research Projects Activity (IARP A) MA TERIAL program, via Air Force Research Laboratory (AFRL) contract # F A8650-17-C-9118. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, ei- ther expressed or implied, of ODNI, IARP A, AFRL or the U.S. Go vernment. Multilingual approaches have been used in hybrid RNN/DNN- HMM systems for tackling the problem of lo w-resource data. These include language adapti ve training and shared layer retraining [9]. Parameter sharing in vestigated in our pre vious work [10] seems to be the most beneficial. Existing multilingual approaches for seq2seq modeling mainly focus on CTC . A multilingual CTC proposed in [11] uses a univ ersal phone set, FST decoder and language model. The authors also use a linear hidden unit contribution (LHUC) [12] technique to rescale the hidden unit outputs for each language as a way to adapt to a particular language. Another work [13] on multilingual CTC shows the importance of language adaptive vectors as auxiliary input to the encoder in multilingual CTC model. The decoder used here is based on simple greedy search of applying ar g max on every time frame. An extensi ve analysis of multilingual CTC performance with limited data is performed in [14]. Here, the authors use a word lev el FST decoder integrated with CTC during decoding. On a similar front, attention models are explored within a mul- tilingual setup in [15, 16], where an attempt was made to build an attention-based seq2seq model from multiple languages. The data is just pulled together assuming the target languages are seen during the training. Although our prior study [17] performs a preliminary in vestigation of transfer learning techniques to address the unseen languages during training, this is not an intensi ve study of covering various multi-lingual techniques. In this paper , we explore the multilingual training approaches [18, 19] in hybrid RNN/DNN-HMMs and we incorporate them into the seq2seq models. In our recent work [19], we showed the multi- lingual acoustic models (BLSTM particularly) to be superior to multilingual acoustic features in RNN/DNN-HMM systems. Con- sequently , similar experiments are performed in this paper on a sequence-to-sequence scheme. The main moti vation and contribution behind this work is as fol- lows: • T o incorporate the existing multilingual approaches in a joint CTC-attention [20] framew ork. • T o compare v arious multilingual approaches: multilingual features, model architectures, and transfer learning. 2. SEQUENCE-T O-SEQUENCE MODEL In this work, we use the attention based approach [2] as it provides an ef fectiv e methodology to perform sequence-to-sequence training. Considering the limitations of attention in performing monotonic alignment [21, 22], we choose to use CTC loss function to aid the attention mechanism in both training and decoding. Let X = ( x t | t = 1 , . . . , T ) be a T -length speech feature se- quence and C = ( c l | l = 1 , . . . , L ) be an L -length grapheme se- quence. A multi-objecti ve learning frame work L mol proposed in [20] is used in this work to unify attention loss p att ( C | X ) and CTC loss p ctc ( C | X ) with a linear interpolation weight λ , as follows: L mod = λ log p ctc ( C | X ) + (1 − λ ) log p ∗ att ( C | X ) . (1) The unified model benefits from both effecti ve sequence level train- ing and the monotonic afforded by the CTC loss. p att ( C | X ) represents the posterior probability of character label sequence C w .r .t input sequence X based on the attention approach, which is decomposed with the probabilistic chain rule, as follows: p ∗ att ( C | X ) ≈ L Y l =1 p ( c l | c ∗ 1 , ...., c ∗ l − 1 , X ) , (2) where c ∗ l denotes the ground truth history . Detailed explanation of the attention mechanism is giv en later . Similarly , p ctc ( C | X ) represents the CTC posterior probability: p ctc ( C | X ) ≈ X Z ∈Z ( C ) p ( Z | X ) , (3) where Z = ( z t | t = 1 , . . . , T ) is a CTC state sequence composed of the original grapheme set and the additional blank symbol. Z ( C ) is a set of all possible sequences giv en the character sequence C . The follo wing paragraphs explain the encoder , attention de- coder , CTC, and joint decoding used in our approach. Encoder In our approach, both C TC and attention use the same encoder func- tion: h t = Encoder ( X ) , (4) where h t is an encoder output state at t . As Encoder ( · ) , we use bidirectional LSTM (BLSTM). Attention Decoder: Location-aware attention mechanism [23] is used in this work. The output of location-aware attention is: a lt = LocationAttention { a l − 1 ,t 0 } T t 0 =1 , q l − 1 , h t . (5) Here, a lt acts as attention weight, q l − 1 denotes the decoder hidden state, and h t is the encoder output state defined in (4). The location- attention function is giv en by a conv olution and maps the attention weight of the previous label a l − 1 to a multi channel view f t for better representation: f t = K ∗ a l − 1 , (6) e lt = g T tanh( Lin ( q l − 1 ) + Lin ( h t ) + LinB ( f t )) , (7) a lt = Softmax ( { e lt } T t =1 ) (8) Here, (7) provides the unnormalized attention vectors computed with the learnable vector g , linear transformation Lin ( · ) , and af fine trans- formation LinB ( · ) . Normalized attention weight are obtained in (8) by a standard Softmax ( · ) operation. Finally , the context vector r l is obtained as a weighted sum of the encoder output states h t ov er all frames, with the attention weight: r l = T X t =1 a lt h t . (9) Usage Language Train Eval # of # spkrs. # hours # spkrs. # hours characters Train Cantonese 952 126.73 120 17.71 3302 Bengali 720 55.18 121 9.79 66 Pashto 959 70.26 121 9.95 49 T urkish 963 68.98 121 9.76 66 V ietnamese 954 78.62 120 10.9 131 Haitian 724 60.11 120 10.63 60 T amil 724 62.11 121 11.61 49 Kurdish 502 37.69 120 10.21 64 T okpisin 482 35.32 120 9.88 55 Georgian 490 45.35 120 12.30 35 T arget Assamese 720 54.35 120 9.58 66 Swahili 491 40.0 120 10.58 56 T able 1 . Details of the B ABEL data used for experiments. The decoder function is an LSTM layer which decodes the next char - acter output label c l from their previous label c l − 1 , hidden state of the decoder q l − 1 and attention output r l : p ( c l | c 1 , ...., c l − 1 , X ) = Decoder ( r l , q l − 1 , c l − 1 ) (10) This equation is incrementally applied to form p ∗ att in (2). Connectionist temporal classification (CTC): Unlike the attention approach, CTC does not use any specific de- coder netw ork. Instead, it in vokes two important components to per- form character level training and decoding: the first one is an RNN- based encoding module p ( Z | X ) . The second component contains a language model and state transition module. The CTC formalism is a special case [6] of hybrid DNN-HMM framework with the Bayes rule applied to obtain p ( C | X ) . Joint decoding: Once we ha ve both CTC and attention-based seq2seq models trained, both are jointly used for decoding as below: log p hyp ( c l | c 1 , ...., c l − 1 , X ) = α log p ctc ( c l | c 1 , ...., c l − 1 , X ) +(1 − α ) log p att ( c l | c 1 , ...., c l − 1 , X ) (11) Here log p hyp is a final score used during beam search. α controls the weight between attention and CTC models. α and multi-task learning weight λ in (1) are set differently in our e xperiments. 3. D A T A The experiments are conducted using the B ABEL speech corpus col- lected during the IARP A Babel program. The corpus is mainly com- posed of con versational telephone speech (CTS) but some scripted recordings and far field recordings are present as well. T able 1 presents the details of the languages used for training and e valuation in this work. W e decided to ev aluate also on training languages to see effect of multilingual training on training languages. Therefore, T ok Pisin, Georgian from “train” languages and Assamese, Swahili from “target” languages are tak en for evaluation. 4. SEQUENCE T O SEQUENCE MODEL SETUP The baseline systems are b uilt on 80-dimensional Mel-filter bank (fbank) features extracted from the speech samples using a sliding window of size 25 ms with 10ms stride. KALDI toolkit [24] is used to perform the feature processing. The “fbank” features are then fed to a seq2seq model with the following configuration: The Bi-RNN [25] models mentioned above uses an LSTM [26] cell followed by a projection layer (BLSTMP). In our experiments below , we use only a character-le vel seq2seq model based on CTC and attention, as mentioned above. Thus, in the following experi- ments, we will use character error rate (% CER) as a suitable mea- sure to analyze the model performance. All models are trained in ESPnet, end-to-end speech processing toolkit [27]. 5. MUL TILINGU AL FEA TURES Multilingual features are trained separately from seq2seq model ac- cording to a setup from our previous RNN/DNN-HMM work [19]. It allows us to easily combine traditional DNN techniques with the seq2seq model such as GMM based alignments for NN target es- timation, phoneme units and frame-lev el randomization. Multilin- gual features incorporate additional knowledge from non-target lan- guages into features which could better guide the seq2seq model. 5.1. Stacked Bottle-Neck featur e extraction The original idea of Stacked Bottle-Neck feature extraction is de- scribed in [28]. The scheme consists of two NN stages: The first one is reading short temporal context, its output is stacked, down- sampled, and fed into the second NN reading longer temporal infor- mation. The first stage bottle-neck NN input features are 24 log Mel fil- ter bank outputs concatenated with fundamental frequency features. Con versation-side based mean subtraction is applied and 11 consec- utiv e frames are stacked. Hamming window followed by discrete cosine transform (DCT) retaining 0 th to 5 th coefficients are applied on the time trajectory of each parameter resulting in 37 × 6=222 co- efficients at the first-stage NN input. In this work, the first-stage NN has 4 hidden layers with 1500 units in each except the bottle-neck (BN) one. The BN layer has 80 neurons. The neurons in the BN layer have linear activ ations as found optimal in [29]. 21 consecutiv e frames from the first-stage NN are stacked, down-sampled (each 5 frame is taken) and fed into the second-stage NN with an architecture similar to the first-stage NN, except of BN layer with only 30 neurons. Both neural networks were trained jointly as suggested in [29] in CNTK toolkit [30] with block- softmax final layer [31]. Context-independent phoneme states are used as the training targets for the feature-extraction NN, otherwise the size of the final layer would be prohibiti ve. Finally , BN outputs from the second stage NN are used as fea- tures for further experiments and will be noted as “Mult11-SBN”. 5.2. Results Figure 1 presents the performance curve of the seq2seq model with four “train” and “target” languages, as discussed in Section 3, by changing the amount of training data. It shows significant perfor- mance drop of baseline, “fbank” based, systems when the amount of training data is lowered. On the other hand, the multilingual features present: 1) signif- icantly smaller performance degradation than baseline “fbank” fea- Fig. 1 . Monolingual models trained on top of multilingual features. Features Swahili Amharic T ok Pisin Georgian %CER %CER %CER %CER FB ANK 28.6 45.3 32.2 34.8 Mult11-SBN 26.4 40.4 26.8 33.2 T able 2 . Monolingual models trained on top of multilingual features. tures on small amounts of training data. 2) consistent improvement on both train (seen) and target (unseen) languages where we only use train (seen) languages in feature extractor training data. 3) sig- nificant improvement even on the full training set, i.e., 1.6%-5.0% absolute (T able 2 summarizes the full training set results). 6. MUL TILINGU AL MODELS Next, we focus on the training of multilingual seq2seq models. As our models are character-based, the multilingual training dictionary is created by concatenation of all train languages, and the system is trained in same way as monolingual on concatenated data. 6.1. Direct decoding fr om multilingual NN As the multilingual net is trained to conv ert a sequence of input fea- tures into sequence of output characters, any language from training set or an unknown language with compatible set of characters can be directly decoded. Obviously , characters from wrong language can be generated as the system needs to performs also language identifi- cation (LID). Adding LID information as an additional feature, sim- ilarly to [32], complicates the system. Therefore, we experimented with “fine-tuning” of the system into the target language by running a fe w epochs only on desired language data. This is in strengthen- ing the target language characters, therefore it makes the system less prone to language- and character-set-mismatch errors. The first tw o ro ws of table 3 present significant performance degradation from monolingual to multilingual seq2seq models caused by wrong decision of output characters in about 20% of test utterances. Howe ver , no out-of-language characters are ob- served after “fine-tuning” and 1.5% and 4.7% impro vement o ver monolingual baseline is reached. Fig. 2 . Fine-tuning of multilingual NN on Swahili. As mentioned abov e, multilingual NN can be fine-tuned to the target language if character set is compatible with the training set. Figure 2 sho ws results on Swahili, which is not part of the training set. Similarly to experiments with multilingual features in Figure 1, the multilingual seq2seq systems are effecti ve especially on small amounts of data, b ut also beat baseline models on full ∼ 50h lan- guage set. 6.2. Language-T ransfer learning Language-T ransfer learning is necessary if target language charac- ters differ from train set ones. The whole process can be described in three steps: 1) randomly initialize output layer parameters, 2) train only new parameters and freeze the remaining ones 3) “fine-tune” the whole NN. V arious experiments are conducted on lev el of output parameters including output softmax (Out), the attention (Att), and CTC parts. T able 4 compares all combinations and clearly shows that retraining of output softmax only is giving the best results. Finally , we summarize the comparison of the use of multilin- gual features for the seq2seq model and language transfer learning of multilingual seq2seq model in Figure 3. Interestingly , on con- trary to our previous observations on DNN-HMM systems [19], we found multilingual features superior to language transfer learning in seq2seq model case. 7. CONCLUSIONS W e have presented various multilingual approaches in seq2seq sys- tems including multilingual features and multilingual models by lev eraging our multilingual DNN-HMM e xpertise. Unlike DNN- Model T ok Pisin Georgian %CER %CER Monolingual 32.2 34.8 Multilingual 37.2 51.1 Multilingual-fine tuned 27.5 33.3 T able 3 . Multilingual fine tuning of seq2seq model. Fig. 3 . Comparison of various multilingual approaches on Swahili. HMM systems [19], we obtain the opposite conclusion that multi- lingual features are more ef fective in seq2seq systems. It is probably due to efficient fusion of two complementary approaches: explicit GMM-HMM alignment incorporated in BN features and seq2seq models in the final system. W ith this finding, we will further e xplore efficient combinations of the DNN-HMM and seq2seq systems as our future work. 8. REFERENCES [1] Ilya Sutskev er, Oriol V inyals, and Quoc V Le, “Sequence to sequence learning with neural networks, ” in Advances in neu- ral information pr ocessing systems , 2014, pp. 3104–3112. [2] Dzmitry Bahdanau, K yunghyun Cho, and Y oshua Bengio, “Neural machine translation by jointly learning to align and translate, ” arXiv preprint , 2014. [3] Kyunghyun Cho, Bart V an Merri ¨ enboer , Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Y oshua Bengio, “Learning phrase representations using RNN encoder-decoder for statistical machine translation, ” arXiv pr eprint arXiv:1406.1078 , 2014. [4] Jan K Choro wski, Dzmitry Bahdanau, Dmitriy Serdyuk, Kyungh yun Cho, and Y oshua Bengio, “ Attention-based mod- els for speech recognition, ” in Advances in neural information pr ocessing systems , 2015, pp. 577–585. [5] Alex Graves and Navdeep Jaitly , “T ow ards end-to-end speech recognition with recurrent neural networks., ” in ICML , 2014, vol. 14, pp. 1764–1772. Language Swahili Amharic T ok Pisin Georgian T ransfer %CER %CER %CER %CER Monoling. 28.6 45.3 32.2 34.8 Out 27.4 41.2 27.7 33.6 Att+Out 27.5 41.2 28.3 34.2 CTC+Out 27.6 41.2 27.9 33.7 Att+CTC+Out 28.0 42.1 27.6 34.1 T able 4 . Multilingual Language T ransfer [6] Alex Graves, “Supervised sequence labelling, ” in Supervised sequence labelling with r ecurrent neural networks , pp. 5–13. Springer , 2012. [7] William Chan, Na vdeep Jaitly , Quoc Le, and Oriol V inyals, “Listen, attend and spell: A neural network for large vocab- ulary con versational speech recognition, ” in IEEE Interna- tional Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2016, pp. 4960–4964. [8] Andrew Rosenberg, Kartik Audhkhasi, Abhinav Sethy , Bhu- vana Ramabhadran, and Michael Picheny , “End-to-end speech recognition and ke yword search on low-resource languages, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2017, pp. 5280–5284. [9] Sibo T ong, Philip N Garner, and Herv ´ e Bourlard, “ An inv esti- gation of deep neural networks for multilingual speech recog- nition training and adaptation, ” T ech. Rep., 2017. [10] Martin Karafi ´ at, Murali Karthick Baskar , Pa vel Mat ˇ ejka, Karel V esel ` y, Franti ˇ sek Gr ´ ezl, and Jan ˇ Cernocky , “Multilingual blstm and speaker-specific v ector adaptation in 2016 BUT Ba- bel system, ” in Spok en Language T echnology W orkshop (SL T), 2016 IEEE . IEEE, 2016, pp. 637–643. [11] Sibo T ong, Philip N Garner, and Herv ´ e Bourlard, “Multilingual training and cross-lingual adaptation on CTC-based acoustic model, ” arXiv preprint , 2017. [12] Pawel Swietojanski and Stev e Renals, “Learning hidden unit contributions for unsupervised speak er adaptation of neural network acoustic models, ” in Spoken Language T echnology W orkshop (SLT), 2014 IEEE . IEEE, 2014, pp. 171–176. [13] Markus M ¨ uller , Sebastian St ¨ uker , and Alex W aibel, “Language adaptiv e multilingual CTC speech recognition, ” in Interna- tional Confer ence on Speech and Computer . Springer, 2017, pp. 473–482. [14] Siddharth Dalmia, Ramon Sanabria, Florian Metze, and Alan W . Black, “Sequence-based multi-lingual low resource speech recognition, ” in ICASSP . 2018, pp. 4909–4913, IEEE. [15] Shinji W atanabe, T akaaki Hori, and John R Hershey , “Lan- guage independent end-to-end architecture for joint language identification and speech recognition, ” in Automatic Speech Recognition and Understanding W orkshop (ASRU), 2017 IEEE . IEEE, 2017, pp. 265–271. [16] Shubham T oshniwal, T ara N Sainath, Ron J W eiss, Bo Li, Pe- dro Moreno, Eugene W einstein, and Kanishka Rao, “T owards language-univ ersal end-to-end speech recognition, ” in IEEE International Conference on Acoustics, Speech and Signal Pr o- cessing (ICASSP) , 2018. [17] Jaejin Cho, Murali Karthick Baskar , Ruizhi Li, Matthew W ies- ner , Sri Harish Mallidi, Nelson Y alta, Martin Karafiat, Shinji W atanabe, and T akaaki Hori, “Multilingual sequence-to- sequence speech recognition: architecture, transfer learning, and language modeling, ” in IEEE W orkshop on Spoken Lan- guage T ec hnology (SLT) , 2018. [18] Zoltan T uske, Da vid Nolden, Ralf Schluter , and Hermann Ne y , “Multilingual mrasta features for lo w-resource ke yword search and speech recognition systems, ” in IEEE International Con- fer ence on Acoustics, Speec h and Signal Pr ocessing (ICASSP) , 2014, pp. 7854–7858. [19] Martin Karafi ´ at, K. Murali Baskar, Pav el Mat ˇ ejka, Karel V esel ´ y, Franti ˇ sek Gr ´ ezl, and Jan ˇ Cernock ´ y, “Multilingual blstm and speaker-specific vector adaptation in 2016 but ba- bel system, ” in Pr oceedings of SLT 2016 . 2016, pp. 637–643, IEEE Signal Processing Society . [20] Shinji W atanabe, T akaaki Hori, Suyoun Kim, John R Hershey , and T omoki Hayashi, “Hybrid CTC/attention architecture for end-to-end speech recognition, ” IEEE Journal of Selected T op- ics in Signal Pr ocessing , vol. 11, no. 8, pp. 1240–1253, 2017. [21] Matthias Sperber , Jan Niehues, Graham Neubig, Sebastian Stker , and Alex W aibel, “Self-attentional acoustic models, ” in 19th Annual Confer ence of the International Speech Com- munication Association (InterSpeech 2018) , 2018. [22] Chung-Cheng Chiu and Colin Raffel, “Monotonic chunkwise attention, ” CoRR , vol. abs/1712.05382, 2017. [23] Jan Chorowski, Dzmitry Bahdanau, Dmitriy Serdyuk, Kyungh yun Cho, and Y oshua Bengio, “ Attention-based mod- els for speech recognition, ” in Advances in Neural Informa- tion Processing Systems . 2015, v ol. 2015-January , pp. 577– 585, Neural information processing systems foundation. [24] Daniel Pove y , Arnab Ghoshal, Gilles Boulianne, Lukas Bur- get, Ondrej Glembek, Nagendra Goel, Mirko Hannemann, Petr Motlicek, Y anmin Qian, Petr Schwarz, et al., “The Kaldi speech recognition toolkit, ” in Automatic Speech Recognition and Understanding , 2011 IEEE W orkshop on . IEEE, 2011, pp. 1–4. [25] Mike Schuster and Kuldip K Paliwal, “Bidirectional recurrent neural networks, ” IEEE T ransactions on Signal Pr ocessing , vol. 45, no. 11, pp. 2673–2681, 1997. [26] Sepp Hochreiter and J ¨ urgen Schmidhuber , “Long short-term memory , ” Neural computation , vol. 9, no. 8, pp. 1735–1780, 1997. [27] Shinji W atanabe, T akaaki Hori, Shigeki Karita, T omoki Hayashi, Jiro Nishitoba, Y uya Unno, Nelson Enrique Y alta Soplin, Jahn Heymann, Matthe w W iesner, Nanxin Chen, et al., “ESPnet: End-to-end speech processing toolkit, ” arXiv pr eprint arXiv:1804.00015 , 2018. [28] Martin Karafi ´ at, Franti ˇ sek Gr ´ ezl, Mirko Hannemann, Karel V esel ´ y, Igor Szoke, and Jan ”Honza” ˇ Cernock ´ y, “BUT 2014 Babel system: Analysis of adaptation in NN based systems, ” in Pr oceedings of Interspeech 2014 , Singapure, September 2014. [29] Karel V esel ´ y, Martin Karafi ´ at, and Franti ˇ sek Gr ´ ezl, “Con volu- tiv e bottleneck network features for L VCSR, ” in Pr oceedings of ASR U 2011 , 2011, pp. 42–47. [30] Amit Agarwal et al., “ An introduction to computational net- works and the computational network toolkit, ” T ech. Rep. MSR-TR-2014-112, August 2014. [31] Karel V esel ´ y, Martin Karafi ´ at, Franti ˇ sek Gr ´ ezl, Milo ˇ s Janda, and Ekaterina Egorov a, “The language-independent bottleneck features, ” in Pr oceedings of IEEE 2012 W orkshop on Spoken Language T echnology . 2012, pp. 336–341, IEEE Signal Pro- cessing Society . [32] Suyoun Kim and Michael L. Seltzer , “T o wards language- univ ersal end-to-end speech recognition, ” in IEEE Interna- tional Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment