Learning Disentangled Representations for Timber and Pitch in Music Audio
Timbre and pitch are the two main perceptual properties of musical sounds. Depending on the target applications, we sometimes prefer to focus on one of them, while reducing the effect of the other. Researchers have managed to hand-craft such timbre-i…
Authors: Yun-Ning Hung, Yi-An Chen, Yi-Hsuan Yang
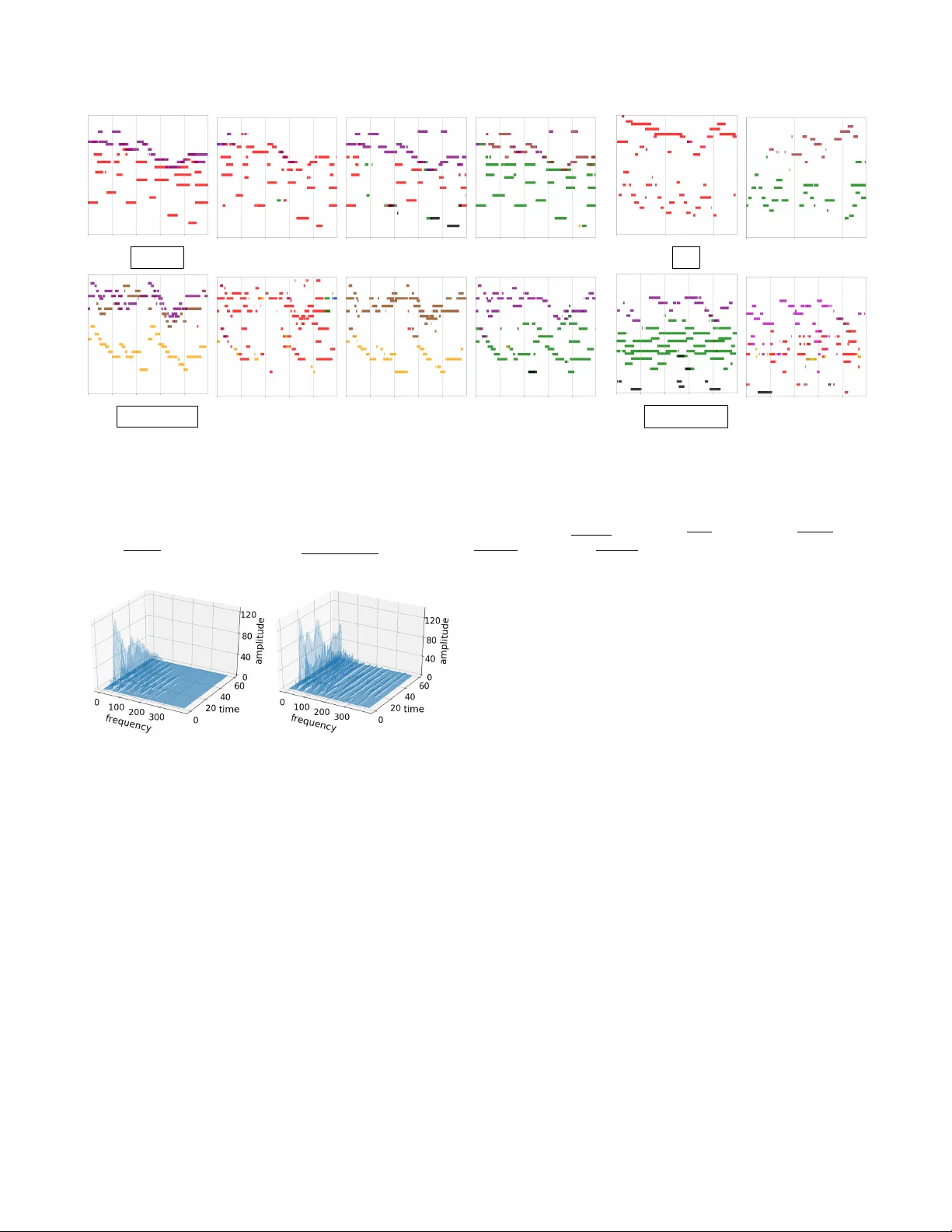
LEARNING DISENT ANGLED REPRESENT A TIONS FOR TIMBER AND PITCH IN MUSIC A UDIO Y un-Ning Hung 1 , Y i-An Chen 2 and Y i-Hsuan Y ang 1 1 Research Center for IT Innov ation, Academia Sinica, T aiwan 2 KKBO X Inc., T aiwan { biboamy,yang } @citi.sinica.edu.tw, annchen@kkbox.com ABSTRA CT T imbre and pitch are the two main perceptual properties of musical sounds. Depending on the target applications, we sometimes prefer to focus on one of them, while reducing the ef fect of the other . Researchers have managed to hand- craft such timbre-in variant or pitch-inv ariant features using domain knowledge and signal processing techniques, b ut it remains difficult to disentangle them in the resulting feature representations. Drawing upon state-of-the-art techniques in representation learning, we propose in this paper two deep con volutional neural network models for learning disentan- gled representation of musical timbre and pitch. Both models use encoders/decoders and adv ersarial training to learn music representations, but the second model additionally uses skip connections to deal with the pitch information. As music is an art of time, the two models are supervised by frame-le vel instrument and pitch labels using a new dataset collected from MuseScore. W e compare the result of the two disentan- gling models with a new ev aluation protocol called “timbre crossov er , ” which leads to interesting applications in audio- domain music editing. V ia various objecti ve evaluations, we show that the second model can better change the instru- mentation of a multi-instrument music piece without much affecting the pitch structure. By disentangling timbre and pitch, we en vision that the model can contrib ute to generating more realistic music audio as well. 1. INTR ODUCTION T imbre and pitch are the two main perceptual properties of musical sounds. For a musical note, the y refer to the percep- tion of sound quality and frequenc y of the note, respecti vely . For a musical phrase, the perception of pitch informs us the notes and their ordering in the phrase (e.g., Do-Do-So-So- La-La-So), whereas the perception of timbre informs us the instruments that play each note. T imbre and pitch are inter - dependent, but they can also be disentangled —we can use different instruments to play the same note sequence, and the same instrument to play different note sequences. While lis- tening to music, human beings can selectiv ely pay their at- tention to either the timbre or pitch aspect of music. For AI applications in music, we hope machines can do the same. Preserving the characteristics of one property while re- ducing those of the other has been studied in the literature. When the goal is to b uild a computational model that rec- ognizes the note sequences (e.g., for tasks such as query by humming [1] and cov er song identification [2]), we need a feature representation of music that is not sensitiv e to changes in timbre and instrumentation. In contrast, in building an in- strument or singer classifier , we may want to focus more on timbre rather than pitch. The pursuit of such timbre- or pitch-in variant features has been mostly approached with domain knowledge and signal processing techniques [3, 4]. Ho wever , the ef fectiveness of these features is usually e valuated by their performance in the downstream recognition or classification problems, i.e., from an analysis point of vie w . For example, a timbre-in variant fea- ture is supposed to work better than a non timbre-in variant one for harmonic analysis. It remains unclear ho w timbre and pitch are actually disentangled in the feature representations. W ith the recent success in learning disentangled represen- tations for images using deep autoencoders [5, 6], we see ne w opportunities to tackle timbre and pitch disentanglement for music from the synthesis point of vie w . T aking a musical au- dio clip as input, we aim to b uild a model that processes the timbre and pitch information in two different streams to ar- riv e at the intermediate timbre and pitch representations that are disentangled, and that can be combined to r econstruct the original input. If timbre and pitch are successfully disentan- gled, we expect that we can change the instrumentation of a music clip with this model by manipulating the timbre repre- sentation only , while fixing the pitch representation. 1 T o our best knowledge, this work represents the first at- tempt to disentangle timber and pitch in music audio with deep encoder/decoder architectures. Our approach has a few advantages over the con ventional analysis approach. First, we adopt a deep neural network to learn features in a data-dri ven 1 If we think about timbre as tone colors , this is like coloring the music clip in different w ays. When there are multiple instruments, the model needs to decide which instrument plays which notes. way , instead of hand-crafting the features. Second, we can use the learned features to generate an audio signal, which provides a direct way to e valuate the effecti veness of disen- tanglement. Third, accordingly , it enables ne w applications in audio-domain music editing —to manipulate the timbre and pitch content of an existing music clip without re-recording it. Lastly , giv en a note sequence generated by human or an AI composer [7 – 9], our model can help decide ho w to color (i.e., add timbre to) it. Due to the dif ferences in images and music, we cannot directly apply existing methods to music. Instead, we propose two ideas that consider the specific characteristics of music in designing the encoders and decoders. The first idea is temporal supervision . In computer vision, people use image-lev el attributes as the supervisory signal to learn disentangled features. For example, to disentangle face identities and poses [10], or to disentangle dif ferent attributes of faces [6]. For music, we cannot analogously use clip-le vel labels, since timbre and pitch are associated with each indi- vidual musical notes, and a music clip is composed of mul- tiple notes. Therefore, we propose to use the multi-track pi- anor olls [11] as the learning target of our encoders/decoders to pro vide detailed temporal supervision at the frame le vel. That is, instead of aiming to reconstruct the input audio, we aim to generate as the output of the netw ork the pianoroll as- sociated with the input audio. A pianoroll is a symbolic rep- resentation of music that specifies the timbre and pitch per note. It can be deriv ed from a MIDI file [11]. W e manage to compile a new dataset with 350,000 pairs of audio clips and time-aligned MIDIs. The temporal supervision provided by the dataset greatly facilitates timbre and pitch disentan- glement, for otherwise the model has to learn from the audio signals in an unsupervised w ay . W e intend to mak e public the dataset and our code for reproducibility . The second idea is to use dif ferent operations to deal with timbre and pitch. Specifically , we propose to use con volutions in the encoder to learn the abstract timbre representation in the latent space, and use symmetric skip connections to allow the pitch information to flo w directly from the encoder to the decoder . This design is based on the intuition that, when we use a time-frequency representation such as the spectrogram as the input, the timbre aspect actually af fects how the ener gy of the harmonic partials distributes along the frequency axis and de velops o ver time [3], whereas the pitch aspect deter- mines only what the fundamental frequency and duration of the notes are. T o make an analogy between music and images, pitch acts like the boundary of visual objects, whereas timbre acts like the texture. W e therefore aim to learn an embedding for the texture, while process the discrete pitch information with skip connections, which ha ve been found effecti ve in im- age segmentation [12]. Specifically , we propose two models for disentangling timbre and pitch. The first model (DuoAE) uses separate encoders for timbre and pitch, whereas the second model E p Z p D p E t Z t D t X ˆ p X ˆ t X ˆ n p X ˆ n t D r o l l X c q t X ˆ r o l l Time Note Instrument (a) DuoAE: Use separate encoders/decoders for timbre and pitch skip E c q t D r o l l D p X ˆ t X ˆ n p X c q t Z t D t X ˆ r o l l Time Note Instrument (b) UnetAE: Use skip connections to process pitch Fig. 1 . The two proposed encoder/decoder architectures for disentangling timbre and pitch for music audio. The dashed lines indicate the adversarial training parts. (Nota- tions: CQT —a time-frequency representation of audio; roll– multi-track pianoroll; E—encoder; D—decoder; Z—latent code; t—timbre; p—pitch; skip—skip connections). (UnetAE) adopts the aforementioned second idea and use skip connections to deal with pitch. Both models employ adversarial training [13]. Figure 1 illustrates the two models. W e will present the model details later . As secondary contributions, for music editing and genera- tion purposes, we additionally train another encoder/decoder sub-network to con vert the pianorolls into audio signals. W e find that the use of binary neur ons [14] is critical for this ne w sub-network. In addition, we propose a ne w ev aluation pro- tocol called “timbre crossover” to e valuate ho w well we can create a ne w music by exchanging the instrumentation of two existing pieces, using the timbre representation of one piece in reconstructing the pianoroll or audio of the other piece. W e report systematic objectiv e ev aluations of the result of timbre crossov er . 2. B A CKGROUND A deep autoencoder (or AE for short) is a network archi- tecture that uses a stack of encoding layers (kno wn collec- tiv ely as an encoder ) to get a low-dimensional representa- tion of data, which originally resides in a high-dimensional space [15]. The resulting representation is also known as the latent code . The network is trained such that we can recover the input from the latent code, by passing the latent code through another stack of decoding layers (known collecti vely as a decoder ). Compared to other representation learning methods, the AE has the adv antages that the training is unsu- pervised, and that the obtained representation can be mapped back to the data space. W ith the original AE, different properties of data might be entangled in the latent code, meaning that each entry of the latent code is related to multiple data properties. For instance, we can train an AE with face images to obtain a latent vector z ∈ R k for an image, where k denotes the dimensionality of the latent code. If we add some noise to only a random entry of z and then decode it, likely man y properties of the decoded face would be dif ferent from the original face. W ith some labeled data, we can train an AE in a way that different parts of the latent code correspond to different data properties. F or example, gi ven face images labeled with iden- tities and poses, we can di vide z into two parts z 1 and z 2 (i.e., z = [ z T 1 , z T 2 ] T ), and use them as the input to tw o separate stacks of fully-connected layers to train an identity classifier C 1 and a pose classifier C 2 , respectively . W e still require the concatenated code (i.e., z ) to reconstruct the input. With this AE, if we add changes to z 2 but keep z 1 the same, we may obtain an image with the same identity but a different pose. In this way , we call z 1 and z 2 disentangled representations of face identities and poses. W e can further impro ve the result of disentanglement by using adversarial training . As usual, we aim to minimize the classification error of C 1 and C 2 when their input is z 1 and z 2 , respectiv ely . Howe ver , we additionally use z 2 and z 1 as the input to C 1 and C 2 respectiv ely , and aim to maximize the clas- sification error of the two classifiers under such a scenario. In this way , we promote identity information in z 1 while dis- pel an y information related to pose, and similarly for z 2 . This idea was proposed by [6]. There are many other ways to achiev e disentanglement, e.g., using generativ e adversarial networks (GAN) [10, 16, 17], cross-cov ariance penalties [18], and latent space arithmetic operations [19]. Some are unsupervised methods. While the majority of work has been on images, feature disentanglement has also been studied for video clips [20], speech clips [19], 3D data [21], and MIDIs [22, 23]. Our work distinguishes itself from the existing works mainly in the follo wing tw o aspects. First, we use temporal supervision to learn disentangled representations, while ex- isting work usually use image- or clip-level labels, such as face identity , speaker identity [19], and genre [23]. Second, to our best knowledge, little has been done for disentangled representation learning in music audio. Although MIDI is also a type of music, an disentangling model for encoding MIDIs cannot be applied to musical audio signals. 2 3 2 For example, the sounds of different partials from different instruments are mixed in audio, b ut this does not happen in MIDIs. 3 Disentangling musical properties in MIDIs is a challenging task as well. [22] aimed to disentangle melody and instrumentation using a variational au- toencoder (V AE), but they found that manipulating the instrumentation code (while fixing the melody code) would still change the melody . (a) Pianoroll (b) Instrument roll (c) Pitch roll Fig. 2 . Different symbolic representations of music. 3. PR OPOSED MODELS FOR DISENT ANGLEMENT Figure 1 sho ws the architecture of the proposed models for disentangling timbre and pitch. W e present the details belo w . 3.1. Input/Output Data Representation 3.1.1. Input The input to our models is an audio wav eform with arbi- trary length. T o facilitate timbre and pitch analysis, we firstly con vert the wa veform into a time-frequenc y representation that sho ws the energy distribution across dif ferent frequency bins for each short-time frame. Instead of using the short- time Fourier transform (STFT), we use the constant-Q trans- form (CQT) here, for the latter adopts a logarithmic frequency scale that better aligns with our perception of pitch [24]. CQT also provides better frequency resolution in the low-frequenc y part, which helps detect the fundamental frequencies. As will be sho wn later , our encoders and decoders are de- signed to be fully-con volutional [25], so that our models can deal with input of an y length in testing time. Howe ver , for the con venience of training the models with mini-batches, in the training stage we di vide the wav eforms in our training set into 10-second chunks (without o verlaps) and use these chunks as the model input, leading to a matrix X cq t ∈ R F × T of fixed size for each input. In our implementation, we compute CQT with the librosa library [26], with 16,000 Hz sampling rate and 512-sample windo w size, again with no ov erlaps. W e use a frequenc y scale of 88 bins, with 12 bins per octa ve to repre- sent each note. Hence, F = 88 (bins) and T = 312 (frames). 3.1.2. Output T o pro vide temporal supervision, we use the pianorolls as the target output of our models. 4 As depicted in Figure 2, a pi- anoroll is a binary-v alued tensor that records the presence of notes (88 notes here) across time for each track (i.e., in- strument) [11]. When we consider M instruments, the target model output would be X rol l ∈ { 0 , 1 } F × T × M . X rol l and X cq t are temporally aligned, since we use MIDIs that are time-aligned with the audio clips to deriv e the pianorolls, as will be discussed in Section 5. 4 Strictly speaking, such a model is no longer an autoencoder , since the input and target output are different. W e abuse the terminology for the short names of our models, e.g., Duo‘ AE. ’ As shown in Figure 1, besides asking our models to gener- ate X rol l from the latent code of X cq t , we use the instrument r oll X t ∈ { 0 , 1 } M × T and pitch r oll X p ∈ { 0 , 1 } F × T as su- pervisory signals to disentangle timbre and pitch. As depicted in Figure 2, these two rolls can be obtained respecti vely by marginalizing a certain dimension of the pianoroll. 3.2. The DuoAE Model The architecture of DuoAE is illustrated in Figure 1(a). The designed is based on [6], but we use temporal supervision here and adapt the model to encode music. Specifically , we train two encoders E t and E p to respec- tiv ely con vert X cq t into the timbr e code Z t = E t ( X cq t ) ∈ R κ × τ and pitch code Z p = E p ( X cq t ) ∈ R κ × τ . W e note that, unlike in the case of image representation learning, here the latent codes are matrices , and we require that the second di- mensions (i.e., τ ) represent time. This w ay , each column of Z t and Z p is a κ -dimensional representation of a temporal segment of the input. F or abstraction, we require κτ < F T . DuoAE also contains three decoders D rol l , D t and D p . The encoders and decoders are trained such that we can use D rol l ([ Z T t , Z T p ] T ) to predict X rol l , D t ( Z t ) to predict X t , and D p ( Z p ) to predict X p . The prediction error is measured by the cross entr opy between the ground truth and the predicted one. For e xample, for the timbre classifier D t , it is: L t = − P [ X t · ln σ ( b X t ) + (1 − X t ) · ln(1 − σ ( b X t ))] , (1) where b X t = D t ( Z t ) , ‘ · ’ denotes the element-wise product, and σ is the sigmoid function that scales its input to [0 , 1] . W e can similarly define L rol l and L p . In each training epoch, we optimize both the encoders and decoders by minimizing L rol l , L t and L p for the gi ven train- ing batch. W e refer to the w ay we train the model as using the temporal supervision, since to minimize the lost terms L rol l , L t and L p , we have to make accurate prediction for each of the T time frames. When the adversarial training strategy is employed (i.e., those marked by dashed lines in Figure 1(a)), we additionally consider the following tw o lost terms: L n t = − P [ 0 t · ln σ ( b X n t ) + (1 − 0 t ) · ln(1 − σ ( b X n t ))] , (2) L n p = − P [ 0 p · ln σ ( b X n p ) + (1 − 0 p ) · ln(1 − σ ( b X n p ))] , (3) where b X n t = D t ( Z p ) , b X n p = D p ( Z t ) , meaning that we feed the ‘wrong’ input (purposefully) to D t and D p . Moreover , 0 t = 0 M ,T and 0 p = 0 F,T are tw o matrices of all zer os . That is to say , when we use the wrong input, we expect D t and D p can output nothing (i.e., all zeros), since, e.g., Z p is supposed not to contain any timbre-related information. Please note that, in adversarial training, we use L n t and L n p to update the encoders only . This is to preserve the function of the decoders in making accurate predictions. 3.3. The UnetAE Model The architecture of UnetAE is depicted in Figure 1(b). 5 In UnetAE, we learn only one encoder E cq t to get a single latent representation Z t of the input X cq t . W e add skip connections between E cq t and D rol l and learn E cq t and D rol l by mini- mizing L rol l , the cross entropy between D rol l ( Z t ) and the pianoroll X rol l . Moreo ver , we promote timbre information in Z t by refining E cq t and learning a classifier D t by minimiz- ing L t (see Eq. (1)). When the adv ersarial training strate gy is adopted, we use the classifier D p pre-trained from DuoAE to further dispel pitch information from Z t , by updating E cq t (but fixing D p ) to minimize L n p (see Eq. (3)). In summary , we use L rol l , L t , and optionally L n p , to train the encoder E cq t ; use L rol l to train the decoder D rol l ; and use L t to train the timbre classifier D t . W e discard the lost term L n p when we do not use adversarial training. The two key design principals of UnetAE are as follows. First, since Z t is supposed not to have any pitch informa- tion, the only way to obtain the pitch information needed to predict X rol l is from the skip connections. Second, there are reasons to belie ve that the skip connections can pass along the pitch information, because there is nice one-to-one time- frequency correspondence between X cq t and each frontal slice of X rol l , 6 and because in X cq t pitch only af fects the lowest partial of a harmonic series created by a musical note, while timbre af fects all the partials. If we vie w pitch as the boundary outlining an object (i.e., the harmonic series) and timbre as the texture of that object, it makes sense to use a U-net structure, since U-net performs well in image se gmen- tation [12, 27]. 3.3.1. Discussion The major difference between DuoAE and UnetAE is that there is no pitch code Z p in UnetAE. W e argue below why this may be fine for music editing and generation applications. As discussed in the introduction, pitch determines what (i.e., the notes) to be played in a music piece, whereas tim- bre determines how they would sound like to a listener . While the pitch content of a music piece can be largely specified on the musical score (i.e., symbolic notations of music), the tim- bre content manifests itself in the audio sounds. Therefore, we can learn the timbre code Z t from an input audio repre- sentation such as the wa veform, STFT , or CQT . If we want to 5 W e explain the name ‘Unet’ below . When the design of the encoder (E) and decoder (D) is symmetric , meaning that they have the same number of layers and that they use the same kernel sizes and stride sizes in the cor- responding layers, we can add skip connections between the corresponding layers of E and D, by concatenating the output of the i -th layer of E to the input of the i -th last layer of D in the channel-wise direction. In this way , lower -layer information of E (closer to the input) can be directly passed to the higher-layer of D (closer to the output), making it easier to train deeper AEs. Because the resulting architecture has a U-shape, people refer to it as a U-net [12]. 6 That is, both X cqt ( i, j ) and X roll ( i, j, m ) refer to the activity of the same musical note i for the same time frame j . skip E r o l l D s t f t Z r o l l Z t X ˆ s t f t skip E c q t D r o l l D p Z t D t B N s X ˆ r o l l X c q t Fig. 3 . The architecture of the proposed model for music audio editing, using UnetAE for disentangling timbre and pitch. learn the pitch code Z p , we can learn it from symbolic repre- sentations of music, as pursued in existing work on symbolic- domain music generation [8, 22, 23, 28, 29]. Since the pitch code can be learned from musical scores, we may focus on learning the timbre code from music audio. Moreov er , for music audio editing, we are interested in manipulating the instrumentation of a clip without much af- fecting its pitch content. F or this purpose, it may be suf ficient to have the timbre code, since in UnetAE the pitch content can flow directly from the encoder to the decoder . On the other hand, to manipulate the pitch content without af fecting the timbre, we can change the pitch in the symbolic domain and then use the same timbre code for decoding. 3.3.2. Implementation Details Since the input and target output are both matrices (or ten- sors), we use con volutional layers in all the encoders and decoders of DuoAE and UnetAE. T o accommodate input of variable length, we adopt a fully-con volutional design [25], meaning that we do not use pooling layers at all. In the en- coders, we achieve dimension reduction (i.e., reducing F to κ and reducing T to τ ) by setting the stride sizes of the k ernels larger than one. W e use 3 × 3 kernels in every layers of the encoders. In the decoders, we use transposed conv olution for upsampling. The kernel size is also 3 × 3 . Moreo ver , we use leaky ReLU as the acti vation function and add batch normal- ization to all but the last layer of the decoders, where we use the sigmoid function. Both DuoAE and UnetAE are trained using stochastic gradient descend (SGD) with momentum 0.9. The initial learning rate is set to 0.01. 4. PR OPOSED MODEL FOR MUSIC EDITING The model we propose for music editing is shown in Figure 3. W e use an additional encoder -decoder subnet E rol l and D stf t after UnetAE to con vert pianorolls to the audio domain. 7 Here we use the STFT spectrograms of the original input audio as the target output. The model is trained in an end-to-end fash- ion by additionally minimizing L M S E , the MSE between the groundtruth STFT X stf t and the predicted one b X stf t . Lastly , we use the Griffin-Lim algorithm [30] to estimate the phase of the spectorgram and generate the audio. 7 Such a pianoroll-to-audio con version can be made with commercial syn- thesizers, but the resulting sounds tend to be deadpan. Once the model is trained, timbre editing can be done by manipulating the timbre code Z t and then generate b X stf t . And, pitch editing can be done by manipulating the interme- diate pianoroll b X rol l and then generate b X stf t . There are three critical designs to make it work. First, we concatenate Z t with Z rol l , the output of E rol l . This is impor- tant since the input to E rol l is pianorolls, but the pianorolls do not contain sufficient timbre information to generate real- istic audio. Second, we only use one skip connection between E rol l and D stf t , because if we use too many skip connections the gradients from the STFT will affect the training of D rol l and lead to noisy pianorolls b X rol l . Third, to further prevent the gradients from the STFT to affect the pianorolls, we use deterministic binary neur ons (BN) [14] to binarize the output of D rol l with a hard thresholding function. 4.0.1. Discussion A few other models hav e been proposed to generate musi- cal audio signals. Many of them do not take auxiliary con- ditional signal to condition the generation process. These in- clude auto-regressiv e models such as the W av eNet model [31] and GAN-based models such as the W a veGAN model [32]. Some recent works started to explore the so-called scor e-to- audio music generation [33, 34], where the audio generation model is given a musical score and is asked to render the score into sounds. While the model proposed by Hawthorne et al. [34] deals with only piano music, both our music editing model and the PerformanceNet model proposed by W ang and Y ang [33] aim to generate music of more other instruments. Howe ver , our model is different from these two prior arts in that we are not dealing with score-to-audio music genera- tion but actually audio editing, which con verts an audio into another audio. W e use the estimated pianoroll b X rol l in the midway of the generation process for controllability . As Fig- ure 3 sho ws, our model takes not only the pianoroll b X rol l but also the timbre code Z t of the original audio as inputs. W e find such a problem setting interesting and would try to further im- prov e it in our future work, using for example W aveNet-based decoder or GAN training for better audio quality . 5. D A T ASET W e build a new dataset with paired audio and MIDI files to train and ev aluate the proposed models. This is done by crawl- Method #Params T ranscription Crossov er (* → piano) Crossov er (* → guitar) Crossov er (pia → str) Acc Pitch Acc T imbre HI Pitch Acc Timbre HI Pitch Acc T imbre HI Baseline model 3,277k 0.314 — — — — — — Prior art [17] 6,533k — 0.558 — 0.537 — — — Prior art [35] 7,729k — 0.295 — 0.279 — — — DuoAE w/o adv 9,438k 0.395 0.595 0.990 0.664 0.983 0.743 0.998 DuoAE 9,808k 0.372 0.660 0.990 0.647 0.989 0.718 0.998 UnetAE w/o adv 3,499k 0.396 0.563 0.869 0.611 0.911 0.681 0.966 UnetAE 3,868k 0.431 0.691 0.893 0.727 0.962 0.748 0.992 T able 1 . The performance of different models for transcription (i.e., pianoroll prediction) and timbre crossov er , ev aluated in terms of pitch accuracy (Acc) and the timbre histogram intersection (HI) rate. The last two columns are ‘piano to violin+cello’ con version. W e use ‘w/o adv’ to denote the cases without adversarial training, and ‘#Params’ the total number of parameters. The ‘baseline model’ (see Section 6.1) shown in the first ro w does not use timbre and pitch classifiers and adversarial training. ing the MuseScore web forum ( https://musescore. com/ ), obtaining around 350,000 unique MIDI files and the corresponding MP3 files. Most MP3 files were synthe- sized from the MIDIs with the MuseScore synthesizer by the uploaders. 8 Hence, the audio and MIDIs are already time- aligned. W e further ensure temporal alignment by using the method proposed by [36]. W e then con vert the time-aligned MIDIs to pianorolls with the Pypianoroll package [11]. W e consider the following nine instruments in this work (i.e., M = 9 ): piano, acoustic guitar , electrical guitar, trum- pet, saxphone, bass, violin, cello and flute. They are chosen based on their popularity in modern music and MuseScore. 9 The av erage length of the music clips is ∼ 2 minutes. W e ran- domly pick 585–1000 clips per instrument for the training set, and 27–50 clips per instrument for the test set. As a result, the training and test sets are class-balanced. 6. EXPERIMENT In what follows, we first e valuate the accuracy of our models in predicting the pianorolls. W e then ev aluate the result of timbre and pitch disentanglement by e xamining the learned embeddings and by the timbre crossov er ev aluation method. 6.1. Evaluation on Pianoroll Prediction W e first e valuate how well we can transcribe the pianorolls from audio. Since b X rol l , the output of D rol l , is a real-valued tensor in [0 , 1] F × T × M , we further binarize it with a simple threshold picking algorithm so that we can compare it with the groundtruth pianoroll X rol l , which is binary . W e select the threshold (from 0.1, 0.15, . . . , 0.95, in total 20 candi- dates) by maximizing the accurac y on a held-out validation 8 Though synthesized audio may sounds different than realistic audio, the problem can be solved by domain adaptation [5]. W e take it as a future task and will not further discussed in this paper . Besides, we also tested the model on realistic music and found that the model performs well for many of them. 9 W e exclude drums for they are non-pitched. And, we exclude the singing voices, for the y are not transcribed in MIDIs. set. The accuracy (denoted as ‘ Acc’) is calculated by compar - ing X rol l and b X rol l per instrument (by calculating the propor- tion of true positiv es among the F T entires) and then taking the a verage across the instruments. This way , we can measure the accuracy for both instrument and pitch prediction, since falsely predicting the instrument of a note would also reduce the number of true positiv es for instruments. In addition to DuoAE and UnetAE, we consider a base- line model that uses only an encoder E cq t and a decoder D rol l to get the latent code Z t . That is, not using additional timbre and pitch classifiers and adversarial training. The first three columns of T able 1 show the result. Both DuoAE and UnetAE perform much better than the baseline. In addition, UnetAE outperforms DuoAE, despite that Une- tAE uses much fe wer parameters than DuoAE. W e attribute this to the skip connections, which bring detailed information from the input to the decoding process and thereby help pitch localization. The best accurac y 0.431 is achie ved by UnetAE, with adversarial training. 6.2. Evaluation on Disentanglement 6.2.1. t-SNE visualization of the learned timbr e code The first thing we do to ev aluate the performance of timbre and pitch disentanglement is via examining the timbre code Z t , by projecting them from the κ -dimensional space to a 2- D space with distrib uted stochastic neighbor embedding (t- SNE) [37]. W e implement the t-SNE algorithm via Sklearn li- brary with learning rate 20, perplexity 30 and #iteration 1,000. The first column of Figure 4 shows the learned timbre code for audio chunks of instrument solos randomly picked from Mus- eScore. W e can see clear clusters of points from the result of DuoAE and UnetAE, which is fav orable since an instrument solo in volves only one instrument. The second column of Figure 4 sho ws the learned tim- bre code for two more cases: 1) audio chunks with tw o in- struments, picked from MuseScore; 2) audio chunks of in- strument solos, but with pitch purposefully shifted lower by (a) Baseline model (b) DuoAE (c) UnetAE Fig. 4 . t-SNE visualization [37] of the timbre code learned by different models (best vie wed in color). Left: the timbre codes of instrument solos. Right: the timbre code of audio chunks with two instruments, or of manipulated solo chunks that are six semitones lo wer than the original (‘6L ’). The instruments are piano, electric guitar , saxphone, bass, violin, cello, flute, acoustic guitar , trumpet. us. For the first case (in cyan), both DuoAE and UnetAE can nicely position the chunks in the middle of the two clus- ters of inv olved instruments. F or the second case (in pink), both DuoAE and UnetAE fail to position the chunks within the clusters of the in volv ed instruments, suggesting that the learned timbre code is not perfectly pitch in variant. But, from the distance between the chunks and the corresponding clus- ters, it seems UnetAE performs slightly better . 6.2.2. T imbr e Cr ossover Secondly , we propose and employ a new ev aluation method called timbr e cr ossover to ev aluate the result of disentangle- ment. Specifically , we exchange the timbre codes of two ex- isting audio clips and then decode them, to see whether we can exchange their instrumentation without affecting the pitch content in the symbolic domain. For example, if clip A (the sour ce clip ) plays the flute and clip B (the tar get clip ) plays the trumpet, we hope that after timbre crossover the new clip A ’ would use the trumpet to play the original tune. For objectiv e e valuation, we compare the pitch between the pianorolls of the source clip and the ne w clip to get the pitch Acc. Moreover , we present the activity of different in- struments in a clip as an M -bin histogram and compute the histogram intersection (HI) [38] between the histograms com- puted from the pianorolls of the target clip and the ne w clip. Both pitch accuracy and timbre HI are the higher the better . T able 1 tabulates the result of the following crossover scenarios: ‘anything → piano, ’ ‘anything → guitar , ’ and ‘piano → violin + cello. ’ W e compute the average result for 20 cases for each scenario. W e can see that UnetAE has better pitch accuracy while poorer HI. W e attrib ute this to the fact that UnetAE does not hav e control over the skip connections—some timbre information may still flow through the skip connections. But, the advantage of UnetAE is its timbre code is more pitch-in variant. When doing crossover , the pitch content would subject to less changes. In contrast, DuoAE achieves higher HI, suggesting that its pitch code is more timbre-in variant. But, as its timbre code is not pitch- in variant, when doing crosso ver , some notes might disappear , due to timbre replacement, causing the low pitch accurac y . Figure 5 demonstrates the result of UnetAE. In general, UnetAE works well in changing the timbre without much af- fecting the pitch. Please read the caption for details. Besides, we also adapt and e valuate the models proposed by [17] and [35] for timbre crossover . For the model proposed by [35], we consider ‘S’ as instrument and ‘Z’ as pitch and use pianorolls as the target output. For [17], we replace ‘style’ with pitch and ‘class’ with instrument. The output is also pi- anorolls instead of CQT . As T able 1 shows, they can only achiev e 0.558 and 0.295 Pitch Acc for ‘anything → piano, ’ and 0.537 and 0.279 Pitch Acc for ‘anything → guitar . ’ This poor result is expected, since these models were not designed for music disentanglement. 6.2.3. Audio-domain Music Editing Finally , we demonstrate the result of timbre crossov er in the audio domain, using the model depicted in Figure 3. Figure 6 shows the spectrograms of a note chunked from the original and generated audio clips, for piano → violin crossover . It is known that, compared to piano, violin has longer sustain after the attack, and stronger ener gy at the harmonics [39]. W e can see such characteristics in the generated spectrogram. How- ev er, so far we note that the model may not be sophisticated enough (e.g., perhaps we can additionally use a GAN-based loss) so the audio quality has room for improvement, but it shows that music audio editing is feasible. 6.3. Ablation Study The two models ‘w/o adv’ (i.e., without adv ersarial training) in T able 1 can be vie wed as ablated v ersions of the proposed (a) pia + flu (b) → pia (c) → pia + flu + bas (d) → vio + a-g (e) pia (f) → vio + a-g (g) vio + cel + flu (h) → pia (i) → vio + cel (j) → flu + a-g + bas (k) flu + a-g + bas (l) → tru Fig. 5 . Demonstration of timbre crossov er (best vie wed in color). The source clips are (a) , (e) , (g) and (k) , and the generated ones (i.e., after crossover by UnetAE) are those to the right of them. W e see from (c) that UnetAE finds the low-pitched notes for the bass to play; from (d) that it kno ws to use the violin to play the melody (originally played by the flute) and the acoustic guitar to play the chords (originally played by the piano); and from (l) that it does not always work well—it picks ne w instruments to play when the timbre palettes of the source and target clips do not match. [Purple: flute (flu), Red: piano (pia), Black: bass (bas), Green: acoustic guitar (a-g), Light purple: trumpet (tru), Y ellow: cello (cel), Bro wn: violin (vio)]. Fig. 6 . The spectrogram of a note from a piano clip (left) and the one after timbre crosso ver (right) by the UnetAE-based model shown in Figure 3. The tar get timbre is violin. models. W e report some more ablation study belo w . W e replace the pianorolls with CQT as the target output for DuoAE. In our study , we found that predicting pianorolls consistently outperforms predicting CQT in both instrument recognition accuracy (by 9.6%) and pitch accurac y (by 5.3%). Using the pianorolls as the target performs much better , for it provides the benefits of “temporal supervision” claimed as the first contribution of the paper in our introduction section. W e therefore decided to use the pianorolls as the tar get output for both DuoAE and UnetAE. Moreov er , we also remov e skip connection from the Un- etAE. By doing so, the transcription accuracy drops to 0.407. Moreov er , since there is no skip connection to help disentan- gle pitch and timbre, the pitch Acc of timbre crossov er would drop from 0.691 to 0.068. 7. CONCLUSION AND DISCUSSION In this paper , we ha ve presented two encoder/decoder models to learn disentangled representation of musical timbre and pitch. The core contrib ution is that the input to the models is an audio clip, and as a result it can change the timbre or pitch content of the audio clip by manipulating the learned timbre and pitch representations. W e can ev aluate the result of disentanglement by generating new pianorolls or audio clips. W e also proposed a ne w e v aluation method called “tim- bre crossover” to analyze timbre and pitch disentanglement. Through timbre exchanging, analysis sho ws that UnetAE has better ability to create new instrumentation without losing pitch information. W e also extend UnetAE to audio-domain editing. Result shows that it is feasible to change audio timbre through a deep network structure. Although our study shows that UnetAE can perform bet- ter than DuoAE in terms of transcription accurac y and timbre crossov er , a weakness of UnetAE is that it has limited control ov er the skip connections and as a result part of the timbre information may also flow through skip connection. Besides, UnetAE does not learn a pitch representation, so the model has little control of the pitch information. The loss function for adversarial training is another topic for future study . Currently , we predict the zero-metrics 0 t and 0 p to dispel information from the embeddings. Other loss function, such as the one proposed in [21], can also be tested. Besides, it is important to have further ev aluation on the tim- bre embedding. F or example, from the timbre crossov er we learn that timbre embedding someho w learns the relation be- tween pitch and timbre, b ut Figure 5k sho ws that it is not fea- sible to play the bass and chord with the trumpet. Further ex- periment can be done to test on v ariety of music genre and instrument combination. The proposed timbre crosso ver method holds the promise to help human or AI composer decide the instruments to play different parts of a given lead sheet or pianoroll. Howe ver , a drawback of the current model is that the timbre embeddings hav e to be picked from another music piece, which is less con venient in real-life usage. A more con venient scenario is that we can interpolate the existing embeddings and directly decide the instruments to use. A possible way to improve the model reg arding this is to add one-hot vector for conditional learning. The one-hot vector can then be used for controlling the instrument usage. The proposed audio editing model, though likely being the first one of its kind, is not sophisticated enough to syn- thesize realistic audio. The model can be improv ed by us- ing W aveNet [31] as the decoder , or by using the multi-band structure proposed by W ang and Y ang [33]. 8. REFERENCES [1] Asif Ghias, Jonathan Logan, David Chamberlin, and Brian C. Smith, “Query by humming: Musical infor- mation retrie val in an audio database, ” in Proc. ACM Multimedia , 1995, pp. 231–236. [2] Joan Serr ` a, Emilia G ´ omez, Perfecto Herrera, and Xa vier Serra, “Chroma binary similarity and local alignment applied to cover song identification, ” IEEE T rans. Au- dio, Speech, and Language Pr ocessing , vol. 16, no. 6, pp. 1138–1151, 2008. [3] Meinard M ¨ uller , Daniel P . W . Ellis, Anssi Klapuri, and Ga ¨ el Richard, “Signal processing for music analysis, ” IEEE J . Selected T opics in Signal Processing , vol. 5, no. 6, pp. 1088–1110, 2011. [4] Meinard M ¨ uller and Sebastian Ewert, “T o wards timbre- in variant audio features for harmony-based music, ” IEEE T rans. A udio, Speech, and Language Pr ocessing , vol. 18, no. 3, pp. 649–662, 2010. [5] Konstantinos Bousmalis, George Trigeor gis, Nathan Sil- berman, Dilip Krishnan, and Dumitru Erhan, “Domain separation networks, ” in Pr oc. Advances in Neural In- formation Pr ocessing Systems , 2016, pp. 343–351. [6] Y u Liu, Fangyin W ei, Jing Shao, Lu Sheng, Junjie Y an, and Xiaogang W ang, “Exploring disentangled feature representation beyond f ace identification, ” in Pr oc. IEEE Conf. Computer V ision and P attern Recognition , 2018, pp. 2080–2089. [7] Jose Da vid Fern ´ andez and Francisco V ico, “AI meth- ods in algorithmic composition: A comprehensi ve sur- ve y , ” J. Artificial Intelligence Resear ch , vol. 48, no. 1, pp. 513–582, 2013. [8] Hao-W en Dong, W en-Y i Hsiao, Li-Chia Y ang, and Y i- Hsuan Y ang, “MuseGAN: Symbolic-domain music generation and accompaniment with multi-track sequen- tial generativ e adversarial networks, ” in Pr oc. AAAI Conf. Artificial Intelligence , 2018. [9] Hao-Min Liu, Meng-Hsuan W u, and Y i-Hsuan Y ang, “Lead sheet generation and arrangement via a hybrid generativ e model, ” in Pr oc. Int. Soc. Music Information Retrieval Conf . , 2018, Late-breaking paper . [10] Luan Tran, Xi Y in, and Xiaoming Liu, “Disentangled representation learning GAN for pose-in variant face recognition, ” in Pr oc. IEEE Conf. Computer V ision and P attern Reco gnition , 2017, pp. 1283–1292. [11] Hao-W en Dong, W en-Y i Hsiao, and Y i-Hsuan Y ang, “Pypianoroll: Open source Python package for han- dling multitrack pianoroll, ” in Pr oc. Int. Soc. Music Information Retrieval Conf. , 2018, Late- breaking paper; [Online] https://github.com/ salu133445/pypianoroll . [12] Olaf Ronneberger , Philipp Fischer , and Thomas Brox, “U-net: Con volutional networks for biomedical image segmentation, ” in Proc. Int. Conf . Medical Image Com- puting and Computer-Assisted Intervention . Springer , 2015, pp. 234–241. [13] Michael Mathieu, Junbo Zhao, Pablo Sprechmann, Aditya Ramesh, and Y ann LeCun, “Disentangling fac- tors of v ariation in deep representations using adversar - ial training, ” in Pr oc. Advances in Neural Information Pr ocessing Systems , 2016. [14] Hao-W en Dong and Y i-Hsuan Y ang, “Con volutional generativ e adversarial networks with binary neurons for polyphonic music generation, ” in Pr oc. Int. Soc. Music Information Retrieval Conf . , 2018. [15] Jonathan Masci, Ueli Meier, Dan Cires ¸ an, and J ¨ urgen Schmidhuber , “Stacked con volutional auto-encoders for hierarchical feature extraction, ” in Pr oc. Int. Conf. Arti- ficial Neural Networks , 2011, pp. 52–59. [16] Rui Huang, Shu Zhang, Tian yu Li, and Ran He, “Be- yond face rotation: Global and local perception GAN for photorealistic and identity preserving frontal view synthesis, ” arXiv preprint , 2017. [17] Y ang Liu, Zhaowen W ang, Hailin Jin, and Ian W assell, “Multi-task adversarial network for disentangled feature learning, ” in Pr oc. IEEE Conf. Computer V ision and P attern Reco gnition , 2018, pp. 3743–3751. [18] Brian Cheung, Jesse A Liv ezey , Arjun K Bansal, and Bruno A Olshausen, “Disco vering hidden fac- tors of variation in deep networks, ” arXiv pr eprint arXiv:1412.6583 , 2014. [19] W ei-Ning Hsu, Y u Zhang, and James Glass, “Learning latent representations for speech generation and trans- formation, ” arXiv preprint , 2017. [20] Jun-Ting Hsieh, Bingbin Liu, De-An Huang, Fei-Fei Li, and Juan Carlos Niebles, “Learning to decompose and disentangle representations for video prediction, ” arXiv pr eprint arXiv:1806.04166 , 2018. [21] Feng Liu, Ronghang Zhu, Dan Zeng, Qijun Zhao, and Xiaoming Liu, “Disentangling features in 3D face shapes for joint face reconstruction and recognition, ” in Pr oc. IEEE Conf. Computer V ision and P attern Recog- nition , 2018, pp. 5216–5225. [22] Adam Roberts, Jesse Engel, Colin Raffel, Curtis Hawthorne, and Douglas Eck, “ A hierarchical latent vector model for learning long-term structure in music, ” in Pr oc. Int. Conf. Mac hine Learning , 2018, pp. 4361– 4370. [23] Gino Brunner , Andres Konrad, Y uyi W ang, and Roger W attenhofer , “MIDI-V AE: Modeling dynamics and in- strumentation of music with applications to style trans- fer , ” in Pr oc. Int. Soc. Music Information Retrieval Conf. , 2018, pp. 23–27. [24] Rachel M. Bittner , Brian McFee, Justin Salamon, Peter Li, and Juan P . Bello., “Deep salience representations for f 0 tracking in polyphonic music, ” in Pr oc. Int. Soc. Music Information Retrieval Conf . , 2017, pp. 63–70. [25] Maxime Oquab, L ´ eon Bottou, Ivan Laptev , and Josef Sivic, “Is object localization for free?-weakly- supervised learning with con volutional neural net- works, ” in Pr oc. Int. Computer V ision and P attern Recognition , 2015, pp. 685–694. [26] Brian McFee, Colin Raffel, Da wen Liang, Daniel PW Ellis, Matt McV icar , Eric Battenber g, and Oriol Nieto, “librosa: Audio and music signal analysis in python., ” in Pr oc. Python in Science Conf. , 2015, pp. 18–25. [27] V ijay Badrinarayanan, Alex Kendall, and Roberto Cipolla, “SegNet: A deep con volutional encoder- decoder architecture for image segmentation, ” IEEE T rans. P attern Analysis and Machine Intelligence , vol. 39, no. 12, pp. 2481–2495, 2017. [28] Li-Chia Y ang, Szu-Y u Chou, and Y i-Hsuan Y ang, “MidiNet: A con volutional generativ e adversarial net- work for symbolic-domain music generation, ” in Pr oc. Int. Soc. Music Information Retrieval Conf . , 2017. [29] Ian Simon, Adam Roberts, Colin Raffel, Jesse Engel, Curtis Hawthorne, and Douglas Eck, “Learning a latent space of multitrack measures, ” in Pr oc. Int. Soc. Music Information Retrieval Conf . , 2018. [30] D. Griffin and Jae Lim, “Signal estimation from modi- fied short-time Fourier transform, ” IEEE T rans. Acous- tics, Speech, and Signal Pr ocessing , vol. 32, no. 2, pp. 236–243, 1984. [31] A ¨ aron V . D. Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol V inyals, Alex Graves, Nal Kalch- brenner , Andrew W Senior , and Koray Ka vukcuoglu, “W a veNet: A generativ e model for raw audio, ” arXiv pr eprint arXiv:1609.03499 , 2016. [32] Chris Donahue, Julian McAule y , and Miller Puckette, “Synthesizing audio with generati ve adversarial net- works, ” arXiv pr eprint arXiv:1802.04208 , 2018. [33] Bryan W ang and Y i-Hsuan Y ang, “PerformanceNet: Score-to-audio music generation with multi-band con- volutional residual network, ” in Proc. AAAI Conf. Arti- ficial Intelligence , 2019. [34] Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, and Douglas Eck, “En- abling factorized piano music modeling and genera- tion with the MAESTR O dataset, ” arXiv preprint arXiv:1810.12247 , 2018. [35] Naama Hadad, Lior W olf, and Moni Shahar , “ A two- step disentanglement method, ” in Proc. IEEE Conf. Computer V ision and P attern Recognition , 2018, pp. 772–780. [36] Colin Raffel and Daniel P . W . Ellis, “Optimizing DTW- based audio-to-MIDI alignment and matching, ” in Proc. IEEE Int. Conf. Acoustics, Speech and Signal Pr ocess- ing , 2016, pp. 81–85. [37] Laurens v an der Maaten and Geof frey Hinton, “V isual- izing data using t-SNE, ” J. Machine Learning Resear ch , vol. 9, no. No v , pp. 2579–2605, 2008. [38] Michael J. Swain and Dana H. Ballard, “Color index- ing, ” Int. J. Computer V ision , vol. 7, no. 1, pp. 11–32, 1991. [39] Kenichi Miyamoto, Hirokazu Kameoka, T akuya Nishimoto, Nobutaka Ono, and Shigeki Sagayama, “Harmonic-temporal-timbral clustering (HTTC) for the analysis of multi-instrument polyphonic music signals, ” in Pr oc. IEEE Int. Conf . Acoustics, Speech and Signal Pr ocessing , 2008, pp. 113–116.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment