Reconstructing Speech Stimuli From Human Auditory Cortex Activity Using a WaveNet Approach
The superior temporal gyrus (STG) region of cortex critically contributes to speech recognition. In this work, we show that a proposed WaveNet, with limited available data, is able to reconstruct speech stimuli from STG intracranial recordings. We further investigate the impulse response of the fitted model for each recording electrode and observe phoneme level temporospectral tuning properties for the recorded area of cortex. This discovery is consistent with previous studies implicating the posterior STG (pSTG) in a phonetic representation of speech and provides detailed acoustic features that certain electrode sites possibly extract during speech recognition.
💡 Research Summary
This paper investigates whether a deep neural network inspired by WaveNet can reconstruct speech stimuli from intracranial electrocorticographic (ECoG) recordings of the human superior temporal gyrus (STG), a cortical region known to be crucial for phonetic processing. The authors collected ECoG data from two epilepsy patients undergoing neurosurgery. Each subject listened to 50 English words (recorded by a native female speaker) for a total of five minutes. The recordings were sampled at 3,051 Hz, high‑gamma filtered (70–150 Hz), envelope‑extracted via Hilbert–Huang transform, and down‑sampled to 100 Hz to match the speech spectrogram sampling rate. Speech audio was aligned with a 168 ms lag, passed through a 128‑band logarithmic filter bank, and then down‑sampled to a 32‑band, 100 Hz spectrogram.
Because the dataset is extremely small (only two subjects and 50 distinct words, each repeated a few times), the authors emphasized model parameter efficiency to avoid over‑fitting. They adapted the original WaveNet architecture, which is a dilated‑convolutional autoregressive model for raw audio generation, into a regression network that maps multichannel ECoG time series to speech spectrograms. The network consists of an initial 1‑D convolution (32 input channels, filter length 16) followed by ten residual blocks. Each block contains a gated unit with a dilated convolution (filter length 2, 32 feature maps) and exponential dilation rates of 1, 2, 4, 8, 16 repeated twice, giving a receptive field of 1,240 ms. Skip connections from all blocks are summed and passed through 1 × 1 convolutions to produce the 32‑band output. Batch normalization and dropout (0.2) are inserted between layers to further regularize training. The model contains roughly 509 k trainable parameters.
For comparison, the authors implemented two baseline models with the same receptive field: (1) a single‑layer linear convolution (equivalent to linear regression) and (2) a ResNet with eight residual blocks (filter length 4, 32 feature maps), containing about 132 k parameters. All models were trained using mean‑squared error loss and evaluated with 3‑fold (subject 1) or 4‑fold (subject 2) cross‑validation. Training sequences were 1 s long with 10 ms overlap, yielding 17 k (subject 1) and 26 k (subject 2) training segments, though the underlying vocabulary remained limited.
Quantitative results show that the adapted WaveNet consistently outperforms both baselines. For subject 1, WaveNet achieved a mean squared error (MSE) of 0.68 and a Pearson correlation coefficient (CC) of 0.65, compared with ResNet (MSE 0.79, CC 0.61) and linear regression (MSE 0.86, CC 0.57). For subject 2, WaveNet obtained MSE 0.69 and CC 0.71, again slightly better than ResNet (MSE 0.70, CC 0.70) and linear (MSE 0.71, CC 0.69). Visual inspection of reconstructed spectrograms confirmed that WaveNet preserves fine spectral details such as formant trajectories and rapid temporal fluctuations, whereas the linear model yields overly smoothed spectra and ResNet introduces artificial sharpening and aliasing artifacts. After converting the spectrograms back to waveforms using an iterative complex projection algorithm, a few words reconstructed by WaveNet (“waldo”, “yich”, “pave”) were intelligible to listeners, while ResNet reconstructions were largely unintelligible despite similar visual appearance.
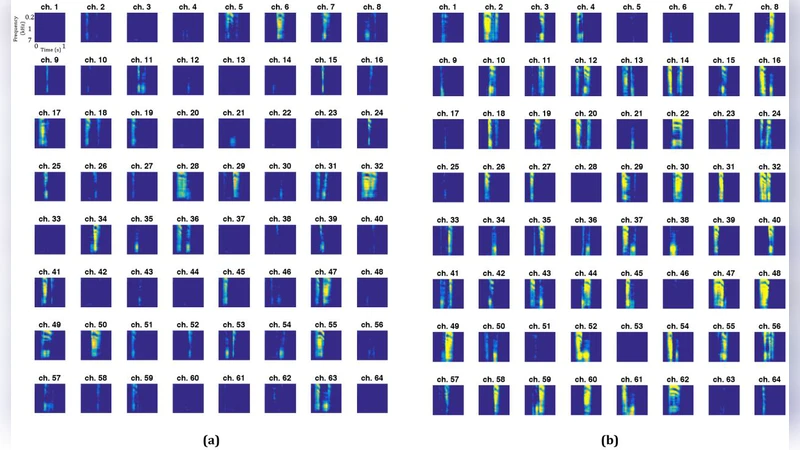
Beyond performance metrics, the authors probed the internal dynamics of the trained WaveNet by feeding each electrode with a synthetic impulse (a single high‑value sample at 500–600 ms, all other time points zero). The model’s output spectrograms—termed “impulse responses”—revealed that specific electrodes generated patterns resembling particular phonemes. For subject 1, electrodes 7, 8, 50, 54, 55 responded to /u:/, /ʃ/, /i/ etc.; for subject 2, electrodes 38–48 showed similar selectivity. These findings align with prior neurophysiological work showing posterior STG (pSTG) neurons encode phonetic feature clusters. The impulse‑response analysis thus provides a novel, data‑driven method to infer phoneme‑level tuning of cortical sites from a deep decoding model.
The study acknowledges several limitations. The small number of subjects and limited stimulus set restrict statistical power and the ability to generalize across speakers or languages. The reconstructed speech, while intelligible for a few words, remains far from natural quality, reflecting insufficient data to fully capture the highly nonlinear mapping between high‑gamma ECoG and acoustic features. Future work should collect larger, more diverse datasets, explore speaker‑independent training, and possibly integrate generative adversarial or diffusion models to improve waveform fidelity.
In conclusion, the paper demonstrates that a parameter‑efficient WaveNet‑style architecture can decode speech spectrograms from STG ECoG recordings even with very limited training data, outperforming both linear and ResNet baselines. Moreover, the model’s impulse‑response analysis uncovers phoneme‑specific tuning in individual electrodes, providing converging evidence for phonetic representations in human auditory cortex. These results advance the feasibility of brain‑computer interfaces for speech restoration and offer a new analytical tool for probing the functional organization of auditory cortex.
Comments & Academic Discussion
Loading comments...
Leave a Comment