Deep Reinforcement Learning for Green Security Games with Real-Time Information
Green Security Games (GSGs) have been proposed and applied to optimize patrols conducted by law enforcement agencies in green security domains such as combating poaching, illegal logging and overfishing. However, real-time information such as footprints and agents’ subsequent actions upon receiving the information, e.g., rangers following the footprints to chase the poacher, have been neglected in previous work. To fill the gap, we first propose a new game model GSG-I which augments GSGs with sequential movement and the vital element of real-time information. Second, we design a novel deep reinforcement learning-based algorithm, DeDOL, to compute a patrolling strategy that adapts to the real-time information against a best-responding attacker. DeDOL is built upon the double oracle framework and the policy-space response oracle, solving a restricted game and iteratively adding best response strategies to it through training deep Q-networks. Exploring the game structure, DeDOL uses domain-specific heuristic strategies as initial strategies and constructs several local modes for efficient and parallelized training. To our knowledge, this is the first attempt to use Deep Q-Learning for security games.
💡 Research Summary
The paper addresses a critical gap in the literature on Green Security Games (GSGs), which have been used to model patrolling problems in domains such as anti‑poaching, illegal logging, and over‑fishing. Existing models assume static patrol routes and ignore the rich stream of real‑time information that field agents actually receive—footprints, camera‑trap alerts, drone observations, etc.—and the subsequent adaptive actions taken by both defenders (rangers) and attackers (poachers). To fill this gap, the authors introduce a new game formulation called GSG‑I (Green Security Game with Real‑Time Information). GSG‑I is an extensive‑form game played on a grid world where each cell represents a geographic location. Two players—a defender and an attacker—move simultaneously each turn. The defender can move in four cardinal directions or stay still, and can also remove attack tools (e.g., snares) or capture the attacker. The attacker moves similarly but additionally decides whether to place an attack tool in the current cell. Each attack tool has a cell‑specific success probability; if it succeeds the attacker gains a reward, otherwise the defender receives a penalty. Both players only observe the opponent’s footprints in the cell they occupy, reflecting limited visibility in dense terrain. The game ends when the defender captures the attacker and removes all tools, or after a fixed horizon T. This model captures the “follow‑the‑footprints” feedback loop that is central to real‑world conservation patrols.
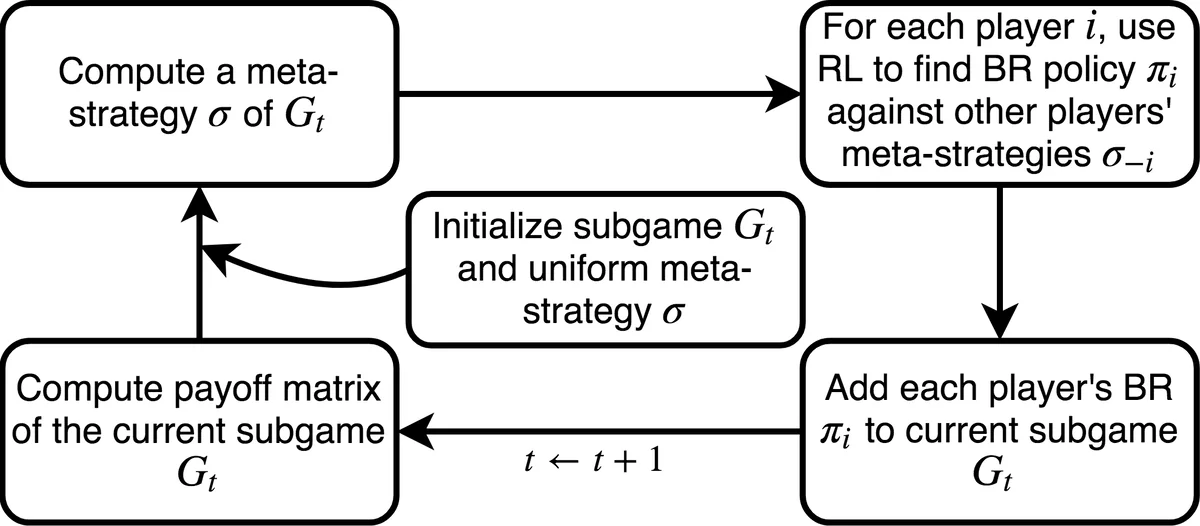
Solving GSG‑I is challenging because the game tree is deep, the information is imperfect, and the action space is large. Traditional solution methods for GSGs—mathematical programming, Stackelberg equilibrium computation, or Counterfactual Regret Minimization (CFR)—either assume static strategies or become intractable on the scale required for GSG‑I. The authors therefore propose DeDOL (Deep‑Q Network based Double Oracle enhanced with Local modes), a novel algorithm that blends the Double Oracle (DO) framework with the Policy‑Space Response Oracle (PSRO) meta‑algorithm, and uses deep reinforcement learning to approximate best‑response strategies.
In DeDOL, each player’s pure strategies are represented by deep Q‑networks (DQNs). The state representation is a 3‑D tensor matching the grid size, with 19 channels encoding (1) attacker footprints (direction and entry/exit), (2) defender footprints, (3) defender’s current location, (4) per‑cell attack‑tool success probabilities, and (5) normalized time step. A convolutional neural network processes this tensor, using two convolutional layers followed by ReLU, max‑pooling, and a dueling architecture to output Q‑values for the five possible movement actions. For policy‑gradient baselines, an actor‑critic variant is also implemented, with gradient clipping to stabilize training.
The algorithm proceeds iteratively. Starting from a small set of domain‑specific heuristic strategies (e.g., random walk, random sweep), DeDOL computes a Nash equilibrium of the restricted game (the current strategy set) using linear programming. It then fixes one player’s equilibrium strategy and trains a DQN to approximate the opponent’s best response against that fixed strategy. The best‑response policy is added to the restricted set, and the process repeats. To mitigate the high computational cost of training deep RL agents for many iterations, the authors introduce “local modes”: the attacker’s entry point is fixed, creating several smaller sub‑games that can be solved in parallel. This decomposition dramatically reduces memory usage and speeds up convergence, especially on larger grids (e.g., 11×11 or 15×15).
Experimental evaluation covers two regimes. In small games (7×7 grid), DeDOL’s defender strategies achieve expected payoffs comparable to those obtained by CFR, confirming that the DQN representation can capture near‑optimal policies despite its compactness. In larger games, CFR fails due to memory exhaustion, while DeDOL continues to learn effective policies. Against baseline strategies (pure random, heuristic sweeps), DeDOL yields substantially higher defender utilities, demonstrating that leveraging real‑time footprints leads to more sophisticated behavior than naïve “follow‑the‑footprint” rules. Ablation studies show that initializing with heuristic strategies and using local modes both contribute to faster convergence and higher final performance.
The paper’s contributions are threefold: (1) a realistic game model that integrates real‑time, partially observable information into green security contexts; (2) a deep‑RL‑enhanced double‑oracle algorithm that can handle the resulting extensive‑form, imperfect‑information game; and (3) empirical evidence that the approach scales to problem sizes where traditional equilibrium‑finding methods are infeasible. The authors suggest future directions such as extending to multiple defenders and attackers, incorporating richer sensor modalities (audio, visual), and validating the framework on real conservation data. Overall, DeDOL represents a significant step toward deploying AI‑driven, adaptive patrol strategies in real‑world environmental protection efforts.
Comments & Academic Discussion
Loading comments...
Leave a Comment