An amplitudes-perturbation data augmentation method in convolutional neural networks for EEG decoding
Brain-Computer Interface (BCI) system provides a pathway between humans and the outside world by analyzing brain signals which contain potential neural information. Electroencephalography (EEG) is one of most commonly used brain signals and EEG recog…
Authors: Xian-Rui Zhang, Meng-Ying Lei, Yang Li
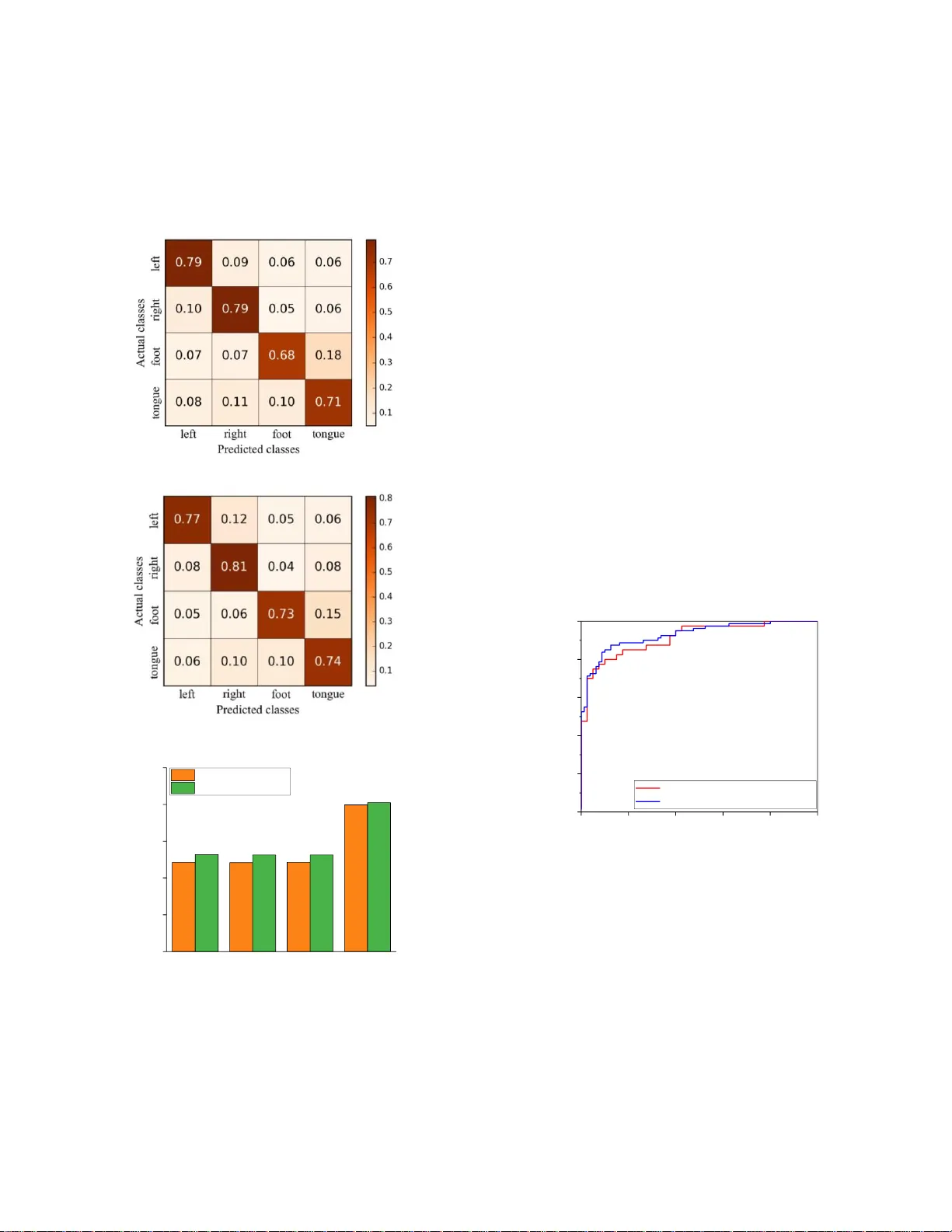
XXX -X-XXXX- XXXX -X/XX/$XX. 00 ©201 8 IEEE An amplitudes-perturbation data augmentation method in convolutional neural networks for EEG decoding Xian-Rui Zhang Department of Automation Sciences and Electrical Engineering Beihang University Beijing, China zhangxianrui89@163.com Meng-Ying Lei Department of Automation Sciences and Electrical Engineering Beihang University Beijing, China LMY_beginner@163.com Yang Li* Department of Automation Sciences and Electrical Engineering Beijing Advanced Innovation Center for Big Data and Brain Computing Beijing Advanced Innovation Center for Big Date-based Precision Medicine Beihang University Beijing, China liyang@buaa.edu.cn Abstract — Brain - Computer Interface (BCI) system provides a pathway b etween humans and th e o utside world by ana lyzing brain signals w hich contain potential neural information . Electroencephalography (EEG) is one of mo st comm only used brain signals and EEG recognition is an important part of BCI system. Recently, convolu tional neural networks (Co nvNet) in deep learning are becom ing the new cutting edge tools to tackle the problem of EEG recognition. However, training an effective deep learning m odel requires a big number of data, w hich li mits the application of EEG datasets w ith a small number of s amples. In order to solve the issue of data insufficiency in deep le arning for EEG decoding , we propose a novel data augmentation method that add perturbations to amplitudes of EEG signals after transform the m to frequency do main. In experiments, we explore the perfor mance of signal recog nitio n with the state- of - the-art models before and after data aug mentation on BCI Competition IV dataset 2a and our local dataset . The results show that our data augmentation technique ca n i mprove the accuracy of EEG recognition effectively. Keywords — data augmen tation, electroencephalography, deep learning, BCI, convolutional neural networks I. I NTRODUCTI ON Electroen cephalog raphy (EEG) is an electr o -phy siological monitoring indicator that can be employed to analyze the sta tes and activities of hum an brains. Traditionally , EEG is acquired by invasive ways, but recent years it is possible to collect EEG with noninvasive approaches [1]. So EEG-based Brain- Computer Interface (BCI) sy stems have gain ed popularity in various real-world applic ations from the healthc are domain to the entertainm ent industry . In healthcare dom ain, EEG signa ls are intr oduced to det ect the org anic brain injury or predict epilepti c sei zure [2]. Some BCI sy stems based on EEG have already allow ing par alyzed patients to inter act w ith wheelchai rs or c ontrol a rob ot through their m otor imagery EEG signals [3 , 4] . Motor imagery EEG is a kind o f signals collecte d wh en a subject imagines perform ing a certain action (e.g., closing eyes or moving feet) but does not make an actual movem ent [5] . As for the entert ainment domain, the EEG signals have been applie d to assisted living, smart hom e , and person i dentifica tion etc. Exploring an effectiv e way to extract robust feature and classify EEG signals effecti vely is an significan t work to applicati ons of EEG. Traditionally , the process of EEG signals recognit ion consists of two sta ges [6] : a fea ture extra ction st age, where meaningf ul information is extracte d from the EEG recording s; a classif ication st age, w here a decis ion is made from the s electe d f eatures [7] . Tradition al f eature extracti on methods mainly include frequen cy band analys is [8] , multiscal e radia l basis functi ons [9] , independent componen t analysis [ 10 ], continu ous wavele t transf orm [ 11 ] , and common spatial p attern algorit hm [ 12 ] etc. In the classifi cation stage, many tr aditiona l a lgorithm s such as support vector machin e (SVM) [ 13 ] and Bayesian classifier [ 14 ] have been employ ed. How ever, these meth ods heavily rely on handcraft ed features, and the feature selection steps are time- consum ing even for expe rts in this domain. Additional ly, such a two-s tage model is inconv enient to t rain an d implem ent. Recently deep learning techniques have gaine d widespread attention and achieve d remarkabl e success in many fields such as computer vision [ 15 ], speech recognition [ 16 ] , natural language processing [ 17 ] etc. Applying deep learning model to complete the featu re extraction task show an apprec iable perform ance as it does n ot req uire any h andcraftin g f eatu re selection st eps. T herefore , its eff ectiveness has encour aged some researchers to adopt deep learning methods to r ecogni ze EEG recor dings. In [5] , An et al . proposed a deep bel ief netw ork (DBN) for classifying Motor imagery EEG and the DBN gained better result than the SVM metho d. I n [ 14 ] , Rezaei et al. a dopted ConvNet to recogniz e EEG af ter converted EEG recordings to images by Short- Ti m e Fourier This wor k was supported by the National Na tu ral Science Foundation of China [61403016, 61671042, and 61773039], Beijing Natural S cience F ou nd - ation [4172037] , and Open Fund Proj ect of Fujian Provi ncial Key Laboratory in Minjiang Unive rsity [MJUKF 201702]. * Corresponding aut hor. *This manuscript has been accepted by ICCSS 201 8. Transform (STFT) [ 18 ] . More recently, Schirrm eister et al. proposed an end- to -en d learning model called Shallow ConvNet which took r aw EEG recordings as in puts [ 19 ] . It enable to learn robust featur e represent ations and classify raw signals simultaneously . However, such an end- to -end ConvNet has more parameters to optimize than traditiona l methods, s o we requi re a large amount of data t o train th is model. For most public EEG datasets such as BCI Competiti on IV dataset 2 a and 2b [ 20 ] , there are only a few hundred sam ples per subject. Thus, if we try to furth er explore deep learni ng models on EEG recognition, ap plying a data aug mentati on technique is the primary issue that needs to be addressed [ 21 ]. Data augmen tation is a te chnique that generate eff ective training samples from origin datasets when we do n ot have sufficien t data to train deep learning model . In this paper we propose a augmen tation meth od inspi red from image processing techn ique . T he augmentation approach es in images processing m ainly include tw o pa rts , geometric t ransform ations and noise additi on. Geom etric transfo rmations , suc h as sh ift, scale, and rotation, are not practical for EEG as it is a dynam ic time series. So we adopt the noise additi on method to augment the EEG samples. However, before apply the noise addition method we must consider these characte rs of EEG recording s. First, EEG sig nals usually have low signal- to -noise ratio and a mass of noises such as eye blinks, muscle activity and heartbeat . S econd, EEG signals lack sufficient spatial resoluti on compared to imag es [ 19 ] . Additi onally , the key inform ation of EEG signals main ly exists in the frequency doma in [ 22 ] . Based o n these knowledge of EEG, w e modify the noise addition methods in image processing an d implem ented a novel data augmentation technique via adding Gaussian perturbation to the amplitudes in the freque ncy domain. Then w e re-implem ent the Shall ow ConvNet propos ed in [ 19 ] and compare its performan ce w ith augmentation an d without augm entation m ethod on one p ublic dataset and one local dataset. The experiment results demonstrate that our Gaussian pe rturbat ion method with pro per param eters can yield significan tly hig her classif ication accuracy on both datase ts. II. P ROPOSED M ETHO D In this s ection, we propose a data au gmentati on method called amplitudes- perturbati on to improve the performan ce o f the Shallow ConvNet model. In the followin g sub-sections we will describ e the data augmen tation method and Shallow ConvNet m odel in deta il. A. Da ta Augmen tation First we describe the notati ons in this paper . Each dataset is separated into labele d trials and each tri al is a tim e segment o f the original recording which b elong to one of several classes . For trial i , the input sample of the model is represente d as 1 2 1 c c c c i t t X X , X , , X , X and the corres ponding label is denoted as i y . In sample i X , each single 1-D vector c t X contains c elem ents acquired from all electrode channels at time index t . The input sample i X is a 2-dimension matrix, which can be arrange d into an “im age” with the number of discretiz ed time ste ps t as the width and the number of electrodes c as the height . Generally training a deep learnin g model needs a b ig amount o f data otherw ise the m odel tends to overfit quickly and is less robust. T he d ata augm entation is a comm only used technique to generate samples from the existin g d ataset in deep learning b ecause it is not time-consu ming compared to collecting new data . The simplest data augmentati on method is adding noise to the EEG signal in time d omain directly. However, considering the characters of EEG such as low signal- to -n oise rati o, non-stat ionarity and insuf ficient s patial resoluti on, this method may destroy EEG signal’s feature in time domain [ 23 ]. So we propose the method that first transform the E EG recordin gs to the frequency dom ain via STFT [ 24 ], then add perturbations to amplitu des in frequency domain , finally reconst ruct the time-series by inverse STF T. As sume that w e are given one training sample i X and its correspon ded l abel i y . First w e denote the tim e-series of one channel as x ( t ). Then tr ansform it to frequency domain by short time Four ier tran sform as bel ow: 2 ( ) ( ) ( ) j ft Z , f x t g t e dt ( 1) where () Z , f is a two-dimens ional complex m atrix represent ing the phase and amplitude of the signal over time and frequen cy f , and () gt is the Hann w indow function centered around zero. () Z , f is a complex matrix so it can also b e rep resented as A co s jA sin , where f A i s the amplitude and f is the phase in every frequency f and tim e index . Then we add Gaussi an -dist ribute d noise () p N , to the am plitude randomly , where is the mean valu e and is the standard deviati on of Gaussian noise. Next, combine the disturbe d am plitude and original phase to generate new complex m atrix as: ( ) ( ) ( ) Z , f A p co s j A p si n (2) where () Z , f is the n ew com plex matr ix, and Ap is the new amplitude aft er ad ding Gaussi an noise . After th at , the new tim e-seri es () xt is r econstructe d by invers e STFT as : 1 ( ) ( ( )) x t ST F T Z , f (3) where 1 ST F T represents the p rocess of inv erse Sho rt-Tim e Fourier Transform . Finally w e apply all the above procedu res to every channel in i X , so w e cr eate a new perturbed training sample i X . Note that the new training sample has same target y i with the origin sample. B. Deep learning model In this pa per, w e use the Shallow ConvNet proposed in [ 19 ] to extract feature representati ons and classif y the EEG signals automatic ally. The model consists of one tem poral convoluti onal lay er, o ne spatial convolutional layer, one meanin g pooling layer, and one classificati on lay er. In the fir st temporal convoluti onal lay er, we utilize 25 convoluti on filte rs across time with a common kernel shape o f (1,11) to capture temporal featur es. T he choice of such a convolu tional kernel will result in preserving the number of channels after the convoluti on operati on and r educing the temporal dimension of the signals . But the temporal co nvolu tional layer d oes not mix the channel signals with each o ther. In order to better handle the large number of input chan nels and m ix the temporal represent ations o f each channel, in the second spat ial convoluti onal layer, 25 con volution filters o f size (22,1) perform sp atial filters with weights for all possible p airs of electrodes to learn spatial features. Usually the tem poral features o f each EEG channels are in dependent, so a comm on linear com bination cannot be shared among the channels and a kernel s ize sm aller than 22 is not idea l. The out put of the spatial convolutiona l layer is the linear combination of all the 22 channels. Then the spatial feature maps are transmitted to the mean pooling layer w ith size (1,3) and stri de (1,3). I n the last classifi cation lay er, glob al convoluti on filte rs are applie d to produce featu re maps with size (1,1) and pass these feature maps to a softm ax classifi er directly , yielding the probabilit y of the input belongin g to ea ch classes. So, in this layer, the number of filters and s oftmax u nits is e qual to class labels . Note that activation function between the t emporal and spatial conv olutional layers is not employed as it can regula rize the overall neural networks in implici tly. Batch normaliza tion, as recomm ended in [ 25 ], is applied to the output of the spatial convoluti onal layers before the exponential linear unit (ELU) function. III. E XPERIMENTS AND R ESULT In this section , we e valuate t he performance of EE G signal recognition on the Shallow ConvNet model be fore and a fter data augmentatio n on BCI Co mpetition IV d ataset 2a and our local dataset. In the training s tage o f the model, it consists of two co mponents: app lying t he a mplitudes-perturbation d ata augmentation technique to t he training d ataset and feedin g the augmented data to train t he Sh allow Con vNet . I n the test s tage , several t ypical metrics are employed to evalua te the performance with and without d ata au gmentation tec hnique , such as accurac y, precis ion, r ecall, F1 score, ROC (Receiver Operating Characteristic) cur ve, and AUC (Area under the curve). T he Mod el Implementation, the result on p ublic dataset, and the result on local dataset are separatel y reported in this section. A. Mod el Implementa tion We randomly select 80% samples from origin training set as new training set and the residual as validation set. All the dataset is divided into batches with the size of 64. The num ber of training iterations is set to 2000. The Adam Algorithm s is adopted to minim ize the cross -entropy lo ss fu nction w ith a learning rate of 0.001. All conv olutional layers have dropout with a p robability of 0.5 [ 26 ]. B. R esult on BCI Comp etition IV dataset 2a The BCI Competit ion IV dataset 2a is a p ublic EEG motor- imagery dataset including 9 sub jects . The brain signals of each subject consist of two sessions which ar e recorded by 22 EEG electrodes according to the 10-20 elec trode config uration. Ea ch session consists of 288 trials of mot or imag ery tasks per subject. The movem ents of m otor imagery include the left ha nd (class 1), the right hand ( clas s 2), both feet (class 3), and the tongue (class 4). For each trial, EEG recordings are recorde d at a sampling rate of 250Hz and l ow-pass filtered to 38 Hz. Subsequently we o btain tri al epochs that starts at 0.5 s b efore the stim ulus onset as in put da ta and corresponding trial la bels (class 1, class 2, class 3 and class 4) as targets . So we extract 288 t raining samples fr om the first session and 288 test samples fr om the s econd sess ion each subject. In this section, we report the perform ance study of Sh allow ConvNet after amplitudes-p erturbati on data augm entation and then d emonstr ate the efficiency of our approach by comparin g with the model trained w ithout augm entation. As a first ste p before moving to th e evalu ation of data argum entation, we validate o ur Shallow ConvNet implementation . We reache d an accuracy of 74%, statistically not signific antly differ ent from the origin research (73.7 %) in [ 19 ]. Then in the data augm entation techniqu e, the mean value of Gaussian Nois e is set to 0 in ord er t o ensure th e amplitude intensity not be changed. T hen we set the standard deviati on to 0.0001, 0.0005, 0.001, 0.002, 0 .005 and 0.01 respectively , for purpose of exploring the effect of different standa rd deviations on the perform ance of Shallow ConvNet. Fig. 1 show s the recogniti on accuracies with Gauss noise of different standa rd deviati ons . The dashed line indicat es the accur acy 74% w ithout augm entation using Shallow ConvNet in [ 19 ]. From Fig. 1, we find that the standard deviation of Gaussian Noise can impact the perform ance of Shallow ConvNet effectively . If the standard deviation is too small or too large, we even get worse perform ance than the model without augmentation. When the standard deviati on is set to 0.001, the model can achieve the best accu racy of 76.3% on f our class es data . 0.704 0.743 0.763 0.743 0.716 0.705 0.0001 0.0005 0.001 0.002 0.005 0.01 0.60 0.65 0.70 0.75 0.80 0.74 accuracy standard deviation without augmentation (0.74) Fig. 1. The acc uracy of Sha llow ConvNet using data augmentation with different standar d deviations. The dashed line indicates the accuracy of training w ithout data augmentatio n. In late r exper iments, we set th e mean value to 0 and the standard deviation to 0.0 01 and note them as the best data augm entation p aramete rs. In order to take a closer look at the result, the detailed confusion matrix, and o ther metrics of the model’s performance are illustrated in Fig. 2, Fig 3 and Fig. 4 respective ly. In th e co nfusion m atrix of Fig. 2 and F ig. 3, the row represents the predicted classes r , the column represents the actual class es c . Each num ber in ro w r and colum n c denotes the r atio of t arget c predicte d as class r . The diagon al correspon ds to c orrectly predicted trials of th e f our cl asses. Colors indi cate fract ion of trials in this cel l from all trials of the correspon ding row. The figure clearly depicts that for the classes of feet and tongue, our appro ach improve efficiently . In Fig. 4, we co mpare these two models in other metrics . It is observed that the perform ance can be improved obviously by our amplitudes-p erturbation d ata augmentati on method in precisi on, recall, F1 and A UC. C. Result on Local EEG Da taset In this s ection , we evaluate the performance of Shall ow ConvNet on o ur local dataset for demonstrating the good adaptabil ity of the amplitu des-pertur bation data augm entation technique. First, a brief descri ption of the local dataset is given below. T he local d ataset is collected w hen the sub jects are shown images of differ ent scenery with the appearan ce tim e lasting 1s of one im age. T he shown images either contain an airplane (ta rget), or no airplane(n on-target). Par ticipants are instructe d to press a button when a target image is shown. The number of imag es with target and n on-target is equal . When analyze the EEG sig nals, the P300 event-re lated potential is one of the strongest neural response to novel v isual stimu li. S o we can apply the Shallow ConvNet to recognize EEG tri als with target from trials w ith non -target according to the P300 waveform . Compared to the public datas et BCI Com petition IV 2a, our local dataset has tw o class lab els and it is acquir ed from 64 channels at the sam pling rate of 1000 Hz. We extract 320 training samples and 80 test samples from the local dataset . When evaluate on our d ataset , t he experimen t setting and the paramete rs are same as we use on B CI Competit ion IV dataset 2a . Th en w e train the Shall ow Conv Net with data augm entation technique and it reachs the accur acy of 88.75%, which is higher than the accuracy with out using d ata augm entation (85.0%). The ROC curves of the tw o models are shown in Fig. 5. We can see that the curve with d ata augm entation is above the curve with out data augm entation . So the AUC (area under the curve) value with data augmentati on (0.93) is also higher than the value without data augmentati on (0.91) . It il lustrates that the perform ance of the m odel with data augm entation is better than without data augmentation . In Table I, we list the precision, recall and f1 score o f the model with and without augmen tation. T he improvem ent of the value with augm entation over without augm entation is obviously . It demonstrates that our data augmentation technique still achieves good performance an d has g ood adapta bility when it is appli ed to oth er datase t. Fig. 2 Confusion ma trix of training w ithout data augmentation. Fig. 3 Confusion ma trix of training w ith data augmentat ion. 0.743 0.742 0.743 0.899 0.764 0.763 0.763 0.905 precision recall F1 AUC 0.5 0.6 0.7 0.8 0.9 1.0 accuracy without augmentation with augmentation Fig. 4 Precision, recall, F1 and AU C of mo del with and w ithout data augmentation. 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 True Positive Rate False Positive Rate without augmentation (AUC=0.91) with augmentation (AUC=0.93) Fig. 5. ROC curves of the result with and wit hout augmentatio n. TABLE I . THE PRECISION , RECALL AND F1 SCORE OF THE MODEL WITH AND WITHOUT DATA AUGMEN TA TION method precision recall F1 without augmentatio n 85.4% 85.0% 0.845 with augmentatio n 89.0% 88.8% 0.887 IV. C ONCL USION In this paper we present an amplitudes-pertu rbation method for EEG data augm entation. It yiel ds signific antly b etter perform ance on BCI Competition IV dataset 2a and our local dataset. Fi rst we explor e the im pact of standard deviat ion to th e accuracy of Shallow ConvNet. T hen we apply the best data augm entation parameters to train Shallow ConvNet and gain 2.3% higher accuracy than the model without amplitu des- perturbati on on BCI Competit ion IV dataset 2a . Furthe rmore , the local dataset is employ ed to evaluate the adaptabili ty of this proposal. The results show that the amplitud es-perturbat ion is a powerful method to improve the performance of deep learning models wh en training data is insuf ficient. Our future work will concentrat e on improving the accuracy by other d ata augm entation meth ods, such a s generativ e adversarial netw orks [ 27 ] and the v ariati onal autoen coder [ 28 ]. R EFERENCES [1] M . Ahn, M. Lee, J. Choi, and S. Jun, "A Review of B rain-Computer Interface Games and an Opinion S urvey from Researcher s, Devel opers and Users," Senso rs, vol. 14, p. 14 601, 2014. [2] Y. L i, X. D. Wang, M. L. Luo, K. L i, X. F . Yang, and Q. Guo, "Epileptic Seizure Classification of EEGs Using Time-Frequency Analysis Based Multiscale Radial B asis Functions," IEEE Journal of Biomedical an d Health Infor matics, vol. 22, pp. 386-397, 2018. [3] S. Qiu, Z. Li, W. He, L. Zhang, C. Yang, and C. Y. Su, "Brain-Machine Interface and Visual Compre ssive Sensing -Based Teleope ration Control of an Exoskeleton Robot," I EEE Transactions on Fuzzy Syste ms, vol. 25, pp. 58-69, 2017. [4] Y. Li, J. Pan, F. Wang, and Z. Yu, "A Hybrid BCI System Combini ng P300 a nd SSV EP and Its Application to W heelchair Control," I EEE Transactions on Biomedical Engine ering, vol. 60, pp. 3156-3166, 2013. [5] X. An, D. Kuang, X. G uo, Y . Z hao, and L. He, "A Deep L earning Method for Classification of EEG Data Based on Motor Imagery," in International Co nference o n Intelligent Computi ng, 2014, pp. 20 3 -210. [6] Y. Li, H.-L. Wei, S. A. B illings, and P. G. Sarrigiannis, "Time-varying model identification for time – frequency feature extraction from EEG data," Journal o f Neuroscience Methods, vol. 196, pp. 151-158, 2011. [7] Y. L i, W. Cui, M. Luo, K. Li, and L . Wang, "Epi leptic Seizure Detection Based on Time-Frequency Image s of EEG Signals using Gaussian Mixture Model and Gray Level Co-Occurrence Matrix Features," I nternational Journal of Neural Systems, pp. 1-17, 2018. [8] J. -A. Martinez-Leon, J.-M. Cano-I zquierdo, and J . Ibarro la, "Feature Selection Apply ing Statistical and Ne urofuzzy Methods to EEG-Based BCI," Computational Intelligence and Neuro science, vol. 2 015, p . 17, 2015. [9] Y. L i, Q. L iu, S.-R. Tan, and R. H. M. Chan, "High-resolution time- frequency a naly sis of EEG signals using multiscale radial basis functions," Neuroco mputing, vol . 195, pp. 96-103, 2016. [10] M. P. Hosseini, D. Pom pili, K. Elisevich, and H. Soltanian-Zadeh, "Optimized Deep Learning for EEG B ig Data and Seizure Prediction BCI via Interne t of Things," IEEE Tr ansactions on Big Data, vol. 3, pp. 392-404, 2017. [11] Y. Li, W .-G. Cui, M.-L. L uo, K. Li, and L. Wang, "High -resol ution time – frequency representation of EEG da ta using multi-sca le wavelets," International Jour nal of Sy stems Science, vol. 4 8, pp. 2658-2668, 2017. [12] P. Legrand, M . C havent, and L . Trujillo, "EEG classification for the detection of mental states," Applied Soft Computing, vol. 32, pp. 113 - 131, 2015. [13] L. Wang, W. Xue, Y. L i, M. Luo, J. Huang, W. Cui, et al., "Automati c Epileptic Seizure Detection in EE G Signals Using Multi-Domain Feature Extraction and Nonlinear Analy sis," Entropy, vol. 19, p. 222, 2017. [14] T. Yousef Rez aei an d H. Ugur, "A novel deep lear ning approa ch for classification of EEG motor image ry signals," Journ al of Neural Engineering, vo l. 14, 2017. [15] K. He , X. Zhang, S . Ren, and J. Sun, "Deep Residual L earning for Image Recognition," in Computer Vision and Pattern Recognitio n, 2016, pp. 770-778. [16] O. A bdel-Hamid, A. R. Mohamed, H. Jiang, L. Deng, G. Penn, and D . Yu, "Convol utional Neural Networks for Speech Recognition," IEEE/A CM Transactions on Audio Spee ch & Language Processing, vol. 22, pp. 1533-1545, 2014. [17] E. d. S. Ma ldona do, E. Shihab, and N . T santalis, "Using Natu ral Language Processing to A utomatically Detect Sel f-Admitted Technical Debt," I EEE Transactions on Softw are En gineering, vol. 43, pp. 1044 - 1062, 2017. [18] Y. Li, M.-L. Luo, and K. Li, "A multiwavelet-based time-varying model identification approach for time – frequen cy analysis o f EEG signals," Neurocomputi ng, vol. 193, pp. 106-114, 2016. [19] R. T. Schirrmeister , J. T. Springenberg, L. D. J. Fieder er, M. Glasste tter, K. Eggensperg er, M. Tangermann, et al., "Dee p learning with convolutional neural netw orks for EEG decoding and visualization," Human Brain Ma pping, vol. 38, p p. 5391-5420, 2017. [20] A. K. Keng, C. Z. Yang, C. Wang, C. Guan, and H. Zhang, "Filter Bank Common Spatial Pattern Alg orithm on BCI Competition IV Datasets 2a and 2b," Fr ontiers in Neuroscien ce, vol. 6, p. 39, 2012. [21] J. Ding, B. Che n, H. Liu, and M . Huang, "Convo lutional Neural Network With Data Augmentatio n for SAR Target Recognition," IEEE Geoscience & Remote Se nsing Letters, vol . 13, pp. 364-368, 2016. [22] Y. Li, W. G. C ui, Y. Z. Guo, T. Huang, X. F. Yang , and H. L. Wei, "Time- Varying System Identification Usin g an Ultra -Orthogonal Forward Regression and Multiw avelet B asis Functions With Applications to EEG," IEEE Transactions o n Ne ural Networks and Learning Sy stems, pp. 1-13, 2018. [23] Y. Hao, M. K. Hui, N. V. Ellenrie der, N. Zazubovits, and J. Gotman, "DeepI ED: An epileptic discharge detector for EEG -fMRI b ased on deep learning," Ne uroimage Clin ical, vol . 17, pp. 962 -975, 2018. [24] Y. L i, H.- L. We i, S. A. Billings, and P. G. Sarrigiannis, "Identificatio n of nonlinear ti me-vary ing systems using an online sliding-window and common mode l structure sel ection (CMSS) approach with applications to EEG," International Journal of Systems Sci ence, vol. 47, pp. 2671 - 2681, 2016. [25] S. I offe and C. Szeg edy, "Batch normalization: accelerating dee p networ k t raining by reducing internal covariate shift," in I nternational Conference o n Machine L earning, 2015, pp. 448-456. [26] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, "Dropout: a simple way to prevent n eural networks from overfitting," Journal of Machine Learning Research, vol. 15, pp. 1929- 1958, 2014. [27] S. Palazzo, C. Spampinato, I. Kavasidis, D. Giordano, and M. Shah, "Gener ative Adve rsarial N etworks Con ditioned by Brain Signals," in IEEE I nternational Confere nce on Computer Vision, 2017, pp. 3 430- 3438. [28] A. B . L. Larsen, H. L arochelle, and O. Winther, "Autoencoding beyond pixels using a learned similarity metric," in International Conference on Machine L earning, 2016, pp. 1 558-1566.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment