Kernel Machines Beat Deep Neural Networks on Mask-based Single-channel Speech Enhancement
We apply a fast kernel method for mask-based single-channel speech enhancement. Specifically, our method solves a kernel regression problem associated to a non-smooth kernel function (exponential power kernel) with a highly efficient iterative method…
Authors: Like Hui, Siyuan Ma, Mikhail Belkin
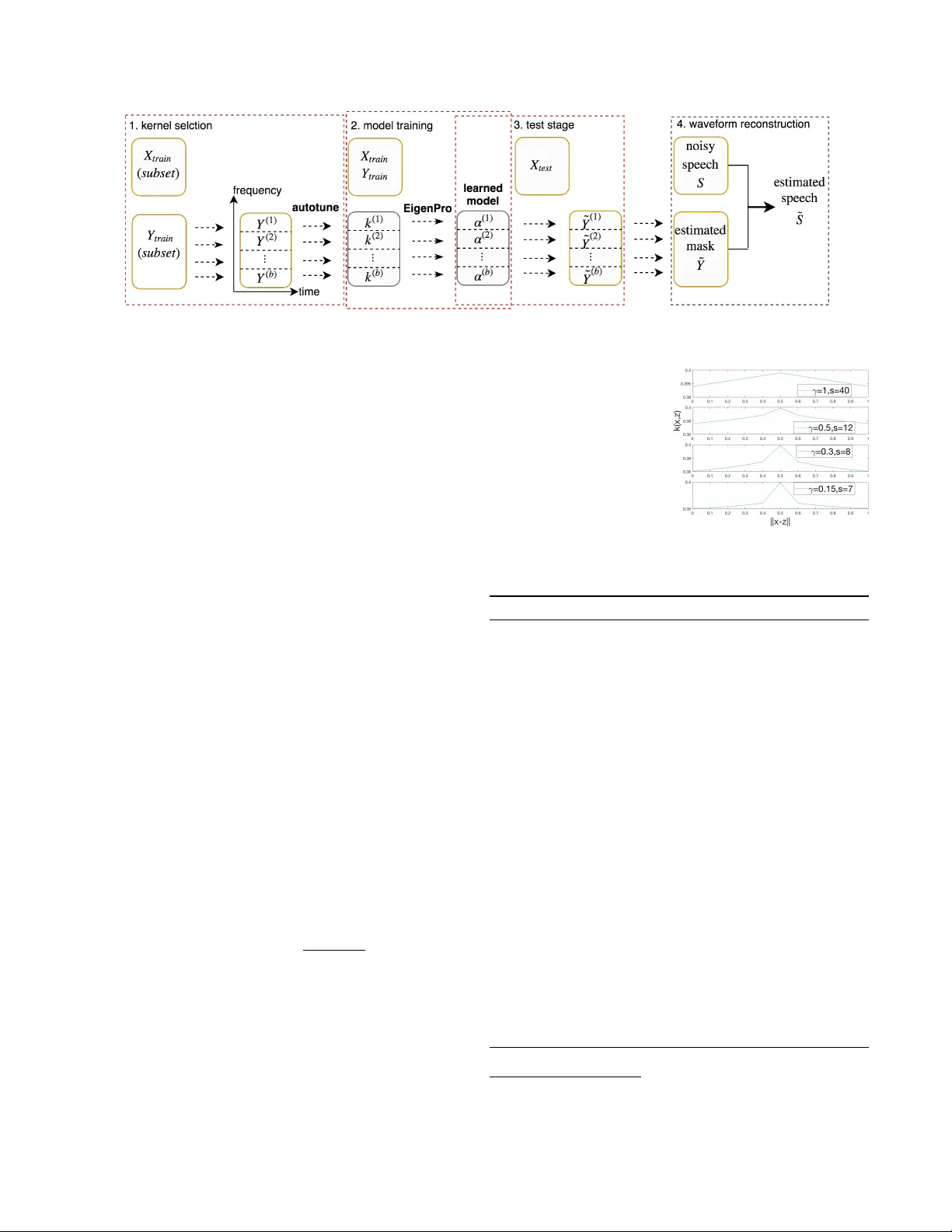
KERNEL MA CHINES BEA T DEEP NEURAL NETWORKS ON MASK-B ASED SINGLE-CHANNEL SPEECH ENHANCEMENT Like Hui, Siyuan Ma, Mikhail Belkin Department of Computer Science and Engineering, The Ohio State Uni versity , USA hui.87@osu.edu, { masi, mbelkin } @cse.ohio-state.edu ABSTRA CT W e apply a fast kernel method for mask-based single-channel speech enhancement. Specifically , our method solv es a kernel regression problem associated to a non-smooth kernel func- tion (exponential po wer kernel) with a highly efficient itera- tiv e method (EigenPro). Due to the simplicity of this met hod, its hyper-parameters such as kernel bandwidth can be auto- matically and efficiently selected using line search with sub- samples of training data. W e observe an empirical correla- tion between the regression loss (mean square error) and reg- ular metrics for speech enhancement. This observ ation justi- fies our training target and moti vates us to achie ve lo wer re- gression loss by training separate kernel model per frequency subband. W e compare our method with the state-of-the-art deep neural networks on mask-based HINT and TIMIT . Ex- perimental results show that our kernel method consistently outperforms deep neural networks while requiring less train- ing time. Index T erms — large-scale kernel machines, deep neu- ral netw orks, speech enhancement, e xponential po wer kernel, automatic hyper-parameter selection 1. INTR ODUCTION The challenging problem of single-channel speech enhance- ment has receiv ed significant attention in research and ap- plications. In recent years the dominant methodology for addressing single-channel speech enhancement has been based on neural networks of different architectures [1, 2]. Deep Neural Networks (DNNs) present an attractiv e learn- ing paradigm due to their empirical success on a range of problems and efficient optimization. In this paper , we demonstrate that modern large-scale ker - nel machines are a powerful alternativ e to DNNs, capable of matching and surpassing their performance while utilizing less computational resources in training. Specifically , we tak e the approach to speech enhancement based on the Ideal Bi- nary Mask (IBM) and Ideal Ratio Mask (IRM) methodology . The first application of DNNs to this problem was presented in [3], which used a DNN-SVM (support vector machine) system to solve the classification problem corresponding to estimating the IBM. [4] compared different training targets including IRM. [5] proposed a regression-based approach to estimate speech log po wer spectrum. Recently , [6] applies re- current neural networks to similar mask-based tasks and [7] applies con v olutional networks to the spectrum-based tasks. Kernel-based shallo w models (which can be interpreted as two-layer neural networks with a fixed first layer), were also proposed to deal with speech tasks. In particular, [8] gav e a kernel ridge regression method, which matched DNN on TIMIT . Inspired by this w ork, [9] applied an efficient one- vs-one kernel ridge regression for speech recognition. [10] dev eloped kernel acoustic models for speech recognition. No- tably , these approaches require large computational resources to achiev e performance comparable to neural networks. In our opinion, the computational cost of scaling to larger data has been a major factor limiting the success of these methods. In this work we apply a recently de veloped highly efficient kernel optimization method EigenPro [11], which al- lows k ernel machines to handle large datasets. W e conduct experiments on standard datasets using mask- based training target. Our results sho w that, with EigenPro it- eration, kernel methods can consistently outperform the per- formance of DNN in terms of the target mean square error (MSE) as well as the commonly used speech quality ev alua- tion metrics including perceptual ev aluation of speech quality (PESQ) and short-time objectiv e intelligibility (ST OI). The contributions of our paper are as follo ws: 1. Using modern kernel algorithms we show performance on mask-based speech enhancement surpassing that of neural networks and requiring less training time. 2. T o achieve the best performance, we use exponential power k ernel, which, to the best of our kno wledge, has not been used for regression or classification tasks. 3. The simplicity of our approach allows us to de velop a nearly automatic hyper-parameter selection procedure based on target speech frequenc y channels. The rest of the paper is organized as follo ws. Section 2 in- troduces our proposed kernel-based speech enhancement sys- tem: kernel machines, exponential power kernel, automatic hyper-parameter selection for subband adaptiv e kernels. Ex- perimental results and time complexity comparisons are dis- cussed in Section 3. Section 4 gives the conclusion. Fig. 1 : Kernel-based speech enhancement frame work 2. KERNEL-B ASED SPEECH ENHANCEMENT 2.1. Ker nel Machines The standard kernel methods for classification/regression de- note a function f that minimizes the discrepancy between f ( x j ) and y j , gi ven labeled samples ( x j , y j ) j =1 ,...,n where x j ∈ R d is a feature vector and y j ∈ R is its label. Specifically , the space of f is a Reproducing Kernel Hilbert Space H associated to a positiv e-definite kernel func- tion k : R d × R d → R . W e typically seek a function f ∗ ∈ H for the following optimization problem: f ? = argmin f ( x x x j )= y j ,j =1 , 2 ,...,n k f k H , (1) According to the Representer Theorem [12], f ∗ has the form f ( x ) = n X j =1 α j k ( x , x j ) , (2) T o compute f ∗ is equiv alent to solve the linear system, K α = ( y 1 , · · · , y n ) T , (3) where the kernel matrix K has entry [ K ] ij = k ( x x x i , x x x j ) and α α α , ( α 1 , · · · , α n ) T is the representation of f under basis { k ( · , x x x 1 ) , · · · , k ( · , x x x n ) } . 2.2. Exponential Po wer Ker nel W e use an e xponential power k ernel of the form k γ ,σ ( x , z ) = exp ( − k x − z k γ σ ) (4) for our kernel machine, where σ is the kernel bandwidth and γ is often called shape parameter . [13] shows that the e xponen- tial power kernel is positive definite, hence a valid reproduc- ing kernel. This kernel also covers a large family of reproduc- ing kernels including Gaussian kernel ( γ = 2 ) and Laplacian kernel ( γ = 1 ). W e observe that in many noise settings of speech enhancement, the best performance is achie ved using this kernel with shape parameter γ ≤ 1 , which is highly non-smooth. In the right side figure, we plot this kernel function with parameters that we use in our experiments. W e hav e not seen an y ap- plication of this k ernel (with γ < 1 ) in super- vised learning literature. 2.3. A utomatic Subbands Adaptive K ernels Algorithm 1 Automatic hyper-parameter selection 1 Input : D train , D val : training and v alidation data, Γ : a set of γ for the exponential power kernel, σ l , σ h : smallest and largest bandwidth Output : selected kernel parameters γ opt , s opt for D train procedur e autotune( D train , D val , Γ , σ l , σ h ) define subprocedur e cross-validate ( γ , σ ) as: train one kernel model with k γ ,σ on D train using EigenPro iteration, return its loss on D val . for γ in Γ do σ γ = search ( cross-validate ( γ , · ) , σ l , σ h ) γ opt , σ opt ← argmin γ ∈ Γ ,σ γ cross-validate ( γ , σ γ ) retur n γ opt , σ opt procedur e search( f , σ l , σ h ) if ( σ h − σ l ≤ 2 ) then retur n σ l select σ m 1 , σ m 2 ∈ ( σ l , σ h ) compute f ( σ l ) , f ( σ m 1 ) , f ( σ m 2 ) , f ( σ h ) switch min { f ( σ l ) , f ( σ m 1 ) , f ( σ m 2 ) , f ( σ h ) } do case f ( σ l ) : return search ( f , σ l , σ m 1 ) case f ( σ m 1 ) : return search ( f , σ l , σ m 2 ) case f ( σ m 2 ) : return search ( f , σ m 1 , σ h ) case f ( σ h ) : return search ( f , σ m 2 , σ h ) 1 W e apply memoization technique for computing cross-v alidate ( · , · ) . W e first attempt to set σ m 1 , σ m 2 as a value that is already used in ( σ l , σ h ) , then we choose them to split ( σ l , σ h ) into three parts as equal as possible. T able 1 : Kernel & DNN on TIMIT : (MSE: lo west is best, STOI and PESQ: highest is best. Best results bolded.) Noise Metrics 5 dB 0 dB -5 dB T ype K ernel DNN Noisy K ernel DNN Noisy K ernel DNN Noisy Engine MSE ( · 10 − 2 ) 1.10 1.41 - 1.34 1.86 - 1.17 1.82 - STOI 0.91 0.90 0.80 0.86 0.85 0.68 0.80 0.77 0.57 PESQ 2.77 2.77 1.97 2.51 2.45 1.66 2.19 2.16 1.41 Babble MSE ( · 10 − 2 ) 3.34 3.49 - 4.18 4.37 - 4.94 5.43 - STOI 0.86 0.86 0.77 0.77 0.77 0.66 0.64 0.64 0.55 PESQ 2.54 2.52 2.08 2.12 2.10 1.73 1.70 1.61 1.42 SSN MSE ( · 10 − 2 ) 1.35 1.53 - 1.48 1.67 - 1.60 1.76 - STOI 0.88 0.88 0.81 0.82 0.82 0.69 0.74 0.74 0.57 PESQ 2.68 2.66 2.05 2.36 2.32 1.75 2.03 2.00 1.48 Oproom MSE ( · 10 − 2 ) 1.44 1.85 - 1.34 1.86 - 1.17 1.82 - STOI 0.88 0.88 0.79 0.84 0.83 0.70 0.79 0.76 0.59 PESQ 2.80 2.79 2.16 2.50 2.47 1.78 2.23 2.12 1.40 Factory1 MSE ( · 10 − 2 ) 2.51 2.53 - 2.52 2.55 - 2.71 2.77 - STOI 0.86 0.86 0.77 0.78 0.79 0.65 0.68 0.68 0.54 PESQ 2.56 2.51 1.99 2.20 2.23 1.62 1.79 1.77 1.29 As empirically shown in Section 3.3, we see that models with lower MSE at ev ery frequency channel consistently out- perform other models in STOI. This moti vates us to achie ve lower MSE for all frequency channels by tuning kernel pa- rameters for each of them. In practice, we split the band of frequency channels into sev eral blocks , which we call sub- band s. W e propose a simple kernel-based frame work as depicted in Fig. 1 to achiev e automatic parameter selection and fast training for each subband. For i -th subband, the framework learns one model f ( i ) related to an exponential power kernel k ( i ) with parameters automatically tuned for this subband, f ( i ) ( x ) = n X j =1 α ( i ) j k ( i ) ( x , x j ) . (5) Our framew ork starts by splitting the training targets Y train into subband targets Y (1) , · · · , Y ( b ) . For training data re- lated to the i -th subband ( X train , Y ( i ) ) , we perform fast and automatic kernel parameter selection using autotune (Algo- rithm 1) on its subsamples, which selects one exponential power kernel k ( i ) for this subband. W e then train a kernel model on ( X train , Y ( i ) ) with k ernel k ( i ) using EigenPro itera- tion proposed in [11]. It learns an approximate solution α ( i ) (or f ( i ) ) for the optimization problem (1). Our final kernel machine is then formed by { f (1) , · · · , f ( b ) } . For any unseen data x x x , our kernel machine first computes estimated mask f ( i ) ( x x x ) for each subband. Then it combines the results of { f (1) ( x x x ) , · · · , f ( b ) ( x x x ) } to obtain the estimated mask for all frequency channels. Applying this mask to the noisy speech produces the estimated clean speech. 3. EXPERIMENT AL RESUL TS W e use kernel machines with 4 subbands (block of frequen- cies) for speech enhancement. For fair comparison, we train both kernel machines and DNNs from scratch using the same features and targets. W e halt the training for any model when error on validation set stops decreasing. Experiments are run on a serv er with 128GB main memory , two Intel Xeon(R) E5- 2620 CPUs, and one GTX T itan Xp (Pascal) GPU. 3.1. Regression T ask W e compare kernel machines and DNNs on a speech en- hancement task described in [4] which is based on TIMIT corpus [14] and uses real-valued masks (IRM). W e follow the description in [4] for data preprocessing and DNN con- struction/training. W e consider fi ve background noises: SSN, babble, a factory noise (factory1), a destroyer engine room (engine), and an operation room noise (oproom). Every noise is mixed to speech at − 5 , 0 , 5 dB Signal-Noise-Ratio (SNR). T able 1 reports the MSE, STOI, and PESQ on test set for kernel machines and DNNs. W e also present the STOI and PESQ of the noisy speech without enhancement. F or all noise settings, we see that kernel machines consistently produce better MSE, in many cases significantly lower than that from DNNs, which is also the training objective for both models. W e also see that STOI and PESQ of k ernel machines are consistently better than or comparable to that from DNNs with only one exception (F actory1 0dB). 3.2. Classification T ask W e train kernel machines and DNNs for a speech enhance- ment task in [15] which is based on HINT dataset and adopts binary masks (IBM) as targets. W e follow the same procedure described in [15] to preprocess the data and construct/train DNNs. Specifically , we use two background noises, SSN and multi-talker babble. SSN is mixed to speech at -2, -5, -8dB SNR, and babble is mixed to speech at 0 , − 2 , − 5 dB SNR. As our kernel machine is designed for regression task, we use a threshold 0 . 5 to map its real-value prediction to binary target { 0 , 1 } . T able 2 : Kernel & DNN on HINT Metrics Model Babble SSN 0dB -2dB -5dB -2dB -5dB -8dB Acc DNN 0.90 0.91 0.90 0.91 0.91 0.92 Kernel 0.92 0.92 0.91 0.92 0.90 0.89 STOI DNN 0.83 0.80 0.76 0.79 0.76 0.74 Kernel 0.86 0.83 0.78 0.81 0.75 0.71 In T able 2, we compare the classification accuracy (Acc) and STOI of kernel machine and DNNs under different noise settings. W e see that our kernel machines outperform DNNs on noise settings with babble and perform worse than DNN on noise settings with SSN. In all, the proposed kernel machines match the performance of DNNs on this classification task. 3.3. Single Ker nel and Subband Adapti ve K ernels W e start by analyzing the performance of kernel machines that use a single kernel for all frequency channels on the re- gression task in Section 3.1. The training of such kernel ma- chine (1 subband) is significantly faster than that of our de- fault kernel machine (4 subbands). Remarkably , its perfor- mance is also quite competiti ve. It consistently outperforms DNNs in MSE in all noise settings. In 8 out of 15 noise set- tings, it produces STOI the same as that from the kernel ma- chine with 4 subbands (it also produces nearly same PESQ). T able 3 : Comparison of kernel machines with 1 subband and 4 subbands Noise setting Metrics Kernel (1 subband) Kernel (4 subbands) DNN SSN 0dB MSE 1.60 1.48 1.67 STOI 0.81 0.82 0.82 PESQ 2.35 2.36 2.32 SSN -5dB MSE 1.67 1.60 1.76 STOI 0.73 0.74 0.74 PESQ 2.01 2.03 2.00 Factory1 -5dB MSE 2.76 2.71 2.77 STOI 0.67 0.68 0.68 PESQ 1.78 1.79 1.77 Howe ver , in other noise settings, kernel (1 subband) has smaller training loss (MSE) than DNNs, but no better STOI (we sho w three cases in T able 3) [16, 17]. T o impro ve desired metrics (STOI/PESQ), we first compare the MSE of ev ery fre- quency channel of DNNs and kernel machines. (a) Engine -5dB (b) SSN 0dB Fig. 2 : MSE along per frequency channel As shown in Fig. 2a, for cases that kernels have much smaller overall MSE and smaller MSE on each frequency channel, k ernels also achieve better STOI. For cases like SSN 0dB, as shown in Fig. 2b, e ven though single kernel (1 sub- band) has smaller ov erall MSE, its STOI is not as good as DNNs. Multiple kernels (4 subbands) decrease MSE further and also achiev e better STOI. This sho ws that having smaller MSE along all frequency channels leads to better STOI. This rev eals a correlation between MSE and STOI/PESQ associ- ated with frequency channels. 3.4. Time Complexity T able 4 : Running time/epochs of Kernel & DNN Dataset T ime (minutes) Epochs Kernel DNN Kernel DNN 1 subband 4 subbands HINT 0.8 3.2 6.6 10 50 TIMIT 18 65 124 5 93 In T able 4, we compare the training time of DNNs and kernel machine on both HINT and TIMIT . Note that the train- ing of kernel machines in all experiments typically completes in no more than 10 epochs, significantly less than the number of epochs required for DNNs. Furthermore, the training time of kernel machines is also less than that of DNNs. Notably , training kernel machine with 1 subband takes much less time than DNNs. 4. CONCLUSION In this paper , we ha ve shown that kernel machines using ex- ponential power kernels show strong performance on speech enhancement problems. Notably , our method needs no pa- rameter tuning for optimization and employs nearly automatic tuning for kernel hyper-parameter selection. Moreov er , we show that the training time and computational requirement of our method are comparable or less than those needed to train neural networks. W e expect that this highly efficient kernel method will be useful for other problems in speech and signal processing. 5. REFERENCES [1] DeLiang W ang and Jitong Chen, “Supervised speech separation based on deep learning: An ov erview , ” IEEE/A CM T ransactions on Audio, Speech, and Lan- guage Pr ocessing , vol. 26, no. 10, pp. 1702–1726., 2018. [2] Zixing Zhang, J ¨ urgen Geiger, Jouni Pohjalainen, Amr El-Desoky Mousa, W enyu Jin, and Bj ¨ orn Schuller , “Deep learning for en vironmentally rob ust speech recognition: An ov ervie w of recent dev elopments, ” A CM T ransactions on Intelligent Systems and T ec hnol- ogy (TIST) , vol. 9, no. 5, pp. 49, 2018. [3] Y uxuan W ang and DeLiang W ang, “T o wards scaling up classification-based speech separation, ” IEEE T ransac- tions on Audio, Speech, and Language Pr ocessing , vol. 21, no. 7, pp. 1381–1390, 2013. [4] Y uxuan W ang, Arun Narayanan, and DeLiang W ang, “On training targets for supervised speech separation, ” IEEE/A CM T ransactions on Audio, Speec h and Lan- guage Pr ocessing , v ol. 22, no. 12, pp. 1849–1858, 2014. [5] Y ong Xu, Jun Du, Li-Rong Dai, and Chin-Hui Lee, “ A regression approach to speech enhancement based on deep neural netw orks, ” IEEE/ACM T ransactions on Au- dio, Speech and Language Pr ocessing , vol. 23, no. 1, pp. 7–19, 2015. [6] Zhong-Qiu W ang and DeLiang W ang, “Recurrent deep stacking networks for supervised speech separation, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Conference on . IEEE, 2017, pp. 71–75. [7] Ashutosh Pandey and Deliang W ang, “ A new frame- work for supervised speech enhancement in the time do- main, ” Pr oc. Interspeech 2018 , pp. 1136–1140, 2018. [8] Po-Sen Huang, Haim A vron, T ara N Sainath, V ikas Sindhwani, and Bhuvana Ramabhadran, “Kernel meth- ods match deep neural netw orks on timit., ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 , 2014, pp. 205–209. [9] Jie Chen, Lingfei W u, Kartik Audhkhasi, Brian Kings- bury , and Bhuvana Ramabhadrari, “Ef ficient one-vs- one kernel ridge regression for speech recognition, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2016 IEEE International Conference on . IEEE, 2016, pp. 2454–2458. [10] Zhiyun Lu, Dong Quo, Alireza Bagheri Garakani, K uan Liu, A vner May , Aur ´ elien Bellet, Linxi Fan, Michael Collins, Brian Kingsbury , Michael Picheny , and Fei Sha, “ A comparison between deep neural nets and kernel acoustic models for speech recognition, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2016 IEEE In- ternational Confer ence on . IEEE, 2016, pp. 5070–5074. [11] Siyuan Ma and Mikhail Belkin, “Learning kernels that adapt to gpu, ” arXiv pr eprint arXiv:1806.06144 , 2018. [12] Bernhard Sch ¨ olkopf, Alexander J Smola, Francis Bach, et al., Learning with kernels: support vector machines, r e gularization, optimization, and beyond , MIT press, 2002. [13] BG Giraud and R Peschanski, “On positiv e functions with positiv e fourier transforms, ” Acta Physica P olonica B , vol. 37, pp. 331, 2006. [14] John S Garofolo, Lori F Lamel, W illiam M Fisher , Jonathon G Fiscus, and David S Pallett, “Darpa timit acoustic-phonetic continous speech corpus cd- rom, ” NIST speech disc , vol. 1-1.1, 1993. [15] Eric W Healy , Sarah E Y oho, Y uxuan W ang, and DeLiang W ang, “ An algorithm to improve speech recog- nition in noise for hearing-impaired listeners, ” The Jour- nal of the Acoustical Society of America , vol. 134, no. 4, pp. 3029–3038, 2013. [16] Leo Lightburn and Mike Brookes, “ A weighted stoi intelligibility metric based on mutual information, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2016 IEEE International Conference on . IEEE, 2016, pp. 5365–5369. [17] Hui Zhang, Xueliang Zhang, and Guanglai Gao, “T rain- ing supervised speech separation system to improv e stoi and pesq directly , ” in Acoustics, Speech and Signal Pr o- cessing (ICASSP), 2018 , 2018, pp. 5374–5378.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment