Identifying influential patents in citation networks using enhanced VoteRank centrality
This study proposes the usage of a method called VoteRank, created by Zhang et al. (2016), to identify influential nodes on patent citation networks. In addition, it proposes enhanced VoteRank algorithms, extending the Zhang et al. work. These novel algorithms comprise a reduction on the voting ability of the nodes affected by a chosen spreader if the nodes are distant from the spreader. One method uses a reduction factor that is linear regarding the distance from the spreader, which we called VoteRank-LRed. The other method uses a reduction factor that is exponential concerning the distance from the spreader, which we called VoteRank-XRed. By applying the methods to a citation network, we were able to demonstrate that VoteRank-LRed improved performance in choosing influence spreaders more efficiently than the original VoteRank on the tested citation network.
💡 Research Summary
The paper investigates the problem of identifying influential patents within citation networks by adapting and extending the VoteRank centrality algorithm originally proposed by Zhang et al. (2016). After a concise introduction to the importance of patent citations as indicators of technological value and knowledge flow, the authors review traditional centrality measures (degree, closeness, betweenness) and newer approaches such as PageRank, H‑Index, and VoteRank. They describe VoteRank in detail: each node starts with a voting ability of 1, the voting score of a node is the sum of the voting abilities of its neighbors, and at each iteration the node with the highest score is selected as a spreader. Once a spreader is chosen, its voting ability and score are set to zero, and the voting ability of its immediate neighbors is reduced by a factor of 1/⟨k⟩, where ⟨k⟩ denotes the average (out‑)degree of the network. This process repeats until a predefined number of spreaders (expressed as a percentage p of the total nodes) is obtained. The authors note VoteRank’s computational efficiency because only a small local neighbourhood is updated each round.
To address the limitation that only immediate neighbours are affected, the authors propose two distance‑aware extensions. Both extensions apply a reduction to the voting ability of nodes at distance d from the chosen spreader, up to a maximum distance of ⟨k⟩ to keep the algorithm tractable. The first, VoteRank‑LRed (Linear Reduction), uses a linear decay factor f(d)=1−(d/⟨k⟩)·(1/⟨k⟩). The second, VoteRank‑XRed (Exponential Reduction), employs an exponential decay f(d)=(1/⟨k⟩)·e^(−d/⟨k⟩). In both cases, nodes farther away experience a smaller decrease in voting ability, reflecting the intuition that influence weakens with distance but does not vanish abruptly.
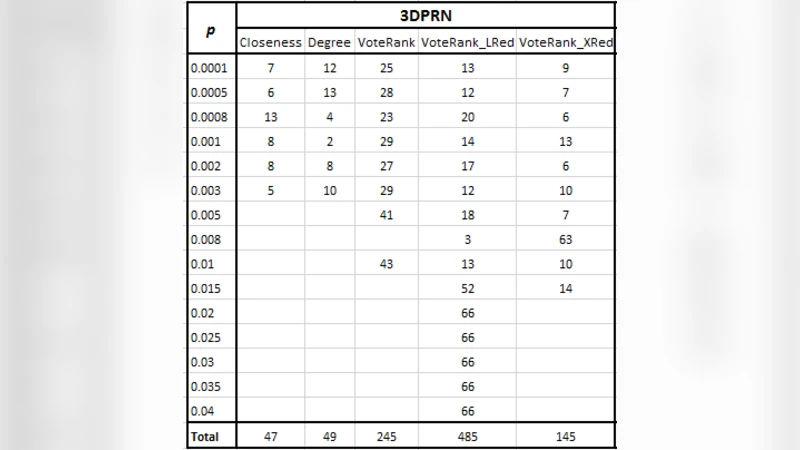
The experimental evaluation uses a real‑world patent citation network from the 3D‑printing domain (3DPRN) containing 653 nodes, 1,416 arcs, a density of 0.0033, and an average degree of 4.34. The authors compare six methods: Degree, Closeness, Betweenness, original VoteRank, VoteRank‑LRed, and VoteRank‑XRed. For each method, they vary the spreader proportion p from 0.0001 to 0.004 and run extensive Susceptible‑Infected‑Recovered (SIR) simulations with different infection (μ) and recovery (β) probabilities. Each configuration is simulated 1,000 times, resulting in over three million SIR runs. The primary performance metric is the final recovered fraction R(t_end), which quantifies how much of the network becomes “informed” by the selected spreaders.
Results consistently show that Betweenness performs the worst, while the three VoteRank‑based methods outperform traditional centralities. VoteRank‑LRed achieves the highest R(t_end) across most parameter settings, indicating superior spreader selection. VoteRank‑XRed ranks second, and the original VoteRank follows. When the number of spreaders is very small (fewer than 15 nodes), results become more volatile and Closeness occasionally outperforms the VoteRank variants. Additional experiments varying the λ=μ/β ratio confirm that all three VoteRank methods behave similarly as λ increases, but LRed maintains a slight edge in the overall infected proportion.
The authors conclude that incorporating distance‑dependent voting ability reduction yields a richer representation of influence in citation networks, especially the linear reduction which balances reach and attenuation effectively. They acknowledge that the choice of decay parameters (α, the maximum distance ⟨k⟩) may need tuning for different domains, and that their validation is limited to a single patent field. Future work is suggested to test the algorithms on larger, multi‑domain citation graphs, explore alternative diffusion models (e.g., SIS, Independent Cascade), and investigate adaptive parameter selection. Overall, the study demonstrates that enhanced VoteRank algorithms can more accurately identify influential patents, facilitating better understanding of technological diffusion and knowledge spillovers.
Comments & Academic Discussion
Loading comments...
Leave a Comment