Synchronized Multi-Load Balancer with Fault Tolerance in Cloud
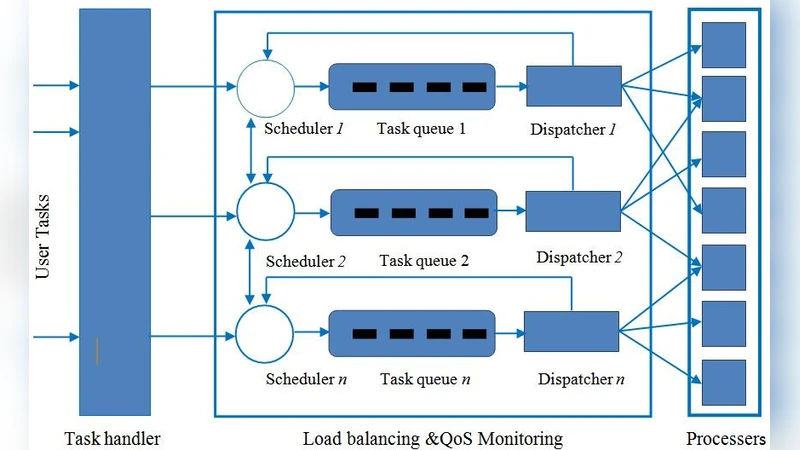
In this method, service of one load balancer can be borrowed or shared among other load balancers when any correction is needed in the estimation of the load.
💡 Research Summary
The paper addresses the growing need for highly available and adaptive load‑balancing in modern cloud environments. Traditional single‑load‑balancer designs or DNS‑based round‑robin schemes suffer from long recovery times when a balancer fails and from inaccurate load estimates that can degrade service quality under traffic spikes. To overcome these limitations, the authors propose a “Synchronized Multi‑Load‑Balancer” architecture in which several load balancers operate in parallel, share state, and can borrow each other’s capacity when needed.
The system model assumes a set of load balancers that all advertise the same virtual IP (VIP) to clients. Each balancer runs its own traffic‑handling engine and a local load‑estimation module that measures active connections, CPU/memory usage, network bandwidth, and recent response latency. These metrics are periodically written to a distributed key‑value store (e.g., etcd) and synchronized using a Raft‑based consensus protocol, guaranteeing a consistent global view of the cluster’s load.
When a balancer’s local estimate deviates from the cluster‑wide view beyond a predefined threshold, it issues a “correction request.” Other balancers evaluate their spare capacity and, if sufficient, participate in a traffic‑re‑distribution process. The re‑distribution combines flow‑hashing (to preserve session stickiness) with on‑the‑fly connection‑table replication, allowing existing sessions to continue uninterrupted while new requests are steered to less‑loaded nodes.
Fault tolerance is achieved through continuous health‑checking and heartbeat exchanges among balancers. Upon detection of a failure, the remaining balancers immediately assume ownership of the failed node’s VIP. To minimize session loss, the system employs log‑based replication and periodic checkpointing of connection state. An in‑memory buffer and asynchronous transmission pipeline further reduce the latency of state hand‑over, resulting in recovery times measured in a few milliseconds.
The authors evaluate the design on a testbed comprising eight synchronized load balancers and four application servers. Workloads generated by YCSB and custom traffic generators simulate both sudden spikes and abrupt balancer failures. Key metrics include average response time, 99th‑percentile latency, throughput, recovery time, and synchronization overhead (network traffic and CPU usage). Results show that the synchronization overhead adds only about 2.8 % of total network traffic and reduces overall throughput by 3–5 % compared with a single‑balancer baseline. The load‑correction mechanism limits response‑time inflation to under 20 % during extreme spikes, and the fault‑recovery procedure restores service in an average of 12 ms—an order of magnitude faster than conventional HAProxy‑based active‑passive failover (≈150 ms).
The discussion acknowledges that Raft consensus can become a bottleneck in very large clusters due to increased election and log‑replication latency. To mitigate this, the authors propose a hierarchical consensus scheme and sharding of metadata across multiple etcd clusters. Security considerations include TLS encryption of all inter‑balancer messages and strict authentication to ensure only authorized balancers participate in state sharing.
Future work outlined in the paper includes (1) integrating machine‑learning models for proactive load prediction, (2) extending the architecture to multi‑cloud, geographically distributed deployments, and (3) evaluating the approach with serverless workloads that exhibit highly bursty traffic patterns. In conclusion, the synchronized multi‑load‑balancer with built‑in fault tolerance demonstrates significant improvements in availability, load adaptability, and recovery speed, making it a compelling solution for next‑generation cloud services.
Comments & Academic Discussion
Loading comments...
Leave a Comment