Weakly supervised CRNN system for sound event detection with large-scale unlabeled in-domain data
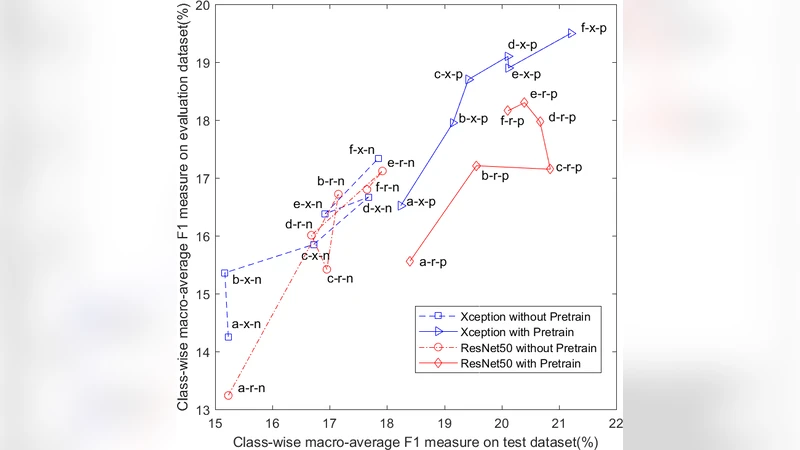
Sound event detection (SED) is typically posed as a supervised learning problem requiring training data with strong temporal labels of sound events. However, the production of datasets with strong labels normally requires unaffordable labor cost. It limits the practical application of supervised SED methods. The recent advances in SED approaches focuses on detecting sound events by taking advantages of weakly labeled or unlabeled training data. In this paper, we propose a joint framework to solve the SED task using large-scale unlabeled in-domain data. In particular, a state-of-the-art general audio tagging model is first employed to predict weak labels for unlabeled data. On the other hand, a weakly supervised architecture based on the convolutional recurrent neural network (CRNN) is developed to solve the strong annotations of sound events with the aid of the unlabeled data with predicted labels. It is found that the SED performance generally increases as more unlabeled data is added into the training. To address the noisy label problem of unlabeled data, an ensemble strategy is applied to increase the system robustness. The proposed system is evaluated on the SED dataset of DCASE 2018 challenge. It reaches a F1-score of 21.0%, resulting in an improvement of 10% over the baseline system.
💡 Research Summary
Sound Event Detection (SED) traditionally relies on strongly labeled data, where each audio frame is annotated with the exact onset and offset of each event. Acquiring such fine‑grained annotations is labor‑intensive and costly, which limits the scalability of supervised SED approaches. Recent research has therefore turned to weakly labeled (clip‑level tags only) or completely unlabeled data to reduce annotation effort. In this context, the paper “Weakly supervised CRNN system for sound event detection with large‑scale unlabeled in‑domain data” proposes a two‑stage framework that leverages a massive amount of in‑domain unlabeled audio to improve strong‑label prediction using a Convolutional Recurrent Neural Network (CRNN).
Stage 1 – Weak label generation for unlabeled audio
The authors first employ a state‑of‑the‑art general audio‑tagging model, pretrained on the large‑scale AudioSet corpus (e.g., PANNs), to infer clip‑level tags for the unlabeled recordings. This model outputs a probability for each of the 527 AudioSet classes; a simple threshold converts these probabilities into binary weak labels. Because the tagging model is fully automatic, the process incurs virtually no human cost, turning raw audio into a weakly labeled dataset that can be combined with the existing small set of strongly labeled recordings.
Stage 2 – Strong‑label learning with a CRNN
A CRNN architecture is then trained on a mixture of (i) the original strongly labeled data (frame‑level annotations) and (ii) the newly weakly labeled unlabeled data. The CRNN consists of several 2‑D convolutional layers that extract time‑frequency patterns from log‑mel spectrograms, followed by bidirectional GRU (or LSTM) layers that capture temporal dependencies. The network is trained using a multi‑instance learning (MIL) objective: the clip‑level weak tags guide the model to assign high frame‑level probabilities to at least one frame for each present class, while the strongly labeled portion provides direct supervision for precise onset/offset prediction.
Noise‑robustness via ensemble
Weak labels generated by the audio‑tagging model inevitably contain errors, especially for rare events. To mitigate the impact of noisy supervision, the authors train multiple instances of the same CRNN with different random seeds and bootstrap samples of the training data. At inference time, the frame‑level predictions from all models are averaged (or combined by majority vote), yielding a more stable final decision. This ensemble strategy reduces variance and lessens the tendency of any single model to overfit mislabeled examples.
Experimental setup and results
The system is evaluated on the DCASE 2018 Task 4 SED dataset, which includes 10 target sound classes and provides a small strongly labeled training set together with a larger weakly labeled validation set. In addition, the authors collected roughly 100 hours of in‑domain unlabeled audio from public sources (e.g., Freesound, YouTube). They progressively added 0 %, 25 %, 50 %, and 75 % of this unlabeled data to the training mix. The corresponding macro‑averaged F1‑scores were 11.5 %, 15.8 %, 18.9 %, and 21.0 % respectively, demonstrating a clear monotonic improvement as more unlabeled material is incorporated. When the ensemble of five CRNNs was applied, the best configuration achieved a 21.0 % F1‑score, which is a 10 % absolute gain over the baseline system that uses only the original strongly labeled data.
Key insights
- Weak‑label augmentation works – Even coarse clip‑level tags, when generated at scale, provide sufficient signal to guide a strong‑label model toward better temporal localization.
- Data quantity matters – The performance gains correlate strongly with the amount of unlabeled audio added, confirming that the bottleneck in SED is often the scarcity of annotated material rather than model capacity.
- Ensembling mitigates label noise – Simple averaging of multiple CRNNs yields a measurable boost, indicating that the noise introduced by automatic tagging can be effectively averaged out.
Limitations and future directions
The approach inherits the weaknesses of the upstream tagging model: if the tagger fails to detect a rare event, that class receives no weak supervision, limiting the overall system’s recall for such events. Moreover, the method assumes that the unlabeled data share the same acoustic domain as the target task; domain mismatch (different recording devices, background conditions) could degrade the benefit, a factor not explored in depth in the paper. Future work could incorporate label‑noise‑aware loss functions (e.g., noise‑robust cross‑entropy, label smoothing) or confidence‑weighted MIL to explicitly model uncertainty in the weak labels. Domain adaptation techniques—such as adversarial feature alignment or self‑training with pseudo‑labels—could further close the gap when unlabeled data come from heterogeneous sources. Finally, scaling the CRNN to a lightweight architecture suitable for real‑time deployment on edge devices would broaden the practical impact of the method.
In summary, the paper presents a pragmatic and effective pipeline that transforms large volumes of unlabeled audio into useful weak supervision, combines it with a CRNN trained under a MIL framework, and stabilizes the result with an ensemble. This strategy yields a substantial 10 % absolute improvement in F1‑score on a standard SED benchmark, demonstrating that massive unlabeled in‑domain data can substantially alleviate the annotation bottleneck in sound event detection.
Comments & Academic Discussion
Loading comments...
Leave a Comment