A novel pyramidal-FSMN architecture with lattice-free MMI for speech recognition
Deep Feedforward Sequential Memory Network (DFSMN) has shown superior performance on speech recognition tasks. Based on this work, we propose a novel network architecture which introduces pyramidal memory structure to represent various context inform…
Authors: Xuerui Yang, Jiwei Li, Xi Zhou
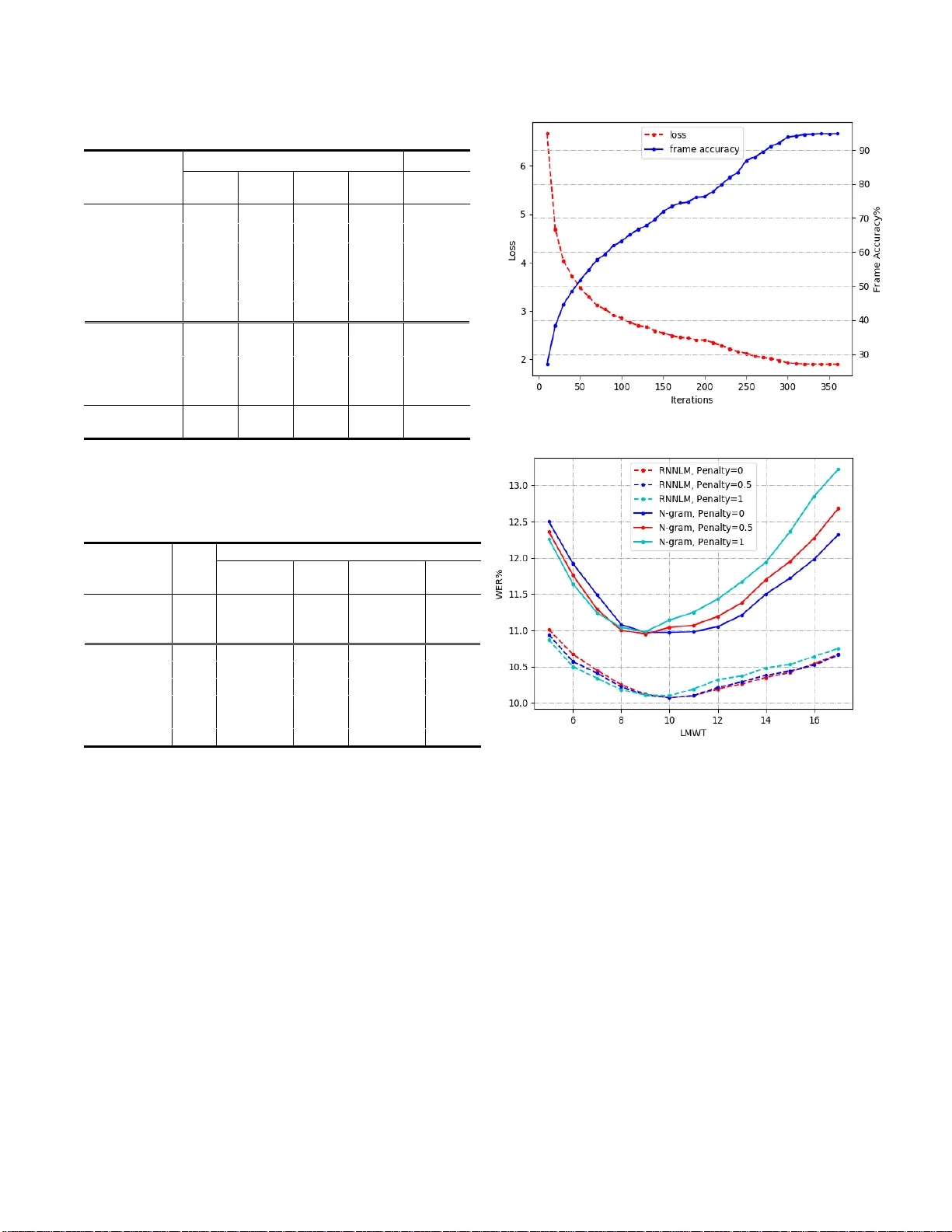
A NOVEL PYRAMIDAL-FSMN ARCHITECTURE WITH LATT ICE-FREE MMI FOR SPEECH RECOGNITION Xuerui Yang, Jiwei Li, Xi Zhou Cloudwalk Technol ogy, Shanghai, Chi na. {y angxuerui , lijiwei, zhouxi } @cloudwalk.c n ABSTRACT Deep Feedforward Sequential Memory Network (DFSMN) has shown su perior performance on speech recognition tasks. Based on th is work, we propos e a novel network architecture which i ntroduces pyra midal memory s tructure to represen t various context infor mation in different layers . Additionally , res-CNN layers are added in the front to extract more sophisticated features as well. Together with lattice -free maximum mutual information (LF-MMI) and cross entrop y (CE) j oint training criteria, experimental results sho w that this approach achie ves word erro r rates (WERs) of 3.62% and 10.89 % respectively on Librispeech and LDC97S62 (Switchboard 300 hours) corpora. Furthermore, R ecurrent neural network lan guage mo del (RNNLM) resco ring is applied and a WER of 2. 97% is obtained o n Librispeech. Index Terms — Au to matic speech r ecognition, FSMN, lattice-free MMI, RNNLM 1. INTRODUCTION Deep neural networks (DNN) have b een applied as acoustic model ( AM ) on large vo cabulary continuous speech recognition (LVCSR) system in recent years other t han GMM-HMM models [1, 2] . Early w ork s such as feedforward neural networks (FNN) [3] only ta kes current ti me steps as input. Rec urrent ne ural net work (RNN), especiall y long short-term memory network ( LSTM), has de monstrated superior results in spee ch recognitio n tasks d ue to it s cyclic connections [4] and utilization of sequential in formation . Convolutional neural network (CNN), in which local connectivity, weight sharing, and pooling tech niques are applied, also outperforms previous works [8 , 9]. However, the training o f RNN relies o n b ack - propagation through time (BPTT ) [10], which m a y bring problems s uch as more ti me consuming, gradient vani shing and exploding [11] due to its complex computation. Teacher forcing or professor forcing [12 ] training can solve these problems in some degree , but reduces th e robustness of RNN as well. Recently, a feedfor ward sequential memor y network (FSMN) is p roposed [13]. F SMN could model long-term relationship without any r ecurrent feedback. Mor eover, to build ver y d eep neural architect ure, skip connection is applied to FSMN [1 4], which makes a large improvement to previous m odels. Meanwhile , time delay neural network (TDNN) and factorized TDNN ( TDNN -F) [1 5] are also widely used feedforward net works. Traditional DNN-HMM hybrid AM are trained on cross- entropy (CE) criterion . Since speech recognition is a sequential pro blem, several seq uential discriminati ve training criteria are ap plied after CE training such as m a ximum mutual infor mation (MMI) [16], minimum B ayes risk ( MBR) [17] and minimum p hone err or (MP E) [ 18 ]. Inspired by the use of Connectionist Te mporal Classif ication (CT C) in diverse recognition tasks [ 19 , 2 0], a new method calle d lattice-free MMI [21 ] ( LF -MMI/Chain model) is developed. This method could be used without any CE ini tialization; thus, less computation is allo wed. In this paper, we pro posed a novel CNN P yramidal- FSMN (pFSMN) architecture w ith LF -MMI and CE joint training. A pyramid al struct ure is app lied in memory blocks . In thi s s tructure, bottom layers contain le ss context information while top layers co ntain more conte xt information , which employs appropriate time dependency and reduces the number of par ameters simultaneo usly. Besides, skip co nnections are add ed every several la yer . Considering e xtracting more sophisticated features from original Mel -Frequenc y Cep stral Coefficient s (MFCCs), CNN layers are dep loyed as th e front-end. In section 5 , we evaluate the performance of this architecture on vario us speec h reco gnition task s . In t he 300 hours Switchboard corp us, the proposed architecture achieves a curr ent best word error rate (WER) of 10.89 % . Further in the 1000 hours Librispeech co rpus, the WE R reaches 3.62%. In addition , R NN language model (RNNLM) has shown advances in decod ing a nd rescoring in our experiments , in which ab ove 1% ab solute improvement i s obtained compared with traditional N -gram language model. 2. FSMN FSMN [13] is a feedforward fully connected neural net work, appended with memory bloc ks in hidden layers as shown in Fig . 1 (a). The memory block takes previous time steps and next ti me steps input i nto a fixed -length represe ntation, then computes their b lock-sum as c urrent output. Dif ferent (a) ( b) Fig. 1 . FSMN(a) an d DFSMN(b) architec ture. from the original FSMN architecture , DFSMN [14] re moves the direct forward connection and take memory block a s the only i nput. To overcome the gradie nt v anishin g and exploding problems, skip connection and the memory strides are introduced. Fig. 1(b) sho ws this structure. The DFSMN co mponent c an be describ ed as t he following for mulations: ( 1) ( 2) denotes the output o f the + 1)-th memor y block, and denotes the output o f Re LU and linear layer. and are the co efficients in memory blocks. and are the strides. 3. LATTICE-FR EE MM I MMI aims to ma ximize the prob ability of the target seque nce, while min imizing the prob ability of all possible sequences . For a training set where and denote the ob served s equences and the corr ect sequence labels. T he MMI criterion is : ( 3) where represents the prior p robability of word sequence w and represents a feasible sequence in t he search space. Theoretically, the de nominator requires all the word sequences bu t th e computation w o uld be too slow. Therefor e , the practical deno minator graph is estimated using lattices [ 22 ] generated by frame-level CE pre-training. More recentl y, Povey et al. [21] use a lattice -free MMI in which an op timized hidden Mar kov model (HMM ) topology moti vated b y CT C is adop ted. In that method , 2-state left- to -rig ht HMM is used which i s similar to t he p hone-dep endent b lank labels o f CTC . Then a forward-backward calculatio n o n 4-gram phone language model is applied . Besides , AM in LF -MMI directl y output pseudo log -likelihood instead of so ftmax output. 4 . OUR APPROACH 4.1 . Pyra mid al structure The m emory block lengt hs are identical through all hidden layers both in FSM N a nd DF SMN. However, whe n botto m layers extract long co ntext info rmation at certain time step t , the bottom la yers contain this as well. T hus, the long -term relationship is duplicated and no longer needed in top la yers . In our appro ach, a pyramid al struct ure memor y block is demonstrated, in which mem ory block extrac ts more context information with the la yers go deep er. Hence, the bo ttom layers extract features o n the phone -level i nformation while top layers e xtract features on semantic-level and syntax-level information. This str ucture improves accurac y and reduce s the number of parameters simulta neously. With the modificatio n of the memory block, skip connections of ev ery layer s w ill not b e beneficial. Therefore, we reduce the number of skip co nnections. Only when there is a difference in memor y b lock le ngth, t he skip connection is added . By op timizing t he s hortcuts, the grad ients flow to deeper layers more e fficiently. This could be for mulated as follow, where m is the variation coe fficients in memory blocks: ( 4) 4.2. Residual CNN Instead of directly usi ng F SMN layers, a 6 -layer CNN module is applied at the front end. T he input data are reorganized into feature maps so that they could be fed into 2D -CNN. T his is inspired by image-processi ng. In speech recognition tasks, the MFCC feat ures and time step s correspond to pixel values o f and respec tively. With the network goes deeper , subsampling i s app lied to extract more robust features and reduce the f eatures ’ size . Il lustrated in Fig. 2, for every other la yer, sub sampling is used . In addition , residual structure is ad ded cor respondingly to solve the gradient proble ms. 4.3 . LF -MM I and CE joint tra ining Sequential trainin g usually tends to overfit. T o avoid this problem , a CE loss outp ut layer is dep loyed. T he MMI and Fig. 2 . CNN -pFSMN AM architecture, in which memory block structure is demonstrate d. CE criteria are combined with weighted sum, also known as CE regularization, seen in (5) and (6): ( 5) ( 6) where is the interpo lation weight related with the CE regularization. is described in (3) . During training, both LF -MMI and CE con tribute to the para meters updating and loss co mputation . While decoding, only LF - MMI branch is used to generate accurate ali gnment for the network outputs. 4.4. RNN LM rescoring During decoding, a n N-gram LM is built for generating la ttice and scoring. Even though N - gram LM is faster, it is still a statistic based LM and cannot ut ilize long context dependency . T o achieve better results, w e train a 5 -layer TDNN-LSTM LM for rescoring . LSTM layers and T DNN layers appear alternately. And TDNN layers co ncatenate the current ti me step and several pr evious ti me steps. T he initial decoding p roduces N -best word sequences; these seq uences are then fed into LM net work. 5 . EXPERIMENTS In this section, the performances of our approac h are evaluated on different LVCSR English co rpora including conversational and non-conversational s peech. The results are compared with other popular models. 5.1. Experiment setup The training data are 300 hours Switchboard corpus (SWBD- 300 ) and 1 000 hours Librispee ch corpus. Five test sets are evaluated: test -clean, test-other, dev-clean, dev -other a nd train-dev see n in T able 1 . For decoding, we train a 4 -gram word LM and an RN NLM with 145 00 books texts for Librispeech task a nd with Fish er +S witchboard texts for S WB D- 300 task. For running experiments, Kaldi [ 23 ] is used. HMM- GMM m o dels are trained to g enerate f o rce -alignment for neural net work training. T he features fed to all the evaluated models are 40-dimensinal MFCC and 100 -dimensional i- vectors for speaker adaptio n. T he MF CC features are extracted from 25 m s Ha mming w indo w for every 10 m s. We also adopt 3-f old speed perturbation (0.9x/1.0x/1.1x) for data augmentation in order to b uild more robust model . The n etwork architecture is shown in Fig. 2 . 3*3 and 5* 5 conv layers are e mployed at the front , and s hortcuts are added when kernel size varie s . 10 pFSMN block s co ntain a bloc k sum la yer, a l inear layer and a ReLU layer with di mensions of 1 536, 256 and 256 in each block . Both CNN and pFSM N layers are penalized with L2 regularization . T he time orders and strides are from 4 to 20 and 1 to 2 respectively. RNNLM is a 5-layer TDNN- LSTM network with 1024 d imension. 5.2. Results Table 1 illustrates the W ERs of various models . The r esults show that LF -MMI based method ac hieves obvious improvements tha n the previous CE ba sed [1 4] m et hod. Further, pFSMN with LF-MMI outperfor ms the previous models on both large, non -conversational (Librisp eech) an d small, conver sational ( SWBD - 300 ) corpora. For example, in SWBD- 300 , WER of our ap pro ach drop s from 11.15 % to 1 0.89 % compared with t he BLSTM model. Moreover, by using RNNLM for n-best r escoring with n equals to 20, the WERs hav e achieved 2.97 % in test-clean and 10.03 % in train-dev respectively. This p roves RNNLM has a superior performance than the co nventio nal N -gram LM. Ho wever, it also slows down the decod ing spee d. T herefore, a trade -off needs to be co nsidered wh en choosing be t ween these t wo methods. Various tricks are experimented as in T able 2. It presents that con v la yers with shortcuts are beneficial to the model. And 5 *5 kernel i s relativel y better am ong diverse kernel s izes. For memory blo ck structure, the results s how that bi g end pyramidal (top lay ers contain more co ntext information) structure outperfor ms small en d (bo ttom layers contain more Table 1 . Comparison of our approach and previou s methods on Librispeech and S WBD- 300 tasks. * RNNLM rescoring is used on n-best sentences after decoding. * train -dev set is the first 4000 utterances from SWBD- 300 data, the training set is the rest part. Table 2 . WER gain o f AM w ith va rious architectures on SWBD- 300 task. Models Size SWBD train-dev Gain +RNNLM rescoring Gain Baseline (DFSMN- chain) 1 4M 11.99 - 10.97 - 1a(c3*os1*) 1 9M 11.47 +4.3% 10.27 +6.4% 1b(c3s2o*) 1 8M 11.21 +6.5% 10.22 +6.8% 1c(c3s2) 1 8M 11.06 +7.8% 10.13 +7.7% 1d(c3s2op*) 1 8M 10.95 +8.7% 10.07 +8.2% 1f(c3s3p) 1 8M 11.33 +5.5% 10.23 +6.7% 1g(c5s2p) 1 8M 1 0.89 +9.2% 10.03 +8.6% *cn: conv layers with n*n ke rnels; *o: semi-orthogonal constraints; *sn: different skip connection method; *p: pyramidal-FSMN structure; context information) pyramidal structure. We have also tried semi-orthogonal constrain ts on linear bo ttleneck layer in [15], but it does no benefi t to the model accord ing to Table 2 1b and 1c. F ig . 3 (a) illustrates the training loss and accurac y of our final model. The model te nds to converge after 300 iterations. Fig . 3 ( b) is the W ERs compar ison of different decodin g settings. T he average i mprovement of RNNLM resco ring is more than 1%. 6. CONCLUSION S In summary, we proposed a novel CNN-pFSMN architecture trained with LF-MMI and rescored with RNNLM. B y appl y- (a) (b) F ig . 3. (a) The learning cu rves of va rious arch itecture on SWBD- 300 task. (b) The WERs with differen t dec oding settings on SWBD- 300 task. LMWT is the la nguag e model weight. -ing res- CNN, CE/LF-MMI j oint traini ng a nd p yramidal memory structure, th is approach h as co nstantly outperforme d the previo us mod els o n bo th Librispeec h and S witchboard tasks. Oth er tricks li ke L2 regularization a nd speed perturbation are also beneficial. T he results on test-clean a nd train-dev test set are 2.97% and 10.0 3% with rescoring respectively. The experimental results p rove that the p yramidal structure could extract pho ne-level, semantic -level and syntax-level information at different layers. In spired by [26] , the combinatio n of LF -MMI and end - to -end on o ur architecture will be further explo red in recent future. Models Librispeech SWBD test- clean dev- clean test- ot her dev- other train- dev T DNN [24] 4.17 3.87 10.62 10.22 13.91 BLSTM [24] - - - - 11.75 T DNN -F [24] 3 .8 3.29 8.76 8.71 11.15 DS2 [20] 5.15 - 12.73 - - ESPnet [25] 4 .6 4 .5 13.7 13 .0 17.6 D FSMN [14] 3.96 3.6 10.39 10.21 - D FSMN - Chain 3. 84 3. 45 9.01 8.9 11.99 CNN- p FSMN - Chain 3.62 3.28 8.45 8.37 1 0.89 +RNNLM rescoring* 2.97 2.56 7.5 7. 47 10.03 6. REFERENCES [1] Li Deng and X iao Li, “Machine learnin g paradigms for speech recognition: An overview,” IEEE Transactions on Audio, Speech, and Language Processing , vol. 21, no. 5, pp. 1060 – 1089, 2013. [2 ] Geoffrey Hinton , L i Deng, Don g Yu, George E Dahl, Abdel- rahman Mohamed, Navdeep Jaitly , A ndrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N Sain ath, et al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,” IEEE Signal processing magazine , vol. 29, no. 6, pp. 82 – 97, 2012. [3 ] George E Dahl, Dong Yu, Li Deng, and Alex Acero, “ Context- dependent pre-trained deep neural networks for large-vocabulary speech re cognition,” IEEE Transactions on audio, spe ech, a nd language processing , vol. 20, no. 1, pp. 30 – 42, 2012. [4 ] Tomas Mikolov, Martin Karafiat, Luk as Burget, Jan Cernocky, and Sanjeev Khudanpur, “Rec urrent neural network based language model,” in Eleventh Annual Confe rence of the International Speech Communication Association , 2010. [5 ] Andrew W Senior, Hasim Sak, and Izh ak Sh afran, “ Context dependent phone m o dels for ls tm rnn acous tic modelling.,” i n ICASSP , 2015, pp. 4585 – 4589. [6] Hasim Sak, Andrew Senior, and Franc¸ oise Beaufays, “ Long short-term memory recurrent neural network architectures for large scale acoustic m od eling,” in Fifteenth annual co nference of the international speech communication association , 2014. [7 ] Alex Graves, Abdel-rahma n Moh amed, and Geoff rey Hinton, “Speech recognition with deep recurrent neural networks,” in Acoustics, speech and signal processing (icassp), 2 013 ieee international conference on . IEEE, 2013, pp. 6645 – 6649. [8] Yanmin Qian, Men gxiao Bi, Tian Tan, and Kai Yu, “ Very deep convolutional neural n etworks f o r noise robust speech recognition,” IEEE/ACM Tra nsactions on Audio, S peech, and Language Processing , vol. 24, no. 12, pp. 2263 – 2276, 2016. [9 ] Ossama Abdel-Hamid, Abdel-rahman Mohamed, Hui Jiang, Li Deng, Gerald Penn, and Dong Yu, “Convolutional neural n etworks for speech recognition,” IEEE/ACM Transactions on a udio, spee ch, and language processing , vol. 22, no. 10, pp. 1533 – 1545, 2014. [10 ] Paul J Werbos, “Backpropag ation through time: what it does and how to do it,” Pro ceedings of the IEEE , vol. 78, n o. 10, pp. 1550 – 1560, 1990. [11 ] Y o shua Bengio, Patrice Sim ard, and Paolo Frasconi, “ Learning long-term dependen cies with grad ient d escent is difficult,” IEEE transactions on neural networks , vol. 5, no. 2, pp. 157 – 166, 1994. [12 ] Alex M Lam b, Anirudh Goyal ALIAS PARTH GOYAL, Ying Zhang, Saizhe ng Zh ang, Aaron C Courville, and Yoshua Bengio, “Professor forcing: A new algorithm for training recurrent n etworks,” in Advances In Neural Information Processing S ystems , 2016 , pp. 4601 – 4609. [13 ] Shiliang Zhang, Co ng Liu, Hui Jian g, Si Wei, Lirong Dai, and Y u Hu, “ Feedforward sequential memory networks: A new structure to learn long- term dep endency,” arXiv preprint , 2015. [14 ] Shiliang Zhang, Ming L ei, Zhijie Yan, and Lirong Dai, “ Deep- fsmn for large vocabulary continuous speech recognition,” arXiv preprint arXiv : 1803.05030, 2018. [15 ] Daniel P ovey, Gaofeng Cheng, Yiming Wang, Ke Li, Hainan Xu, Mahsa Yarmohamadi, and Sanjeev Kh udanpur, “ Semi- orthogonal low -rank m atrix factorization for deep neural networks,” INTERSPEECH (2018, submitted) , 2018. [16 ] Lalit Bahl, P eter Brown, Peter De Souza, and Robert Mercer, “Maximum m utual information estimation of hidden mark ov model par ameters for speech recognition,” in Acoustics, Speech, and Signal Processing, IEEE International Co nference o n ICASSP’86 . IEEE, 1986, vol. 11, pp. 49 – 52. [17 ] Matthew Gibson and Thomas Hain, “Hypothesis spaces for minimum bayes risk training in large vocabulary speech recognition ,” in Ninth International Conference on Spoken Language Processing , 2006. [ 18 ] Karel Vesely, A rnab Ghoshal, Lukas Burget, a nd Daniel ´ Pove y, “Sequence -discriminative training of deep neural n etworks.,” in Interspeech , 2013, pp. 2345 – 2349. [ 19 ] Alex Graves, Santiago Ferna ndez, Faustino Gomez, and Jurgen Schmidhuber, “Connectionist temporal classifi cation: labelling unsegmented sequence data with recurrent neural netw orks,” in Proceedings of the 23rd international conference on Machine learning . ACM, 2006, pp. 369 – 376. [20] Da rio Am od ei, S undaram Ananth anarayanan, Rishita Anubhai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Ca sper, Bryan Catanzaro, Qiang Cheng, Guolian g Chen, et al., “De ep speech 2: End- to -end speech recognition in english and mandarin,” in International Conference on Machine Learning , 2016, pp. 173 – 182. [21 ] Dan iel Povey, Vijayaditya Peddinti, Daniel Galvez, Pegah Ghahremani, Vimal Manohar, Xingyu Na, Yiming Wang, and Sanjeev Khudanpur, “ Purely sequencetrained neural n etworks for asr based o n lattice-free mmi.,” in Interspeech, 2016, pp. 2751 – 2755. [2 2 ] Philip C Wood land and Daniel Po vey, “Large scale discriminative training of hidden markov models for speech recognition,” Computer Speech & Language , vol. 1 6, no. 1, p p. 25 – 47, 2002. [23 ] Daniel P ovey, Arnab G hoshal, G illes Bou lianne, L ukas Burge t, Ondrej Glembek, Nagendra Goel, Mirko Hannem ann, P etr Motlicek, Yanmin Qian, P etr Schwarz, et a l., “The kaldi sp eech recognition toolkit,” in IEEE 2 011 workshop on auto matic speech recognition and understanding. IEEE S ignal Processing S ociety, 2011, n umber EPFL-CONF-192584. [24 ] “Kaldi speech recognition toolkit,” https://github.com/kaldiasr/kaldi. [25] “Espnet: end - to -end speec h processing toolkit, ” https://github.com/espnet/espnet. [26] Albert Zeyer, Kazuki Irie, Ralf Schlu ter, and Hermann Ney, “Improved training of end - to -end attention m o dels for s peech recognition,” arXiv preprint arXiv:1805.03294 , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment