Concatenated Identical DNN (CI-DNN) to Reduce Noise-Type Dependence in DNN-Based Speech Enhancement
Estimating time-frequency domain masks for speech enhancement using deep learning approaches has recently become a popular field of research. In this paper, we propose a mask-based speech enhancement framework by using concatenated identical deep neural networks (CI-DNNs). The idea is that a single DNN is trained under multiple input and output signal-to-noise power ratio (SNR) conditions, using targets that provide a moderate SNR gain with respect to the input and therefore achieve a balance between speech component quality and noise suppression. We concatenate this single DNN several times without any retraining to provide enough noise attenuation. Simulation results show that our proposed CI-DNN outperforms enhancement methods using classical spectral weighting rules w.r.t. total speech quality and speech intelligibility. Moreover, our approach shows similar or even a little bit better performance with much fewer trainable parameters compared with a noisy-target single DNN approach of the same size. A comparison to the conventional clean-target single DNN approach shows that our proposed CI-DNN is better in speech component quality and much better in residual noise component quality. Most importantly, our new CI-DNN generalized best to an unseen noise type, if compared to the other tested deep learning approaches.
💡 Research Summary
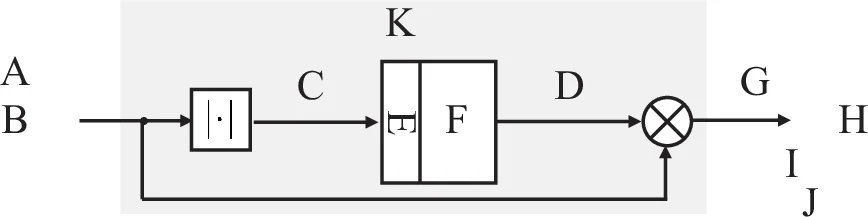
This paper addresses the persistent problem of noise‑type dependence in deep‑learning‑based speech enhancement. The authors propose a novel architecture called Concatenated Identical Deep Neural Networks (CI‑DNN), which builds on a single basic DNN module trained under multiple signal‑to‑noise ratio (SNR) conditions. The basic module is designed to provide a modest, fixed SNR improvement of 5 dB for any input SNR ranging from –5 dB to 20 dB. To achieve larger overall gains, the same module is concatenated in series without any additional training, forming a multi‑stage system where each stage contributes another 5 dB of improvement. In practice, the authors evaluate 2‑stage (≈10 dB gain) and 3‑stage (≈15 dB gain) configurations.
Network design. The basic DNN receives a magnitude spectrogram (256‑point DFT, 50 % overlap) together with two left and two right context frames, yielding an input vector of 645 dimensions (5 × 129). It consists of five hidden layers with sizes 1024‑512‑512‑512‑256, all using leaky ReLU activations, batch normalization, and a dropout rate of 0.2. Residual skip connections are added wherever dimensions match, resulting in three bypasses that help mitigate vanishing gradients. The output layer has 129 units with a sigmoid activation, representing a time‑frequency mask in the range
Comments & Academic Discussion
Loading comments...
Leave a Comment