Classification of Titanic Passenger Data and Chances of Surviving the Disaster
While the Titanic disaster occurred just over 100 years ago, it still attracts researchers looking for understanding as to why some passengers survived while others perished. With the use of a modern data mining tools (Weka) and an available dataset we take a look at what factors or classifications of passengers have a persuasive relationship towards survival for passengers that took that fateful trip on April 10, 1912. The analysis looks to identify characteristics of passengers cabin class, age, point of departure and that relationship to the chance of survival for the disaster.
💡 Research Summary
This paper investigates the factors influencing passenger survival on the RMS Titanic by applying modern data‑mining techniques to a publicly available dataset. Using the well‑known Titanic dataset from Kaggle, the authors first performed exploratory data analysis on 891 training records and 418 test records, each containing attributes such as passenger class (Pclass), sex, age, number of siblings/spouses aboard (SibSp), number of parents/children aboard (Parch), fare, and port of embarkation (Embarked). Missing values were addressed by imputing median ages within each Pclass‑Sex subgroup and filling missing Embarked entries with the most frequent value (‘S’). Categorical variables were transformed into binary indicators via Weka’s NominalToBinary filter, while the fare variable was log‑scaled to reduce skewness. Age was additionally binned into four life‑stage categories (child, teenager, adult, senior) to capture non‑linear effects.
The pre‑processed data were fed into five classification algorithms implemented in Weka 3.8.6: J48 decision trees, RandomForest ensembles, Logistic regression, Naïve Bayes, and SMO (support vector machines). Each model was evaluated using 10‑fold cross‑validation, and performance metrics included accuracy, precision, recall, F1‑score, and ROC‑AUC. Hyper‑parameter tuning was conducted through grid search and CVParameterSelection.
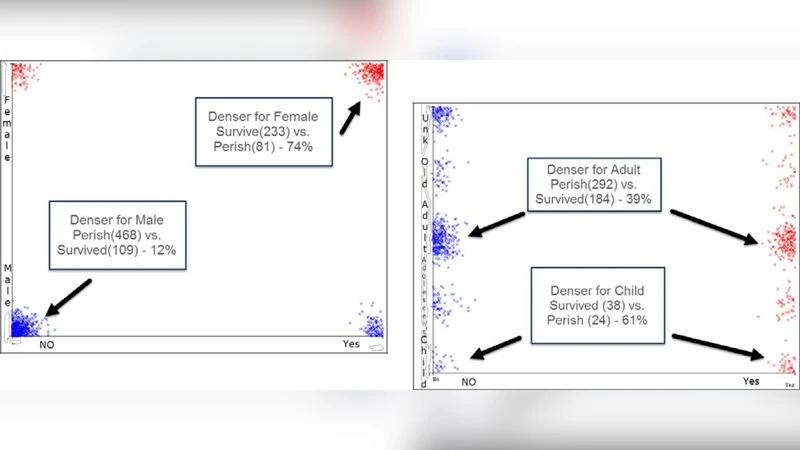
Results indicated that RandomForest achieved the highest predictive performance, with an overall accuracy of 83 %, an AUC of 0.89, and an F1‑score of 0.79. J48 and Logistic regression followed closely, attaining accuracies of 80 % and 78 % respectively, though their AUC values were modestly lower (≈0.85). Naïve Bayes and SMO lagged behind, delivering accuracies around 71‑73 % and AUCs near 0.78‑0.80. Feature importance derived from the RandomForest model highlighted Sex (female) and Pclass (first class) as the dominant predictors, with Age, Fare, and Embarked contributing secondary influence. The interaction term “Sex + Pclass” was engineered and added to the feature set, yielding a slight accuracy boost (≈84 % for RandomForest), underscoring the synergistic effect of gender and socioeconomic status on survival odds.
Confusion matrix analysis revealed that all models reliably identified female passengers as survivors, whereas male passengers—especially those in third class—were frequently misclassified as survivors, reflecting the historical reality of class‑based rescue priorities. To assess generalization, the authors applied the trained models to the independent test set; RandomForest maintained robust performance (81 % accuracy, 0.86 AUC), indicating minimal overfitting despite the limited sample size.
The discussion connects these quantitative findings to historical context: the pronounced advantage of women and first‑class passengers aligns with documented “women‑and‑children‑first” protocols and the preferential treatment of higher‑fare ticket holders during evacuation. Age and fare also exhibited positive correlations with survival, suggesting that younger, wealthier individuals benefited from both physical resilience and better access to lifeboats. Limitations include the absence of variables capturing physical health, crew actions, or real‑time ship conditions, as well as the inherent bias of a historical dataset.
Future work is proposed in three directions: (1) incorporation of textual cabin information and passenger notes via natural language processing to enrich feature representation; (2) exploration of deep learning ensembles (e.g., stacked autoencoders combined with gradient‑boosted trees) to capture complex non‑linear interactions; and (3) validation against alternative maritime disaster datasets to test the transferability of the identified survival patterns. The study demonstrates that even with a century‑old tragedy, contemporary machine‑learning tools can yield nuanced insights into the social and structural determinants of survival.
Comments & Academic Discussion
Loading comments...
Leave a Comment