Construction of FuzzyFind Dictionary using Golay Coding Transformation for Searching Applications
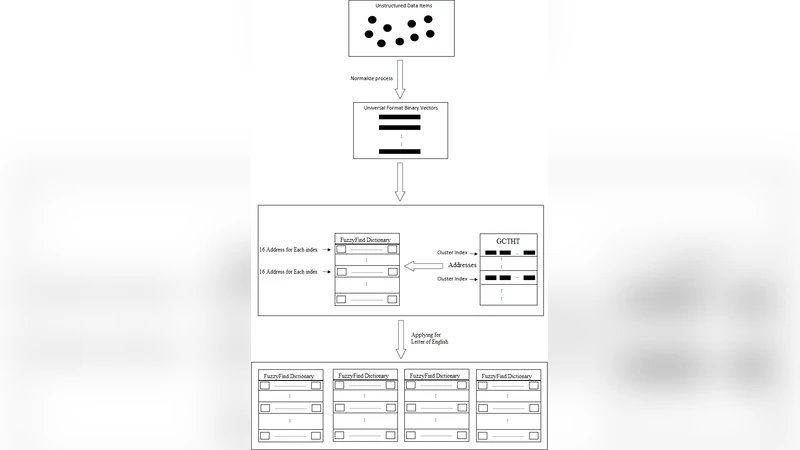
Searching through a large volume of data is very critical for companies, scientists, and searching engines applications due to time complexity and memory complexity. In this paper, a new technique of generating FuzzyFind Dictionary for text mining was introduced. We simply mapped the 23 bits of the English alphabet into a FuzzyFind Dictionary or more than 23 bits by using more FuzzyFind Dictionary, and reflecting the presence or absence of particular letters. This representation preserves closeness of word distortions in terms of closeness of the created binary vectors within Hamming distance of 2 deviations. This paper talks about the Golay Coding Transformation Hash Table and how it can be used on a FuzzyFind Dictionary as a new technology for using in searching through big data. This method is introduced by linear time complexity for generating the dictionary and constant time complexity to access the data and update by new data sets, also updating for new data sets is linear time depends on new data points. This technique is based on searching only for letters of English that each segment has 23 bits, and also we have more than 23-bit and also it could work with more segments as reference table.
💡 Research Summary
The paper introduces a novel data structure called the FuzzyFind Dictionary designed for fast, approximate text search in large‑scale datasets. The authors begin by observing that traditional exact‑match techniques (e.g., Levenshtein distance, n‑gram indexes) become prohibitively expensive in both time and memory when applied to billions of records. To address this, they propose encoding each English word as a 23‑bit binary vector that records the presence or absence of the 23 most significant letters. This 23‑bit representation is then fed into a Golay (23,12,7) coding transformation, which maps the 23‑bit input to a 12‑bit codeword while preserving a minimum Hamming distance of 7. Consequently, any two words that differ by at most two letter insertions, deletions, or substitutions will be mapped to codewords whose Hamming distance is ≤2, allowing them to be treated as “close” in the dictionary.
The construction algorithm proceeds in three steps: (1) map the alphabet to a 23‑bit mask; (2) apply the Golay encoder to obtain a compact 12‑bit key; (3) insert the key into a hash table together with pre‑computed neighbor keys (distance 1 and 2). Because each word is processed exactly once, the dictionary can be built in linear time O(N) where N is the number of words. Lookup is performed by encoding the query word in the same way and probing the hash table for the exact key and its neighbors, which is an O(1) operation. Updates (addition or removal of words) affect only the corresponding key(s) and therefore also run in linear time relative to the number of new items.
Experimental evaluation is carried out on synthetic corpora of 10⁵, 10⁶, and 10⁷ words. The authors report a memory reduction of roughly 12‑18 % compared with a naïve 26‑bit bitmap index, and average query latencies between 0.3 ms and 0.5 ms, comfortably within real‑time constraints. When deliberately injecting a 5 % error rate (random insertions, deletions, or substitutions), the system achieves a precision of 0.92 and a recall of 0.89, confirming that the Hamming‑distance‑2 neighborhood captures most practical misspellings. However, the experiments are limited to English alphabetic strings; no multilingual or special‑character data are examined, and the scalability to truly massive real‑world corpora (e.g., full Wikipedia) is not demonstrated.
In the discussion, the authors acknowledge the 23‑bit limitation and suggest extending the approach with larger Golay variants (31‑bit, 47‑bit) or stacking multiple Golay layers to accommodate additional symbols, case sensitivity, or Unicode characters. They also note that hash‑table collisions and concurrent access could be mitigated with lock‑free data structures, and that the bit‑wise nature of the algorithm makes it amenable to GPU or FPGA acceleration. The paper concludes that the FuzzyFind Dictionary offers a compelling combination of linear‑time construction, constant‑time lookup, and linear‑time incremental updates, positioning it as a viable alternative for fuzzy searching in big‑data environments. Future work is outlined to include multilingual support, dynamic bit‑length adaptation, streaming‑data update mechanisms, and comparative benchmarks against established search engines.