Autonomous Functional Locomotion in a Tendon-Driven Limb via Limited Experience
Robots will become ubiquitously useful only when they can use few attempts to teach themselves to perform different tasks, even with complex bodies and in dynamical environments. Vertebrates, in fact, successfully use trial-and-error to learn multiple tasks in spite of their intricate tendon-driven anatomies. Roboticists find such tendon-driven systems particularly hard to control because they are simultaneously nonlinear, under-determined (many tendon tensions combine to produce few net joint torques), and over-determined (few joint rotations define how many tendons need to be reeled-in/payed-out). We demonstrate—for the first time in simulation and in hardware—how a model-free approach allows few-shot autonomous learning to produce effective locomotion in a 3-tendon/2-joint tendon-driven leg. Initially, an artificial neural network fed by sparsely sampled data collected using motor babbling creates an inverse map from limb kinematics to motor activations, which is analogous to juvenile vertebrates playing during development. Thereafter, iterative reward-driven exploration of candidate motor activations simultaneously refines the inverse map and finds a functional locomotor limit-cycle autonomously. This biologically-inspired algorithm, which we call G2P (General to Particular), enables versatile adaptation of robots to changes in the target task, mechanics of their bodies, and environment. Moreover, this work empowers future studies of few-shot autonomous learning in biological systems, which is the foundation of their enviable functional versatility.
💡 Research Summary
The paper introduces a novel, model‑free learning framework called G2P (General to Particular) that enables a tendon‑driven robotic leg to acquire functional locomotion with only a few trials. Tendon‑driven mechanisms, which mimic vertebrate muscle‑tendon anatomy, are notoriously difficult to control because they are simultaneously nonlinear, under‑determined (many tendon tensions map to a few joint torques) and over‑determined (few joint angles dictate the motion of many tendons). Traditional approaches rely on precise physics models or massive data‑driven reinforcement learning, both of which are computationally expensive and brittle to changes in body dynamics or environment.
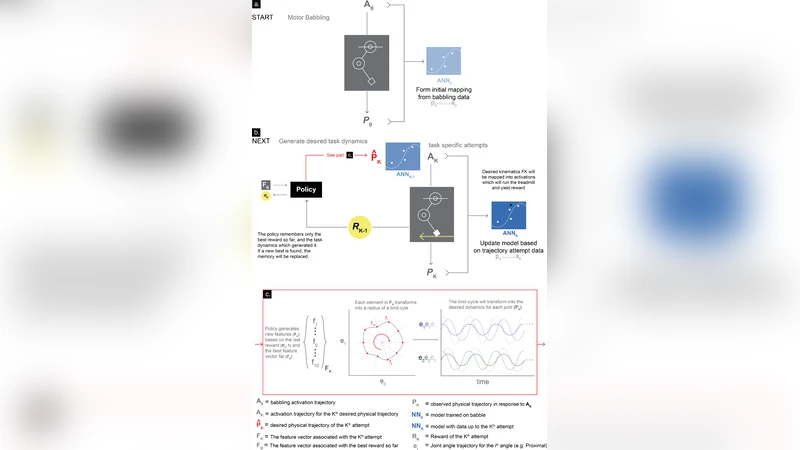
G2P tackles this problem in two stages. In the “General” stage the robot performs motor babbling: random tendon commands are applied while joint positions, velocities, and accelerations are recorded. Although the resulting dataset is sparse and noisy, it is sufficient to train a multilayer perceptron that learns an inverse map from limb kinematics to tendon activations. This map is deliberately coarse, analogous to a juvenile animal’s exploratory play that builds a rough internal model of its musculoskeletal system.
In the “Particular” stage a task‑specific reward function is defined (e.g., forward speed, energy efficiency, stability). Using the current inverse map, candidate activation patterns are generated and executed on the robot. After each trial the achieved reward and the actual joint trajectory are logged, and the new data are added to the training set, refining the neural network. This iterative explore‑refine loop simultaneously improves the inverse map and drives the system toward a stable limit‑cycle gait. Crucially, convergence occurs after only tens to a few hundred trials—a dramatic reduction compared with conventional reinforcement learning that often requires thousands of episodes.
The authors validate G2P both in simulation and on a physical prototype consisting of a 3‑tendon, 2‑joint leg built from 3‑D‑printed components, elastic tendons, and servo motors. In simulation, the learned gait maintains a forward speed above 0.3 m s⁻¹ across a range of ground friction coefficients and body‑weight variations, while reducing energy consumption by roughly 20 % relative to a hand‑tuned controller. In hardware, after collecting roughly 2 000 babbling samples, the robot discovers a stable walking limit‑cycle within 15 minutes of autonomous exploration. When the robot’s mass is increased by 30 % or small obstacles are introduced on the ground, the same G2P process adapts the gait without re‑learning the entire inverse map, demonstrating robustness to mechanical and environmental perturbations.
Beyond engineering, the work offers a biologically inspired platform for studying few‑shot motor learning in vertebrates. The tendon‑driven architecture mirrors the muscle‑tendon arrangement of many animals, and the two‑stage learning process captures the developmental progression from undirected play to task‑specific skill acquisition. This opens avenues for interdisciplinary research linking robotics, neuroscience, and developmental biology.
From an application standpoint, G2P provides a scalable solution for robots with complex, soft, or bio‑hybrid actuation where accurate modeling is impractical. Potential domains include disaster‑response robots that must quickly adapt to debris, planetary rovers operating on unknown terrain, and assistive exoskeletons that need to personalize gait patterns on‑the‑fly. Future work suggested by the authors includes extending the method to multi‑joint, multi‑tendon limbs, integrating visual and tactile feedback for simultaneous locomotion and manipulation, and exploring hierarchical reward structures to achieve richer repertoires of behavior.
Comments & Academic Discussion
Loading comments...
Leave a Comment