Opinion Polarization by Learning from Social Feedback
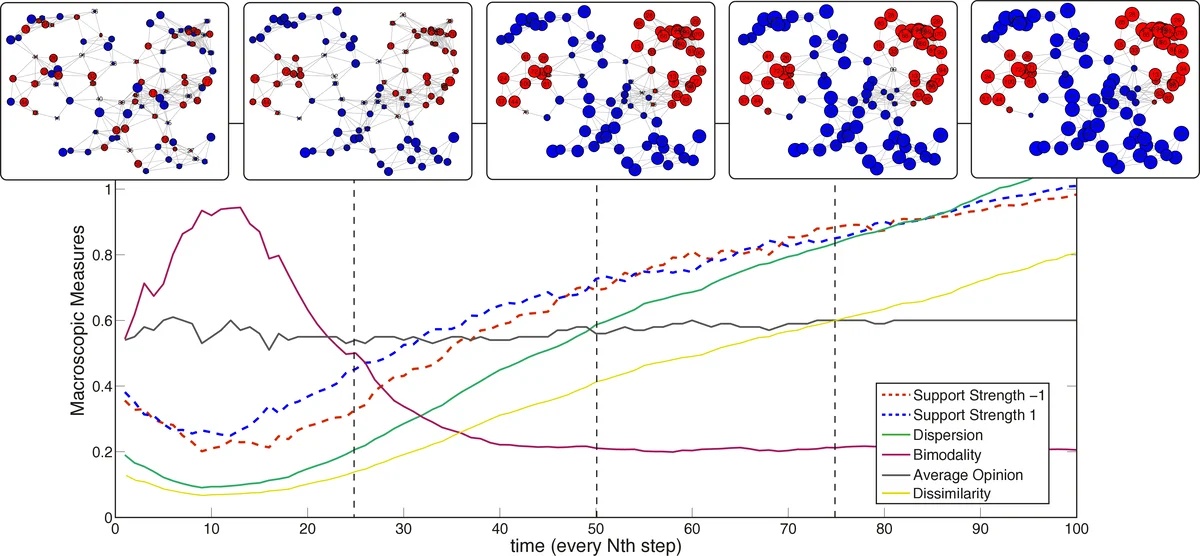
We explore a new mechanism to explain polarization phenomena in opinion dynamics in which agents evaluate alternative views on the basis of the social feedback obtained on expressing them. High support of the favored opinion in the social environment, is treated as a positive feedback which reinforces the value associated to this opinion. In connected networks of sufficiently high modularity, different groups of agents can form strong convictions of competing opinions. Linking the social feedback process to standard equilibrium concepts we analytically characterize sufficient conditions for the stability of bi-polarization. While previous models have emphasized the polarization effects of deliberative argument-based communication, our model highlights an affective experience-based route to polarization, without assumptions about negative influence or bounded confidence.
💡 Research Summary
This paper, titled “Opinion Polarization by Learning from Social Feedback,” introduces a novel mechanism to explain the emergence and persistence of opinion polarization in social networks. Departing from traditional models that focus on deliberative argument exchange or bounded confidence, the proposed model centers on a reinforcement learning process driven by affective social feedback.
The core premise is that individuals express opinions and learn from the social reactions (approval/disapproval) they receive from their peers. When an expressed opinion is met with agreement, it acts as positive feedback, reinforcing the individual’s valuation of that opinion. Conversely, disagreement serves as negative feedback, diminishing its value. Agents stochastically choose which opinion to express based on these dynamically updated valuations, creating a feedback loop where opinions that are locally popular become self-reinforcing.
The authors formalize this process within a network of agents. Through agent-based simulations on networks with community structure (like random geometric graphs), they demonstrate that this simple mechanism reliably leads to stable bipolarization. Densely connected subgroups function as “echo chambers,” where internal reinforcement drives group polarization toward extreme consensus on one opinion. Crucially, the weak ties (structural holes) between these cohesive subgroups act as barriers, preventing a single opinion from dominating the entire network and allowing competing opinions to stabilize in different communities.
A significant theoretical contribution of the paper is linking this microscopic learning process to game-theoretic equilibrium concepts. The authors show that the reinforcement learning dynamics converge to a stationary state corresponding to a Nash equilibrium of an underlying “opinion game.” In this game, an agent’s strategy is their choice of opinion expression, and the payoff is determined by the alignment with their neighbors’ opinions. This connection allows for an analytical characterization of the conditions for stable bipolarization. Specifically, they prove that the existence of “cohesive subgroups” within the network is a sufficient structural condition for different subgroups to settle into different, stable opinion equilibria.
The model is parsimonious, requiring no assumptions about negative influence, bounded confidence, or opinion homophily to drive interaction. Instead, polarization emerges from the interplay of two key properties: 1) a group polarization effect within clusters due to reinforcement, and 2) a gatekeeping effect at structural holes between clusters that contains opinion spread. This provides an “affective experience-based” route to polarization, complementing existing “deliberative argument-based” models.
In summary, the paper offers a minimal yet powerful mechanism for polarization grounded in reinforcement learning, establishes a formal bridge to game theory for analytical tractability, and highlights how network community structure interacts with simple social feedback to produce enduring societal divisions.
Comments & Academic Discussion
Loading comments...
Leave a Comment