Automatic Configuration of Deep Neural Networks with EGO
Designing the architecture for an artificial neural network is a cumbersome task because of the numerous parameters to configure, including activation functions, layer types, and hyper-parameters. With the large number of parameters for most networks nowadays, it is intractable to find a good configuration for a given task by hand. In this paper an Efficient Global Optimization (EGO) algorithm is adapted to automatically optimize and configure convolutional neural network architectures. A configurable neural network architecture based solely on convolutional layers is proposed for the optimization. Without using any knowledge on the target problem and not using any data augmentation techniques, it is shown that on several image classification tasks this approach is able to find competitive network architectures in terms of prediction accuracy, compared to the best hand-crafted ones in literature. In addition, a very small training budget (200 evaluations and 10 epochs in training) is spent on each optimized architectures in contrast to the usual long training time of hand-crafted networks. Moreover, instead of the standard sequential evaluation in EGO, several candidate architectures are proposed and evaluated in parallel, which saves the execution overheads significantly and leads to an efficient automation for deep neural network design.
💡 Research Summary
The paper presents a novel approach for automatically configuring deep neural networks by adapting the Efficient Global Optimization (EGO) algorithm to the problem of designing convolutional neural network (CNN) architectures. The authors first define a highly configurable “All‑CNN” architecture that consists solely of convolutional layers (except for the final dense layer). The network is built from q identical stacks; each stack contains a configurable number of convolutional layers, a stride‑2 convolution that plays the role of pooling, a dropout layer, and a set of hyper‑parameters (filter count, kernel size, L2 regularization, activation function, dropout probability). The stack size n is also a variable, allowing the overall network depth to range from very shallow to very deep configurations. In total, a three‑stack model has 26 architectural parameters plus two optimizer parameters (learning rate and decay), yielding a mixed integer‑continuous search space of the form C = ℝ⁶ × ℤ²⁰ × {0,1} × D², where D denotes the set of possible activation functions.
To explore this high‑dimensional heterogeneous space efficiently, the authors employ a Bayesian optimization framework based on EGO. Instead of the traditional Gaussian‑process surrogate, they use a random‑forest model because it handles mixed integer domains more robustly. An initial design of n points is generated via Latin Hypercube Sampling (LHS) and evaluated in parallel; these evaluations provide the training data for the surrogate. The acquisition function is a Moment‑Generating‑Function (MGF) based infill criterion M(x; t), which balances exploitation (predicted performance) and exploration (prediction uncertainty) through a temperature parameter t. To generate multiple candidates per iteration, the algorithm samples q temperature values from a log‑normal distribution, constructs q separate MGF criteria, and maximizes each using a Mixed‑Integer Evolution Strategy (MIES). This yields q candidate configurations that can be trained simultaneously on multiple GPUs, thereby converting the inherently sequential EGO into a parallel, batch‑mode optimizer.
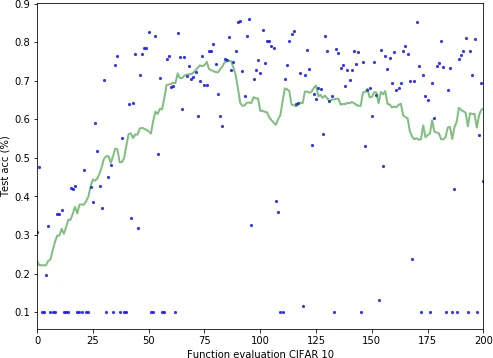
The experimental evaluation focuses on two standard image‑classification benchmarks: MNIST (28×28 grayscale, 10 classes) and CIFAR‑10 (32×32 color, 10 classes). For each dataset, the authors limit the total budget to 200 network evaluations, with each evaluation consisting of only 10 epochs for MNIST and 50 epochs for CIFAR‑10 (far fewer than the hundreds of epochs typically required for hand‑crafted networks). Despite this modest budget and the absence of data augmentation or problem‑specific priors, the best architectures discovered achieve competitive accuracies—over 99 % on MNIST and around 84 % on CIFAR‑10—comparable to state‑of‑the‑art hand‑designed models.
Key contributions of the work include: (1) a generic, fully‑convolutional network template that can represent a wide range of depths and widths while keeping the number of tunable parameters fixed; (2) the use of a random‑forest surrogate to model mixed integer‑continuous performance landscapes; (3) a temperature‑driven MGF acquisition function that enables simultaneous generation of diverse candidate points, facilitating parallel evaluation; (4) a practical demonstration that high‑quality CNN architectures can be discovered with a very limited evaluation budget, dramatically reducing the computational cost of neural‑architecture search. The authors suggest future extensions such as incorporating residual or attention blocks, scaling to larger datasets like ImageNet, and applying the method to multi‑task or transfer‑learning scenarios. Overall, the paper shows that Bayesian‑guided, parallel EGO can serve as an efficient and scalable tool for automated deep‑network design.
Comments & Academic Discussion
Loading comments...
Leave a Comment