Neural Voice Cloning with a Few Samples
Voice cloning is a highly desired feature for personalized speech interfaces. Neural network based speech synthesis has been shown to generate high quality speech for a large number of speakers. In this paper, we introduce a neural voice cloning syst…
Authors: Sercan O. Arik, Jitong Chen, Kainan Peng
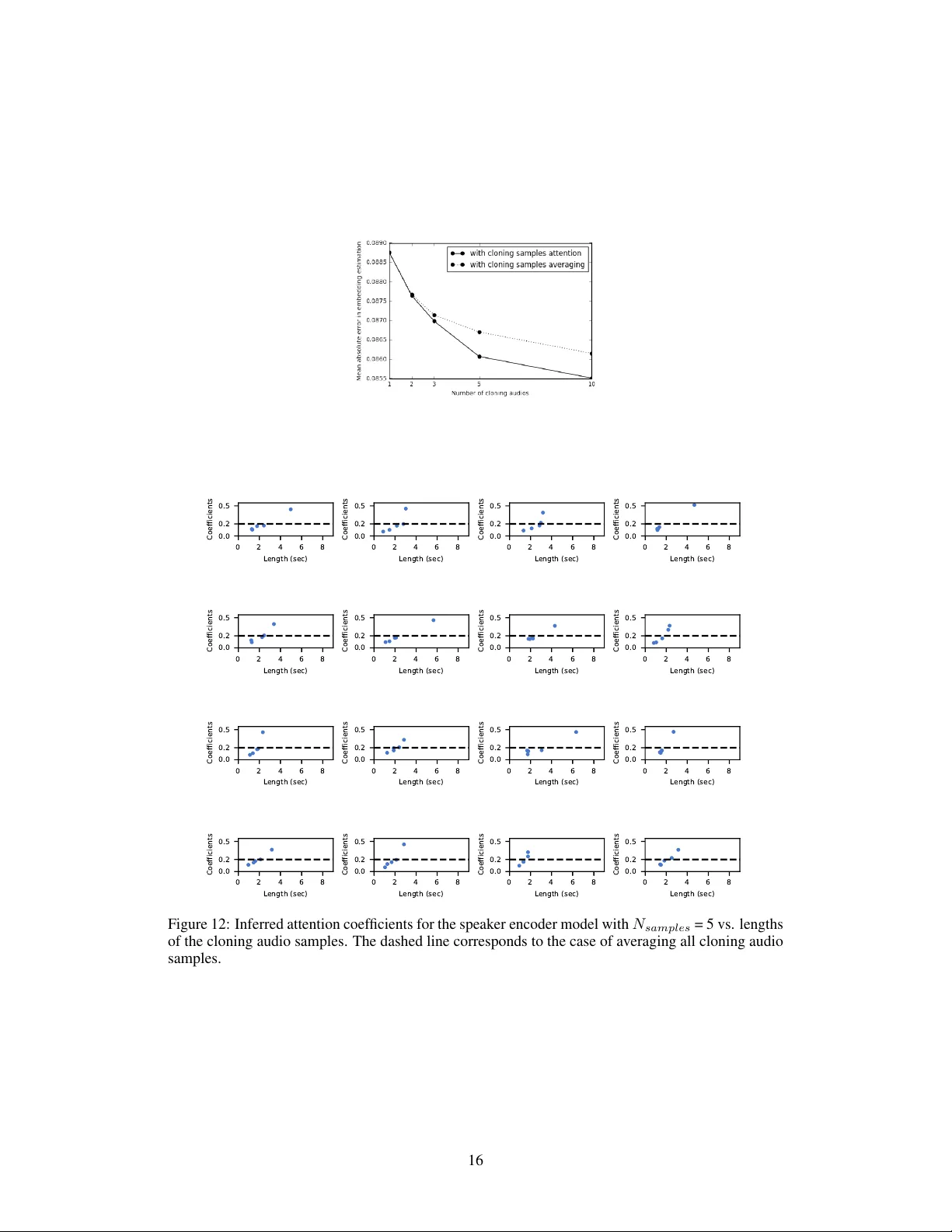
Neural V oice Cloning with a F ew Samples Sercan Ö. Arık ∗ sercanarik@baidu.com Jitong Chen ∗ chenjitong01@baidu.com Kainan Peng ∗ pengkainan@baidu.com W ei Ping ∗ pingwei01@baidu.com Y anqi Zhou yanqiz@baidu.com Baidu Research 1195 Bordeaux Dr . Sunnyv ale, CA 94089 Abstract V oice cloning is a highly desired feature for personalized speech interfaces. W e introduce a neural voice cloning system that learns to synthesize a person’ s voice from only a few audio samples. W e study two approaches: speaker adaptation and speaker encoding. Speaker adaptation is based on fine-tuning a multi-speak er generativ e model. Speaker encoding is based on training a separate model to directly infer a ne w speaker embedding, which will be applied to a multi-speak er generati ve model. In terms of naturalness of the speech and similarity to the original speaker , both approaches can achie ve good performance, e ven with a fe w cloning audios. 2 While speaker adaptation can achie ve slightly better naturalness and similarity , cloning time and required memory for the speaker encoding approach are significantly less, making it more fa vorable for lo w-resource deployment. 1 Introduction Generativ e models based on deep neural networks ha ve been successfully applied to many domains such as image generation [e.g., Oord et al. , 2016b , Karras et al. , 2017 ], speech synthesis [e.g., Oord et al. , 2016a , Arik et al. , 2017a , W ang et al. , 2017 ], and language modeling [e.g., Jozefo wicz et al. , 2016 ]. Deep neural networks are capable of modeling complex data distributions and can be further conditioned on external inputs to control the content and style of generated samples. In speech synthesis, generative models can be conditioned on text and speaker identity [e.g., Arik et al. , 2017b ]. While text carries linguistic information and controls the content of the generated speech, speaker identity captures characteristics such as pitch, speech rate and accent. One approach for multi-speak er speech synthesis is to jointly train a generative model and speaker embeddings on triplets of text, audio and speaker identity [e.g., Ping et al. , 2018 ]. The idea is to encode the speaker -dependent information with low-dimensional embeddings, while sharing the majority of the model parameters across all speakers. One limitation of such methods is that the y can only generate speech for observed speakers during training. An intriguing task is to learn the voice of an unseen speaker from a fe w speech samples, a.k.a. voice cloning , which corresponds to fe w-shot generati ve modeling of speech conditioned on the speak er identity . While a generative model can be trained from scratch with a lar ge amount of audio samples 3 , we focus on v oice cloning of a ne w speaker with a few minutes or e ven fe w seconds data. It is challenging as the model has to learn the speak er characteristics from very limited amount of data, and still generalize to unseen te xts. ∗ Equal contribution 2 Cloned audio samples can be found in https://audiodemos.github.io 3 A single speaker model can require ∼ 20 hours of training data [e.g., Arik et al. , 2017a , W ang et al. , 2017 ], while a multi-speaker model for 108 speakers [ Arik et al. , 2017b ] requires about ∼ 20 minutes data per speaker . 32nd Conference on Neural Information Processing Systems (NIPS 2018), Montréal, Canada. In this paper , we in vestigate voice cloning in sequence-to-sequence neural speech synthesis sys- tems [ Ping et al. , 2018 ]. Our contributions are the follo wing: 1. W e demonstrate and analyze the strength of speaker adaption approaches for voice cloning, based on fine-tuning a pre-trained multi-speaker model for an unseen speak er using a fe w samples. 2. W e propose a novel speaker encoding approach, which provides comparable naturalness and similarity in subjecti ve e valuations while yielding significantly less cloning time and computational resource requirements. 3. W e propose automated ev aluation methods for v oice cloning based on neural speaker classifi- cation and speaker verification. 4. W e demonstrate voice morphing for gender and accent transformation via embedding manip- ulations. 2 Related W ork Our work b uilds upon the state-of-the-art in neural speech synthesis and fe w-shot generativ e modeling. Neural speech synthesis: Recently , there is a surge of interest in speech synthesis with neu- ral networks, including Deep V oice 1 [ Arik et al. , 2017a ], Deep V oice 2 [ Arik et al. , 2017b ], Deep V oice 3 [ Ping et al. , 2018 ], W av eNet [ Oord et al. , 2016a ], SampleRNN [ Mehri et al. , 2016 ], Char2W av [ Sotelo et al. , 2017 ], T acotron [ W ang et al. , 2017 ] and V oiceLoop [ T aigman et al. , 2018 ]. Among these methods, sequence-to-sequence models [ Ping et al. , 2018 , W ang et al. , 2017 , Sotelo et al. , 2017 ] with attention mechanism ha ve much simpler pipeline and can produce more natural speech [e.g., Shen et al. , 2017 ]. In this work, we use Deep V oice 3 as the baseline multi-speaker model, because of its simple con volutional architecture and high efficiency for training and fast model adaptation. It should be noted that our techniques can be seamlessly applied to other neural speech synthesis models. Few-shot generati ve modeling: Humans can learn new generati ve tasks from only a few examples, which motiv ates research on few-shot generati ve models. Early studies mostly focus on Bayesian methods. For example, hierarchical Bayesian models are used to exploit compositionality and causality for fe w-shot generation of characters [ Lake et al. , 2013 , 2015 ] and words in speech [ Lake et al. , 2014 ]. Recently , deep neural networks achie ve great successes in fe w-shot density estimation and conditional image generation [e.g., Rezende et al. , 2016 , Reed et al. , 2017 , Azadi et al. , 2017 ], because of the great potential for composition in their learned representation. In this work, we in vestigate fe w-shot generati ve modeling of speech conditioned on a particular speaker . W e train a separate speak er encoding network to directly predict the parameters of multi-speaker generative model by only taking unsubscribed audio samples as inputs. Speaker -dependent speech processing: Speaker -dependent modeling has been widely studied for automatic speech recognition (ASR), with the goal of improving the performance by exploiting speaker characteristics. In particular , there are two groups of methods in neural ASR, in alignment with our tw o voice cloning approaches. The first group is speaker adaptation for the whole-model [ Y u et al. , 2013 ], a portion of the model [ Miao and Metze , 2015 , Cui et al. , 2017 ], or merely to a speaker embedding [ Abdel-Hamid and Jiang , 2013 , Xue et al. , 2014 ]. Speaker adaptation for voice cloning is in the same vein as these approaches, b ut differences arise when text-to-speech vs. speech-to-text are considered [ Y amagishi et al. , 2009 ]. The second group is based on training ASR models jointly with embeddings. Extraction of the embeddings can be based on i-vectors [ Miao et al. , 2015 ], or bottleneck layers of neural networks trained with a classification loss [ Li and W u , 2015 ]. Although the general idea of speaker encoding is also based on extracting the embeddings directly , as a major distinction, our speaker encoder models are trained with an objecti ve function that is directly related to speech synthesis. Lastly , speaker -dependent modeling is essential for multi-speak er speech synthesis. Using i-vectors to represent speaker-dependent characteristics is one approach [ W u et al. , 2015 ], ho wev er , they have the limitation of being separately trained, with an objectiv e that is not directly related to speech synthesis. Also they may not be accurately extracted with small amount of audio [ Miao et al. , 2015 ]. Another approach for multi-speak er speech synthesis is using trainable speaker embeddings [ Arik et al. , 2017b ], which are randomly initialized and jointly optimized from a generativ e loss function. 2 V oice con version: A closely related task of v oice cloning is voice con version. The goal of voice con version is to modify an utterance from source speaker to make it sound like the target speaker , while keeping the linguistic contents unchanged. Unlike voice cloning, v oice conv ersion systems do not need to generalize to unseen texts. One common approach is dynamic frequency w arping, to align spectra of dif ferent speakers. Agiomyrgiannakis and Roupakia [ 2016 ] proposes a dynamic programming algorithm that simultaneously estimates the optimal frequency warping and weighting transform while matching source and target speakers using a matching-minimization algorithm. W u et al. [ 2016 ] uses a spectral con version approach integrated with the locally linear embeddings for manifold learning. There are also approaches to model spectral con v ersion using neural networks [ Desai et al. , 2010 , Chen et al. , 2014 , Hw ang et al. , 2015 ]. Those models are typically trained with a large amount of audio pairs of tar get and source speakers. 3 From Multi-Speak er Generative Modeling to V oice Cloning W e consider a multi-speaker generativ e model, f ( t i,j , s i ; W , e s i ) , which takes a text t i,j and a speaker identity s i . The trainable parameters in the model is parameterized by W , and e s i . The latter denotes the trainable speaker em bedding corresponding to s i . Both W and e s i are optimized by minimizing a loss function L that penalizes the dif ference between generated and ground-truth audios (e.g. a regression loss for spectrograms): min W, e E s i ∼S , ( t i,j , a i,j ) ∼T s i { L ( f ( t i,j , s i ; W , e s i ) , a i,j ) } (1) where S is a set of speakers, T s i is a training set of text-audio pairs for speaker s i , and a i,j is the ground-truth audio for t i,j of speaker s i . The e xpectation is estimated over te xt-audio pairs of all training speakers. W e use c W and b e to denote the trained parameters and embeddings. Speak er embeddings hav e been sho wn to ef fectively capture speaker characteristics with lo w-dimensional vec- tors [ Arik et al. , 2017b , Ping et al. , 2018 ]. Despite training with only a generativ e loss, discriminative properties (e.g. gender and accent) are observ ed in the speaker embedding space [ Arik et al. , 2017b ]. For voice cloning, we extract the speak er characteristics for an unseen speaker s k from a set of cloning audios A s k , and generate an audio giv en any text for that speak er . The two performance metrics for the generated audio are speech naturalness and speaker similarity (i.e., whether the generated audio sounds like it is pronounced by the target speaker). The two approaches for neural v oice cloning are summarized in Fig. 1 and explained in the follo wing sections. 3.1 Speaker adaptation The idea of speaker adaptation is to fine-tune a trained multi-speaker model for an unseen speaker using a fe w audio-text pairs. Fine-tuning can be applied to either the speak er embedding [ T aigman et al. , 2018 ] or the whole model. For embedding-only adaptation, we hav e the following objecti ve: min e s k E ( t k,j , a k,j ) ∼T s k n L f ( t k,j , s k ; c W , e s k ) , a k,j o , (2) where T s k is a set of text-audio pairs for the target speaker s k . For whole model adaptation, we have the following objecti ve: min W, e s k E ( t k,j , a k,j ) ∼T s k { L ( f ( t k,j , s k ; W , e s k ) , a k,j ) } . (3) Although the entire model provides more degrees of freedom for speaker adaptation, its optimization is challenging for small amount of cloning data. Early stopping is required to av oid overfitting. 3.2 Speaker encoding W e propose a speaker encoding method to directly estimate the speaker embedding from audio samples of an unseen speaker . Such a model does not require any fine-tuning during voice cloning. Thus, the same model can be used for all unseen speakers. The speaker encoder , g ( A s k ; Θ ) , takes a set of cloning audio samples A s k and estimates e s k for speaker s k . The model is parametrized by Θ . Ideally , the speaker encoder can be jointly trained with the multi-speak er generativ e model from scratch, with a loss function defined for the generated audio: min W, Θ E s i ∼S , ( t i,j , a i,j ) ∼T s i { L ( f ( t i,j , s i ; W , g ( A s i ; Θ )) , a i,j ) } . (4) 3 Multi - speaker generative model Speaker embedding Text Audio Speaker encoder model Speaker embedding Cloning audio Multi - speaker generative model Speaker embedding Text Audio Speaker encoder model Cloning audio Speaker embedding Speaker encoder model Cloning audio Training Multi - speaker generative model Speaker embedding Text Audio Multi - speaker generative model Speaker embedding Multi - speaker generative model Speaker embedding Cloning text Cloning t ext Cloning audio Cloning audio Cloning or Multi - speaker generative model Text Audio Speaker embedding Audio generation Speaker adaptat ion Speaker encoding Trainable Fixed Multi - speaker generative model Text Audio Speaker embedding Figure 1: Illustration of speaker adaptation and speaker encoding approaches for v oice cloning. Note that the speak er encoder is trained with the speakers for the multi-speaker generati ve model. During training, a set of cloning audio samples A s i are randomly sampled for training speaker s i . During inference, audio samples from the target speaker s k , A s k , are used to compute g ( A s k ; Θ) . W e observed optimization challenges with joint training from scratch: the speak er encoder tends to estimate an av erage voice to minimize the o verall generati ve loss. One possible solution is to introduce discriminati ve loss functions for intermediate embeddings 4 or generated audios 5 . In our case, ho we ver , such approaches only slightly improve speaker differences. Instead, we propose a separate training procedure for speaker encoder . Speaker embeddings b e s i are extracted from a trained multi-speaker generati ve model f ( t i,j , s i ; W , e s i ) . Then, the speaker encoder g ( A s k ; Θ ) is trained with an L1 loss to predict the embeddings from sampled cloning audios: min Θ E s i ∼S {| g ( A s i ; Θ ) − b e s i ) |} . (5) Eventually , entire model can be jointly fine-tuned following Eq. 4 , with pre-trained c W and b Θ as the initialization. Fine-tuning encourages the generati ve model to compensate for embedding estimation errors, and may reduce attention problems. Howe ver , generativ e loss still dominates learning and speaker dif ferences in generated audios may be slightly reduced as well (see Section 4.3 for details). × N conv Mel spectr ograms Prenet Conv . bloc k Mean poolin g Self attention Speaker embedding Figure 2: Speaker encoder architecture. See Appendix A for details. For speaker encoder g ( A s k ; Θ ) , we propose a neural network architecture comprising three parts (as shown in Fig. 2 ): (i) Spectral pr ocessing : W e input mel-spectrograms of cloning audio samples to prenet, which contains fully-connected layers with exponential linear unit for feature transformation. (ii) T emporal pr ocessing : T o utilize long-term context, we use conv olutional layers with gated linear unit and residual connections, av erage pooling is applied to summarize the whole utterance. 4 W e have e xperimented classification loss by mapping the embeddings to labels via a softmax layer . 5 W e have e xperimented integrating a pre-trained classifier to encourage discrimination in generated audios. 4 (iii) Cloning sample attention : Considering that different cloning audios contain dif ferent amount of speaker information, we use a multi-head self-attention mechanism [ V aswani et al. , 2017 ] to compute the weights for different audios and get aggre gated embeddings. 3.3 Discriminative models f or ev aluation Besides human evaluations, we propose two e v aluation methods using discriminati ve models for voice cloning performance. 3.3.1 Speaker classification Speaker classifier determines which speak er an audio sample belongs to. For voice cloning ev aluation, a speaker classifier is trained with the set of speak ers used for cloning. High-quality voice cloning would result in high classification accuracy . The architecture is composed of similar spectral and temporal processing layers in Fig. 6 and an additional embedding layer before the softmax function. 3.3.2 Speaker verification Speaker verification is the task of authenticating the claimed identity of a speaker, based on a test audio and enrolled audios from the speaker . In particular , it performs binary classification to identify whether the test audio and enrolled audios are from the same speaker [e.g., Snyder et al. , 2016 ]. W e consider an end-to-end te xt-independent speak er v erification model [ Snyder et al. , 2016 ] (see Appendix C for more details of model architecture). The speaker v erification model can be trained on a multi-speaker dataset, and then used to v erify if the cloned audio and the ground-truth audio are from the same speaker . Unlike the speaker classification approach, speak er verification model does not require training with the audios from the tar get speaker for cloning, hence it can be used for unseen speakers with a fe w samples. As the quantitativ e performance metric, the equal error -rate (EER) 6 can be used to measure how close the cloned audios are to the ground truth audios. 4 Experiments 4.1 Datasets In our first set of experiments (Sections 4.3 and 4.4 ), the multi-speaker generative model and speaker encoder are trained using LibriSpeech dataset [ Panayotov et al. , 2015 ], which contains audios (16 KHz) for 2484 speakers, totalling 820 hours. LibriSpeech is a dataset for automatic speech recognition, and its audio quality is lower compared to speech synthesis datasets. 7 V oice cloning is performed on VCTK dataset [ V eaux et al. , 2017 ]. VCTK consists of audios sampled at 48 KHz for 108 nati ve speakers of English with v arious accents. T o be consistent with LibriSpeech dataset, VCTK audios are downsampled to 16 KHz. For a chosen speaker , a few cloning audios are randomly sampled for each experiment. The sentences presented in Appendix B are used to generate audios for ev aluation. In our second set of e xperiments (Section 4.5 ), we aim to in vestig ate the impact of the training dataset. W e split the VCTK dataset for training and testing: 84 speakers are used for training the multi-speaker model, 8 speakers for v alidation, and 16 speakers for cloning. 4.2 Model specifications Our multi-speaker generati ve model is based on the con volutional sequence-to-sequence architecture proposed in Ping et al. [ 2018 ], with similar hyperparameters and Grif fin-Lim vocoder . T o get better performance, we increase the time-resolution by reducing the hop length and windo w size parameters to 300 and 1200, and add a quadratic loss term to penalize large amplitude components superlinearly . For speaker adaptation e xperiments, we reduce the embedding dimensionality to 128, as it yields less ov erfitting problems. Overall, the baseline multi-speaker generati ve model has around 25M trainable parameters when trained for the LibriSpeech dataset. For the second set of experiments, hyperparameters of the VCTK model is used from Ping et al. [ 2018 ] to train a multi-speaker model for the 84 speakers of VCTK, with Grif fin-Lim vocoder . 6 EER is the point when the false acceptance rate and false rejection rate are equal. 7 W e designed a segmentation and denoising pipeline to process LibriSpeech, as in Ping et al. [ 2018 ]. 5 W e train speaker encoders for different number of cloning audios separately . Initially , cloning audios are con verted to log-mel spectrograms with 80 frequency bands, with a hop length of 400, a windo w size of 1600. Log-mel spectrograms are fed to spectral processing layers, which are composed of 2-layer prenet of size 128. Then, temporal processing is applied with tw o 1-D con volutional layers with a filter width of 12. Finally , multi-head attention is applied with 2 heads and a unit size of 128 for ke ys, queries and v alues. The final embedding size is 512. V alidation set consists 25 held-out speakers. A batch size of 64 is used, with an initial learning rate of 0.0006 with annealing rate of 0.6 applied ev ery 8000 iterations. Mean absolute error for the validation set is sho wn in Fig. 11 in Appendix D . More cloning audios leads to more accurate speak er embedding estimation, especially with the attention mechanism (see Appendix D for more details about the learned attention coefficients). W e train a speaker classifier using VCTK dataset to classify which of the 108 speakers an audio sample belongs to. Speaker classifier has a fully-connected layer of size 256, 6 con volutional layers with 256 filters of width 4, and a final embedding layer of size 32. The model achieves 100% accurac y for validation set of size 512. W e train a speaker verification model using LibriSpeech dataset. V alidation sets consists 50 held-out speakers from Librispeech. EERs are estimated by randomly pairing up utterances from the same or dif ferent speakers ( 50% for each case) in test set. W e perform 40960 trials for each test set. W e describe the details of speaker verification model in Appendix C . 4.3 V oice cloning perf ormance Speaker adaptation Speaker encoding Appr oaches Embedding-only Whole-model W ithout fine-tuning W ith fine-tuning Data T ext and audio Audio Cloning time ∼ 8 hours ∼ 0 . 5 − 5 mins ∼ 1 . 5 − 3 . 5 secs ∼ 1 . 5 − 3 . 5 secs Inference time ∼ 0 . 4 − 0 . 6 secs Parameters per speaker 128 ∼ 25 million 512 512 T able 1: Comparison of speaker adaptation and speaker encoding approaches. For speaker adaptation approach, we pick the optimal number of iterations using speaker classification accuracy . For speaker encoding, we consider v oice cloning with and without joint fine-tuning of the speaker encoder and multi-speaker generativ e model. 8 T able 1 summarizes the approaches and lists the requirements for training, data, cloning time and memory footprint. Figure 3: Performance of whole-model adaptation and speaker embedding adaptation for v oice cloning in terms of speaker classification accuracy for 108 VCTK speak ers. For speaker adaptation, Fig. 3 sho ws the speaker classification accuracy vs. the number of iterations. For both, the classification accuracy significantly increases with more samples, up to ten samples. In the low sample count regime, adapting the speaker embedding is less likely to ov erfit the samples 8 The learning rate and annealing parameters are optimized for joint fine-tuning. 6 (a) 1 2 3 5 10 20 50 100 Number of samples 0 2 4 6 8 10 12 14 Equal error rate (in %) LibriSpeech (unseen speakers) VCTK speaker adaption: embedding-only speaker adaption: whole-model speaker encoding: without fine-tuning speaker encoding: with fine-tuning (b) Figure 4: (a) Speaker classification accuracy with different numbers of cloning samples. (b) EER (using 5 enrollment audios) for different numbers of cloning samples. LibriSpeech (unseen speakers) and VCTK represent EERs estimated from random pairing of utterances from ground-truth datasets. than adapting the whole model. The two methods also require different numbers of iterations to con ver ge. Compared to whole-model adaptation (which con verges around 1000 iterations for e ven 100 cloning audio samples), embedding adaptation tak es significantly more iterations to con ver ge, thus it results in much longer cloning time. Figs. 4a and 4b sho w the classification accuracy and EER, obtained by speaker classification and speaker verification models. Both speaker adaptation and speaker encoding benefit from more cloning audios. When the number of cloning audio samples exceed fi ve, whole-model adaptation outperforms other techniques. Speaker encoding yields a lo wer classification accuracy compared to embedding adaptation, but the y achiev e a similar speaker verification performance. Besides ev aluations by discriminative models, we conduct subject tests on Amazon Mechanical T urk frame work. For assessment of the naturalness, we use the 5-scale mean opinion score (MOS). For assessment of ho w similar the generated audios are to the ground-truth audios from target speakers, we use the 4-scale similarity score with the question and categories in [ W ester et al. , 2016 ]. 9 T ables 2 and 3 sho w the results of human ev aluations. Higher number of cloning audios improve both metrics. The improv ement is more significant for whole model adaptation, due to the more degrees of freedom pro vided for an unseen speaker . Indeed, for high sample counts, the naturalness significantly exceeds the baseline model, due to the dominance of better quality adaptation samples ov er training data. Speaker encoding achiev es naturalness similar or better than the baseline model. The naturalness is e ven further improved with fine-tuning since it allo ws the generativ e model to learn ho w to compensate for the errors of the speaker encoder . Similarity scores slightly impro ve with higher sample counts for speaker encoding, and match the scores for speaker embedding adaptation. Appr oach Sample count 1 2 3 5 10 Ground-truth (16 KHz sampling rate) 4.66 ± 0.06 Multi-speaker generati ve model 2.61 ± 0.10 Speaker adaptation (embedding-only) 2.27 ± 0.10 2.38 ± 0.10 2.43 ± 0.10 2.46 ± 0.09 2.67 ± 0.10 Speaker adaptation (whole-model) 2.32 ± 0.10 2.87 ± 0.09 2.98 ± 0.11 2.67 ± 0.11 3.16 ± 0.09 Speaker encoding (without fine-tuning) 2.76 ± 0.10 2.76 ± 0.09 2.78 ± 0.10 2.75 ± 0.10 2.79 ± 0.10 Speaker encoding (with fine-tuning) 2.93 ± 0.10 3.02 ± 0.11 2.97 ± 0.1 2.93 ± 0.10 2.99 ± 0.12 T able 2: Mean Opinion Score (MOS) ev aluations for naturalness with 95% confidence intervals (training with LibriSpeech speakers and cloning with 108 VCTK speakers). 9 W e conduct each ev aluation independently , so the cloned audios of tw o different models are not directly compared during rating. Multiple v otes on the same sample are aggregated by a majority v oting rule. 7 Appr oach Sample count 1 2 3 5 10 Ground-truth (same speaker) 3.91 ± 0.03 Ground-truth (different speak ers) 1.52 ± 0.09 Speaker adaptation (embedding-only) 2.66 ± 0.09 2.64 ± 0.09 2.71 ± 0.09 2.78 ± 0.10 2.95 ± 0.09 Speaker adaptation (whole-model) 2.59 ± 0.09 2.95 ± 0.09 3.01 ± 0.10 3.07 ± 0.08 3.16 ± 0.08 Speaker encoding (without fine-tuning) 2.48 ± 0.10 2.73 ± 0.10 2.70 ± 0.11 2.81 ± 0.10 2.85 ± 0.10 Speaker encoding (with fine-tuning) 2.59 ± 0.12 2.67 ± 0.12 2.73 ± 0.13 2.77 ± 0.12 2.77 ± 0.11 T able 3: Similarity score ev aluations with 95% confidence interv als (training with LibriSpeech speakers and cloning with 108 VCTK speakers). 4.4 V oice morphing via embedding manipulation As shown in Fig. 5 , speaker encoder maps speakers into a meaningful latent space. Inspired by word embedding manipulation (e.g. to demonstrate the e xistence of simple algebraic operations as king - queen = male - female ), we apply algebraic operations to inferred embeddings to transform their speech characteristics. T o transform gender, we estimate the a veraged speaker embeddings for each gender , and add their dif ference to a particular speaker . For example, BritishMale + A ver agedF emale - A ver agedMale yields a British female speaker . Similarly , we consider re gion of accent transformation via BritishMale + A ver agedAmerican - A ver agedBritish to obtain an American male speaker . Our results demonstrate high quality audios with specific gender and accent characteristics. 10 -0.6 -0.4 -0.2 0.0 0.2 0.4 0.6 -0.2 -0.1 0.0 0.1 0.2 0.3 Average North American male Average North American female Average British male Average British female Average male Average female -0.6 -0.4 -0.2 0.0 0.2 0.4 0.6 -0.2 -0.1 0.0 0.1 0.2 0.3 Average North American male Average North American female Average British male Average British female Average British Average North American Figure 5: V isualization of estimated speaker embeddings by speaker encoder . The first tw o principal components of speaker embeddings (a veraged across 5 samples for each speaker). Only British and North American regional accents are sho wn as they constitute the majority of the labeled speak ers in the VCTK dataset. Please see Appendix E for more detailed analysis. 4.5 Impact of training dataset Appr oach Sample count 1 5 10 20 100 Speaker adaptation (embedding-only) 3.01 ± 0.11 - 3.13 ± 0.11 - 3.13 ± 0.11 Speaker adaptation (whole-model) 2.34 ± 0.13 2.99 ± 0.10 3.07 ± 0.09 3.40 ± 0.10 3.38 ± 0.09 T able 4: Mean Opinion Score (MOS) ev aluations for naturalness with 95% confidence intervals (training with 84 VCTK speakers and cloning with 16 VCTK speakers). Appr oach Sample count 1 5 10 20 100 Speaker adaptation (embedding-only) 2.42 ± 0.13 - 2.37 ± 0.13 - 2.37 ± 0.12 Speaker adaptation (whole-model) 2.55 ± 0.11 2.93 ± 0.11 2.95 ± 0.10 3.01 ± 0.10 3.14 ± 0.10 T able 5: Similarity score ev aluations with 95% confidence interv als (training with 84 VCTK speak ers and cloning with 16 VCTK speakers). T o ev aluate the impact of the dataset, we consider training with a subset of the VCTK containing 84 speakers, and cloning on another 16 speakers. T ables 4 and 5 present the human ev aluations 10 https://audiodemos.github.io/ 8 for speaker adaptation. 11 Speaker verification results are gi ven in Appendix C . One the one hand, compared to LibriSpeech, cleaner VCTK data improves the multi-speaker generati ve model, leading to better whole-model adaptation results. On the other hand, embedding-only adaptation significantly underperforms whole-model adaptation due to the limited speaker di versity in VCTK dataset. 5 Conclusions W e study tw o approaches for neural voice cloning: speaker adaptation and speaker encoding. W e demonstrate that both approaches can achiev e good cloning quality ev en with only a fe w cloning audios. For naturalness, we sho w that both speaker adaptation and speaker encoding can achieve an MOS similar to the baseline multi-speaker generati ve model. Thus, the proposed techniques can potentially be improv ed with better multi-speak er models in the future (such as replacing Grif fin- Lim with W aveNet vocoder). For similarity , we demonstrate that both approaches benefit from a larger number of cloning audios. The performance gap between whole-model and embedding-only adaptation indicates that some discriminativ e speaker information still exists in the generati ve model besides speaker embeddings. The benefit of compact representation via embeddings is fast cloning and small footprint per speaker . W e observe drawbacks of training the multi-speaker generativ e model using a speech recognition dataset with low-quality audios and limited speaker diversity . Improv ements in the quality of dataset would result in higher naturalness. W e expect our techniques to benefit significantly from a large-scale and high-quality multi-speak er dataset. References O. Abdel-Hamid and H. Jiang. Fast speaker adaptation of hybrid nn/hmm model for speech recogni- tion based on discriminativ e learning of speaker code. In IEEE ICASSP , 2013. Y . Agiomyrgiannakis and Z. Roupakia. V oice morphing that improv es tts quality using an optimal dynamic frequency warping-and-weighting transform. IEEE ICASSP , 2016. D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Battenberg, C. Case, J. Casper , B. Catanzaro, Q. Cheng, G. Chen, et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In International Confer ence on Machine Learning , pages 173–182, 2016. S. Ö. Arik, M. Chrzano wski, A. Coates, G. Diamos, A. Gibiansky , Y . Kang, X. Li, J. Miller , J. Raiman, S. Sengupta, and M. Shoeybi. Deep Voice: Real-time neural text-to-speech. In ICML , 2017a. S. Ö. Arik, G. F . Diamos, A. Gibiansky , J. Miller , K. Peng, W . Ping, J. Raiman, and Y . Zhou. Deep Voice 2: Multi-speaker neural text-to-speech. In NIPS , pages 2966–2974, 2017b. S. Azadi, M. Fisher , V . Kim, Z. W ang, E. Shechtman, and T . Darrell. Multi-content gan for few-shot font style transfer . CoRR , abs/1708.02182, 2017. L. H. Chen, Z. H. Ling, L. J. Liu, and L. R. Dai. V oice con version using deep neural networks with layer-wise generativ e training. IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , 2014. X. Cui, V . Goel, and G. Saon. Embedding-based speaker adapti ve training of deep neural networks. arXiv pr eprint arXiv:1710.06937 , 2017. S. Desai, A. W . Black, B. Y e gnanarayana, and K. Prahallad. Spectral mapping using artificial neural networks for v oice con version. IEEE T ransactions on A udio, Speech, and Languag e Pr ocessing , 2010. H. T . Hwang, Y . Tsao, H. M. W ang, Y . R. W ang, and S. H. Chen. A probabilistic interpretation for artificial neural netw ork-based voice conv ersion. In 2015 Asia-P acific Signal and Information Pr ocessing Association Annual Summit and Confer ence (APSIP A) , 2015. R. Jozefowicz, O. V inyals, M. Schuster , N. Shazeer , and Y . W u. Exploring the limits of language modeling. arXiv pr eprint arXiv:1602.02410 , 2016. 11 The speaker encoder models generalize poorly for unseen speakers due to limited training speak ers. 9 T . Karras, T . Aila, S. Laine, and J. Lehtinen. Progressiv e growing of gans for improved quality , stability , and variation. CoRR , abs/1710.10196, 2017. B. M. Lake, R. Salakhutdinov , and J. B. T enenbaum. One-shot learning by inv erting a compositional causal process. In NIPS , 2013. B. M. Lake, C. ying Lee, J. R. Glass, and J. B. T enenbaum. One-shot learning of generativ e speech concepts. In CogSci , 2014. B. M. Lake, R. Salakhutdino v , and J. B. T enenbaum. Human-lev el concept learning through proba- bilistic program induction. Science , 2015. X. Li and X. W u. Modeling speaker v ariability using long short-term memory networks for speech recognition. In INTERSPEECH , 2015. S. Mehri, K. Kumar , I. Gulrajani, R. Kumar , S. Jain, J. Sotelo, A. Courville, and Y . Bengio. Samplernn: An unconditional end-to-end neural audio generation model. arXiv preprint , 2016. Y . Miao and F . Metze. On speaker adaptation of long short-term memory recurrent neural networks. In Sixteenth Annual Confer ence of the International Speech Communication Association , 2015. Y . Miao, H. Zhang, and F . Metze. Speaker adapti ve training of deep neural network acoustic models using i-vectors. IEEE/ACM T ransactions on Audio, Speec h, and Language Pr ocessing , 2015. A. v . d. Oord, S. Dieleman, H. Zen, K. Simonyan, O. V inyals , A. Graves, N. Kalchbrenner, A. Senior , and K. Kavukcuoglu. W av enet: A generati ve model for raw audio. arXiv preprint arXiv:1609.03499 , 2016a. A. v . d. Oord, N. Kalchbrenner , L. Espeholt, O. V inyals, A. Grav es, et al. Conditional image generation with pixelcnn decoders. In Advances in Neural Information Pr ocessing Systems , 2016b. V . Panayoto v , G. Chen, D. Po vey , and S. Khudanpur . Librispeech: an ASR corpus based on public domain audio books. In IEEE ICASSP , 2015. W . Ping, K. Peng, A. Gibiansky , S. Arik, A. Kannan, S. Narang, J. Raiman, and J. Miller . Deep Voice 3: Scaling text-to-speech with con volutional sequence learning. In ICLR , 2018. S. Prince and J. Elder . Probabilistic linear discriminant analysis for inferences about identity . In ICCV , 2007. S. E. Reed, Y . Chen, T . Paine, A. v an den Oord, S. M. A. Eslami, D. J. Rezende, O. V inyals, and N. de Freitas. Fe w-shot autoregressi ve density estimation: T owards learning to learn distrib utions. CoRR , 2017. D. Rezende, Shakir, I. Danihelka, K. Gregor , and D. Wierstra. One-shot generalization in deep generativ e models. In ICML , 2016. J. Shen, R. Pang, R. J. W eiss, M. Schuster , N. Jaitly , Z. Y ang, Z. Chen, Y . Zhang, Y . W ang, R. Skerry- Ryan, et al. Natural tts synthesis by conditioning wav enet on mel spectrogram predictions. arXiv pr eprint arXiv:1712.05884 , 2017. D. Snyder , P . Ghahremani, D. Povey , D. Garcia-Romero, Y . Carmiel, and S. Khudanpur . Deep neural network-based speaker embeddings for end-to-end speak er verification. In IEEE Spoken Language T echnolo gy W orkshop (SLT) , pages 165–170, 2016. J. Sotelo, S. Mehri, K. Kumar , J. F . Santos, K. Kastner, A. Courville, and Y . Bengio. Char2wa v: End-to-end speech synthesis. 2017. Y . T aigman, L. W olf, A. Polyak, and E. Nachmani. V oiceloop: V oice fitting and synthesis via a phonological loop. In ICLR , 2018. A. V aswani, N. Shazeer , N. Parmar , J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser , and I. Polosukhin. Attention is all you need. In NIPS . 2017. 10 C. V eaux, J. Y amagishi, and K. e. a. MacDonald. Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit, 2017. Y . W ang, R. J. Skerry-Ryan, D. Stanton, Y . W u, R. J. W eiss, N. Jaitly , Z. Y ang, Y . Xiao, Z. Chen, S. Bengio, Q. V . Le, Y . Agiomyrgiannakis, R. Clark, and R. A. Saurous. T acotron: A fully end-to-end text-to-speech synthesis model. CoRR , abs/1703.10135, 2017. M. W ester, Z. W u, and J. Y amagishi. Analysis of the voice con version challenge 2016 ev aluation results. In INTERSPEECH , pages 1637–1641, 09 2016. Y .-C. W u, H.-T . Hwang, C.-C. Hsu, Y . Tsao, and H.-m. W ang. Locally linear embedding for ex emplar-based spectral con version. In INTERSPEECH , pages 1652–1656, 09 2016. Z. W u, P . Swietojanski, C. V eaux, S. Renals, and S. King. A study of speaker adaptation for dnn-based speech synthesis. In INTERSPEECH , 2015. S. Xue, O. Abdel-Hamid, H. Jiang, L. Dai, and Q. Liu. Fast adaptation of deep neural netw ork based on discriminant codes for speech recognition. IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , 2014. J. Y amagishi, T . Kobayashi, Y . Nakano, K. Ogata, and J. Isogai. Analysis of speaker adaptation algorithms for hmm-based speech synthesis and a constrained smaplr adaptation algorithm. IEEE T r ansactions on Audio, Speech, and Langua ge Pr ocessing , 2009. D. Y u, K. Y ao, H. Su, G. Li, and F . Seide. Kl-div ergence regularized deep neural network adaptation for improv ed large vocab ulary speech recognition. In IEEE ICASSP , 2013. 11 A ppendices A Detailed speaker encoder ar chitecture Multi - head attention FC [batch, N samples , T, F mapped ] [batch, N samples , F mapped ] [batch, N samples , d embedding ] ELU FC ELU keys queries valu es [batch, N samples , d attn ] [batch, N samples , d attn ] Softsign FC [batch, N samples ] Normalize [batch, N samples ] [batch, N samples ] FC [batch, d embedding ] Convolution Gated linear unit × [batch, N samples , T, F mel ] × √0.5 Te m p o r a l m a s k i n g Global mean pooling × N conv × N prenet FC ELU FC ELU Mel spectrograms Speaker embedding Cloning samples attention Te m p o r a l p r o c e s s i n g Spectral proces sing [batch, N samples , T, F mapped ] [batch, N samples , T, F mapped ] Figure 6: Speaker encoder architecture with intermediate state dimensions. ( batch : batch size, N samples : number of cloning audio samples | A s k | , T : number of mel spectrograms timeframes, F mel : number of mel frequency channels, F mapped : number of frequency channels after prenet, d embedding : speaker embedding dimension). Multiplication operation at the last layer represents inner product along the dimension of cloning samples. 12 B V oice cloning test sentences Prosecutors have opened a massive investigation/into allegations of/fixing games/and illegal betting%. Different telescope designs/perform differently%and have different strengths/and weaknesses%. We can continue to strengthen the education of good lawyers%. Feedback must be timely/and accurate/throughout the project%. Humans also judge distance/by using the relative sizes of objects%. Churches should not encourage it%or make it look harmless%. Learn about/setting up/wireless network configuration%. You can eat them fresh cooked%or fermented%. If this is true%then those/who tend to think creatively%really are somehow different%. She will likely jump for joy%and want to skip straight to the honeymoon%. The sugar syrup/should create very fine strands of sugar%that drape over the handles%. But really in the grand scheme of things%this information is insignificant%. I let the positive/overrule the negative%. He wiped his brow/with his forearm%. Instead of fixing it%they give it a nickname%. About half the people%who are infected%also lose weight%. The second half of the book%focuses on argument/and essay writing%. We have the means/to help ourselves%. The large items/are put into containers/for disposal%. He loves to/watch me/drink this stuff%. Still%it is an odd fashion choice%. Funding is always an issue/after the fact%. Let us/encourage each other%. Figure 7: The sentences used to generate test samples for the voice cloning models. The white space characters / and % follow the same definition as in Ping et al. [ 2018 ]. 13 C Speaker verification model Giv en a set of (e.g., 1 ∼ 5) enrollment audios 12 and a test audio, speaker verification model per- forms a binary classification and tells whether the enrollment and test audios are from the same speaker . Although using other speaker verification models [e.g., Sn yder et al. , 2016 ] would also suffice, we choose to create our own speaker verification models using con volutional-recurrent architecture [ Amodei et al. , 2016 ]. W e note that our equal-error -rate results on test set of unseen speakers are on par with the state-of-the-art speaker v erification models. The architecture of our model is illustrated in Figure 8 . W e compute mel-scaled spectrogram of enrollment audios and test audio after resampling the input to a constant sampling frequency . Then, we apply two-dimensional con volutional layers con v olving over both time and frequency bands, with batch normalization and ReLU non-linearity after each con volution layer . The output of last conv olution layer is feed into a recurrent layer (GRU). W e then mean-pool o ver time (and enrollment audios if there are many), then apply a fully connected layer to obtain the speak er encodings for both enrollment audios and test audio. W e use the probabilistic linear discriminant analysis (PLD A) for scoring the similarity between the two encodings [ Prince and Elder , 2007 , Snyder et al. , 2016 ]. The PLD A score [ Sn yder et al. , 2016 ] is defined as, s ( x , y ) = w · x > y − x > S x − y > S y + b (6) where x and y are speaker encodings of enrollment and test audios respecti vely after fully-connected layer , w and b are scalar parameters, and S is a symmetric matrix. Then, s ( x , y ) is feed into a sigmoid unit to obtain the probability that they are from the same speaker . The model is trained using cross-entropy loss. T able 6 lists hyperparameters of speaker verification model for LibriSpeech dataset. In addition to speaker verification test results presented in main text (Figure 4b ), we also include the result using 1 enrollment audio when the multi-speaker generati ve model is trained on LibriSpeech. When multi-speaker generati ve model is trained on VCTK, the results are in Figure 10 . It should be noted that, the EER on cloned audios could be potentially better than on ground truth VCTK, because the speaker verification model is trained on LibriSpeech dataset. 2D convol ution Mel spectrograms FC ! b atch -nom x N ReLU enroll audios Conv . block recurrent layer pooling Mel spectrogram test audio SV module PLDA score same or different speaker Figure 8: Architecture of speaker verification model. 12 Enrollment audios are from the same speaker . 14 Parameter Audio resampling freq. 16 KHz Bands of Mel-spectrogram 80 Hop length 400 Con volution layers, channels, filter , strides 1 , 64, 20 × 5 , 8 × 2 Recurrent layer size 128 Fully connected size 128 Dropout probability 0.9 Learning Rate 10 − 3 Max gradient norm 100 Gradient clipping max. v alue 5 T able 6: Hyperparameters of speaker verification model for LibriSpeech dataset. 1 2 3 5 10 20 50 100 Number of samples 0 5 10 15 20 25 Equal error rate (in %) LibriSpeech (unseen speakers) VCTK speaker adaption: embedding-only speaker adaption: whole-model speaker encoding: without fine-tuning speaker encoding: with fine-tuning Figure 9: Speaker verification EER (using 1 enrollment audio) vs. number of cloning audio samples. Multi-speaker generati ve model and speaker verification model are trained using LibriSpeech dataset. V oice cloing is performed using VCTK dataset. 1 5 10 20 50 100 Number of samples 0 5 10 15 20 25 30 35 Equal error rate (in %) LibriSpeech (unseen speakers) VCTK speaker adaption: embedding-only speaker adaption: whole-model 1 5 10 20 50 100 0 5 10 15 20 25 30 35 LibriSpeech (unseen speakers) VCTK speaker adaption: embedding-only speaker adaption: whole-model (a) (b) Figure 10: Speaker verification EER using (a) 1 enrollment audio (b) 5 enrollment audios vs. number of cloning audio samples. Multi-speaker generati ve model is trained on a subset of VCTK dataset including 84 speakers, and voice cloning is performed on other 16 speak ers. Speaker v erification model is trained using the LibriSpeech dataset. 15 D Implications of attention For a trained speak er encoder model, Fig. 12 exemplifies attention distributions for dif ferent audio lengths. The attention mechanism can yield highly non-uniformly distributed coefficients while combining the information in different cloning samples, and especially assigns higher coefficients to longer audios, as intuitiv ely expected due to the potential more information content in them. Figure 11: Mean absolute error in embedding estimation vs. the number of cloning audios for a validation set of 25 speak ers, shown with the attention mechanism and without attention mechanism (by simply av eraging). 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients 0 2 4 6 8 Length (sec) 0.0 0.2 0.5 Coefficients Figure 12: Inferred attention coefficients for the speaker encoder model with N samples = 5 vs. lengths of the cloning audio samples. The d a shed line corresponds to the case of a veraging all cloning audio samples. 16 E Speaker embedding space lear ned by the encoder T o analyze the speaker embedding space learned by the trained speake r encoders, we apply principal component analysis to the space of inferred embeddings and consider their ground truth labels for gender and region of accent from the VCTK dataset. Fig. 13 sho ws visualization of the first two principal components. W e observe that speaker encoder maps the cloning audios to a latent space with highly meaningful discriminati ve patterns. In particular for gender , a one dimensional linear transformation from the learned speaker embeddings can achie ve a very high discriminati ve accuracy - although the models nev er see the ground truth gender label while training. Sample count:1 Sample count:1 Sample count:2 Sample count:2 Sample count:3 Sample count:3 Sample count:5 Sample count:5 Sample count:10 Sample count:10 Female Male Great Britain North American Ireland South Hemisphere Asia Figure 13: First two principal components of the inferred embeddings, with the ground truth labels for gender and region of accent for the VCTK speakers as in Arik et al. [ 2017b ]. 17 F Similarity scores For the result in T able 3 , Fig. 14 sho ws the distribution of the scores gi ven by MT urk users as in [ W ester et al. , 2016 ]. For 10 sample count, the ratio of e v aluations with the ‘same speaker’ rating exceeds 70 % for all models. Figure 14: Distribution of similarity scores for 1 and 10 sample counts. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment