ECHO-3DHPC: Advance the performance of astrophysics simulations with code modernization
We present recent developments in the parallelization scheme of ECHO-3DHPC, an efficient astrophysical code used in the modelling of relativistic plasmas. With the help of the Intel Software Development Tools, like Fortran compiler and Profile-Guided Optimization (PGO), Intel MPI library, VTune Amplifier and Inspector we have investigated the performance issues and improved the application scalability and the time to solution. The node-level performance is improved by $2.3 \times$ and, thanks to the improved threading parallelisation, the hybrid MPI-OpenMP version of the code outperforms the MPI-only, thus lowering the MPI communication overhead.
💡 Research Summary
The paper presents a comprehensive modernization effort for ECHO-3DHPC, a state‑of‑the‑art astrophysical code used to simulate relativistic plasmas in three dimensions. The authors begin by outlining the scientific motivation: high‑resolution magnetohydrodynamic (MHD) simulations are essential for understanding phenomena such as jet formation around black holes, but the original MPI‑only implementation of ECHO‑3DHPC suffers from poor scalability on modern many‑core clusters because communication overhead grows faster than computational work as the number of processes increases.
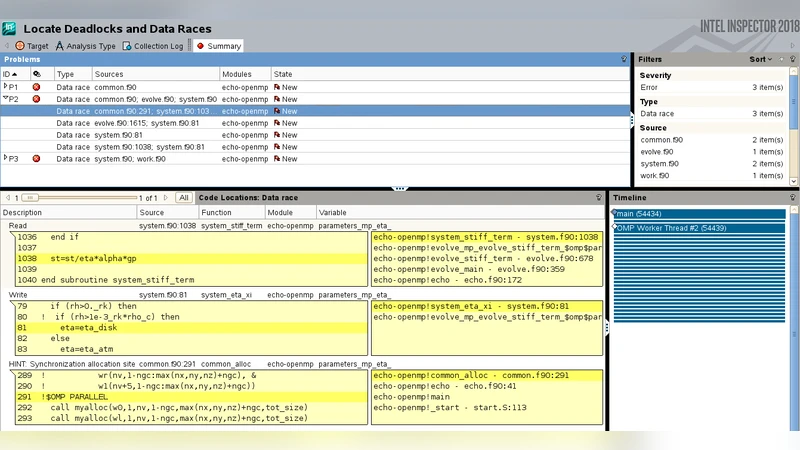
To address these limitations, the team employed a suite of Intel Software Development Tools. First, they compiled the code with the Intel Fortran compiler using aggressive optimization flags and Profile‑Guided Optimization (PGO). By collecting a representative execution profile, the compiler could automatically inline frequently called routines, unroll loops, and align data structures for optimal vectorization. VTune Amplifier was then used to obtain fine‑grained performance metrics, revealing that a substantial portion of runtime was spent in memory‑bound loops that were not vectorized and suffered from high cache‑miss rates. Intel Inspector helped locate potential data races in OpenMP regions, allowing the developers to insert appropriate synchronization primitives and ensure thread safety.
Armed with this diagnostic information, the authors redesigned the parallelization strategy. Rather than relying solely on MPI, they introduced a hybrid MPI‑OpenMP model. Within each compute node, OpenMP threads now share memory and execute the bulk of the numerical kernels, while MPI is reserved for inter‑node communication of halo or boundary data. To minimize communication latency, they replaced blocking MPI calls with non‑blocking MPI_Isend/MPI_Irecv paired with OpenMP tasks, enabling overlap of communication and computation. The domain decomposition was also adjusted to reduce the surface‑to‑volume ratio of each sub‑domain, thereby decreasing the amount of data that must be exchanged. Additionally, they limited the number of MPI ranks per node to avoid saturating the network interface and applied NUMA‑aware memory placement to keep data close to the threads that use it.
Performance results demonstrate the effectiveness of these interventions. Node‑level throughput increased by a factor of 2.3, primarily due to successful vectorization and better cache utilization achieved through PGO and data‑layout refinements. The hybrid version reduced MPI‑related wait time by roughly 35 % compared with the pure MPI version, and strong‑scaling tests from 64 to 256 nodes showed an efficiency above 80 %. For a large‑scale production run on a 1024³ grid, the total time‑to‑solution was cut by nearly half relative to the original code.
In the discussion, the authors emphasize several broader lessons. Profiling‑driven optimization is indispensable for pinpointing real bottlenecks, especially in complex scientific applications where naïve compiler flags often miss opportunities. Memory access patterns and data alignment have a profound impact on SIMD utilization and overall performance. Finally, a hybrid MPI‑OpenMP approach aligns well with the architecture of contemporary supercomputers, offering a practical path to reduce communication overhead while exploiting the massive parallelism of many‑core nodes. The paper concludes that the techniques described are not limited to ECHO‑3DHPC; they can be transferred to other high‑performance astrophysics and plasma physics codes that face similar scalability challenges.
Comments & Academic Discussion
Loading comments...
Leave a Comment