Recognizing Overlapped Speech in Meetings: A Multichannel Separation Approach Using Neural Networks
The goal of this work is to develop a meeting transcription system that can recognize speech even when utterances of different speakers are overlapped. While speech overlaps have been regarded as a major obstacle in accurately transcribing meetings, a traditional beamformer with a single output has been exclusively used because previously proposed speech separation techniques have critical constraints for application to real meetings. This paper proposes a new signal processing module, called an unmixing transducer, and describes its implementation using a windowed BLSTM. The unmixing transducer has a fixed number, say J, of output channels, where J may be different from the number of meeting attendees, and transforms an input multi-channel acoustic signal into J time-synchronous audio streams. Each utterance in the meeting is separated and emitted from one of the output channels. Then, each output signal can be simply fed to a speech recognition back-end for segmentation and transcription. Our meeting transcription system using the unmixing transducer outperforms a system based on a state-of-the-art neural mask-based beamformer by 10.8%. Significant improvements are observed in overlapped segments. To the best of our knowledge, this is the first report that applies overlapped speech recognition to unconstrained real meeting audio.
💡 Research Summary
The paper addresses the long‑standing challenge of recognizing overlapped speech in real‑world meetings, where multiple speakers may talk simultaneously and traditional single‑output beamformers struggle. The authors introduce a novel signal‑processing module called the “unmixing transducer.” This module receives multi‑channel microphone array recordings and converts them into a fixed number J of time‑synchronous audio streams (the experiments use J = 2). Each utterance in the meeting is assigned to exactly one output channel; when fewer speakers are active than J, the remaining channels emit zero‑valued signals. Consequently, the downstream automatic speech recognition (ASR) back‑ends can operate independently on each stream without needing speaker‑count estimation or complex diarization.
Technical core
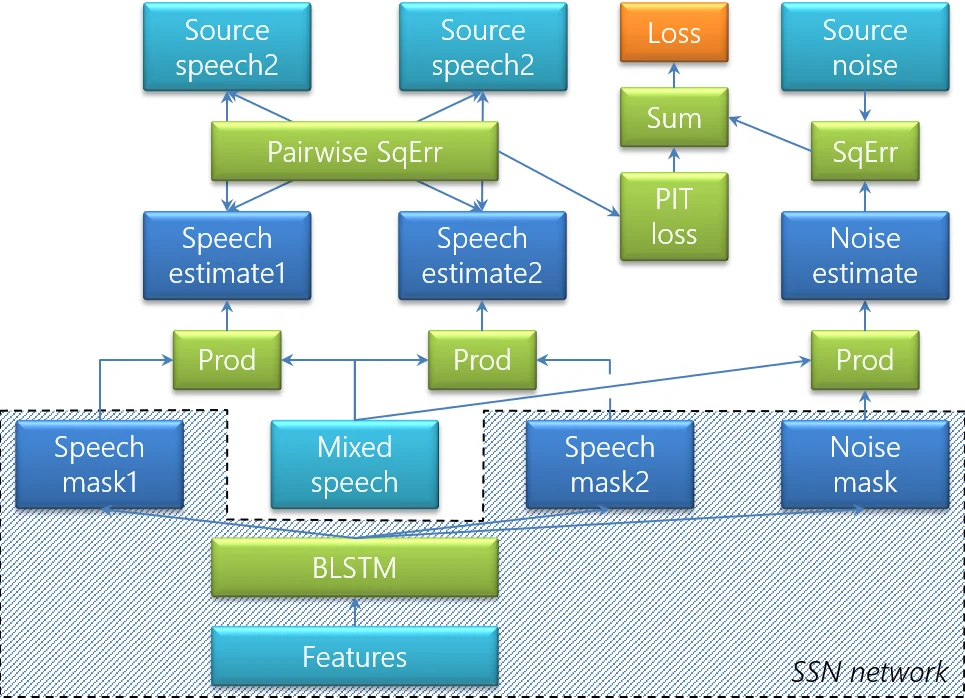
The unmixing transducer is built around a windowed bidirectional LSTM (BLSTM). Because meetings can last tens of minutes to hours, the audio is segmented into overlapping 2.4‑second windows with 75 % overlap. For each window the BLSTM predicts three masks: two speech masks (one per output channel) and one noise mask. Input features combine the magnitude spectrum of a reference microphone with inter‑microphone phase differences (IPDs) that are mean‑normalized over a four‑second rolling window; the phase‑wrapping issue is handled by applying the Arg operation after normalization.
Training uses permutation‑invariant training (PIT) to resolve the label‑permutation problem inherent in two‑speaker separation. For each training example (up to 10 seconds long) the loss is the minimum over the two possible assignments of the predicted masks to the reference sources. The training data consist of 567 hours of simulated mixtures created from WSJ and LibriSpeech utterances, reverberated with the image method, and corrupted by spherical isotropic background noise.
After mask estimation, the masks are stitched across windows. Since PIT does not guarantee a consistent ordering across windows, the system evaluates the cost of each possible permutation for the current window by summing squared differences of overlapping frames with the previous window; the lower‑cost permutation is selected, and the non‑overlapping portion of the current window is emitted. This stitching incurs minimal latency while preserving utterance continuity.
To make the separated streams suitable for modern ASR, the authors replace raw masking with a mask‑based MVDR beamformer. The target and interference spatial covariance matrices are derived from the speech masks and the complement (1 – mask). However, the simple complement is a poor estimate of interference, especially when the interference consists of another speaker plus background noise. Therefore, the authors extend the separation network to a “speech‑speech‑noise” (SSN) architecture that adds a dedicated noise mask output. The interference covariance is then modeled as the sum of the other speaker’s speech covariance and the noise covariance, yielding more accurate beamformer weights.
System integration
The full meeting transcription pipeline consists of: (1) a seven‑channel circular microphone array, (2) a weighted prediction error (WPE) dereverberation front‑end updated every second, (3) the unmixing transducer producing two dereverberated streams, and (4) two identical ASR back‑ends. The ASR acoustic model is trained on roughly 7 000 hours of spontaneous speech (public corpora such as Switchboard/Fisher and internal lecture recordings) using 40‑dimensional mel‑filterbank features with a 10th‑root compression, followed by four 1 024‑unit LSTM layers and sequence discriminative training. Decoding employs a 240 k‑word dictionary and an internal conversational trigram language model.
Evaluation
Six real meetings were recorded in various rooms, each lasting 30–60 minutes, with both headset and array recordings. Professional transcribers produced reference transcripts, allowing both overlapped and non‑overlapped segments to be evaluated. The average overlap rate was 14.7 %—about twice that of the AMI corpus—making the test set particularly challenging. Compared with a state‑of‑the‑art neural mask‑based beamformer, the unmixing‑transducer system achieved a 10.8 % relative reduction in word error rate (WER) overall, with substantially larger gains on overlapped portions. When the estimated directions of arrival (DOA) for the two speech masks differed by less than 15°, the system merged the masks, effectively handling single‑speaker regions.
Contributions and impact
- Introduction of a fixed‑output “unmixing transducer” that cleanly separates utterances without explicit speaker counting.
- Use of windowed BLSTM with PIT and a robust stitching algorithm to maintain utterance continuity across long recordings.
- Development of the SSN model for more accurate interference covariance estimation, improving MVDR beamforming for ASR.
- Demonstration on real‑world meeting data with high overlap, showing significant WER improvements over the best existing neural beamforming baseline.
Future directions include scaling the number of output channels to handle more than two simultaneous speakers, reducing latency through lighter‑weight models, and adapting the approach to non‑circular or ad‑hoc microphone arrays (e.g., smartphones, laptops). The work paves the way for practical, high‑accuracy transcription of meetings, remote collaborations, and other multi‑speaker scenarios where overlapped speech has previously been a major bottleneck.
Comments & Academic Discussion
Loading comments...
Leave a Comment