Domain Robust Feature Extraction for Rapid Low Resource ASR Development
Developing a practical speech recognizer for a low resource language is challenging, not only because of the (potentially unknown) properties of the language, but also because test data may not be from the same domain as the available training data. …
Authors: Siddharth Dalmia, Xinjian Li, Florian Metze
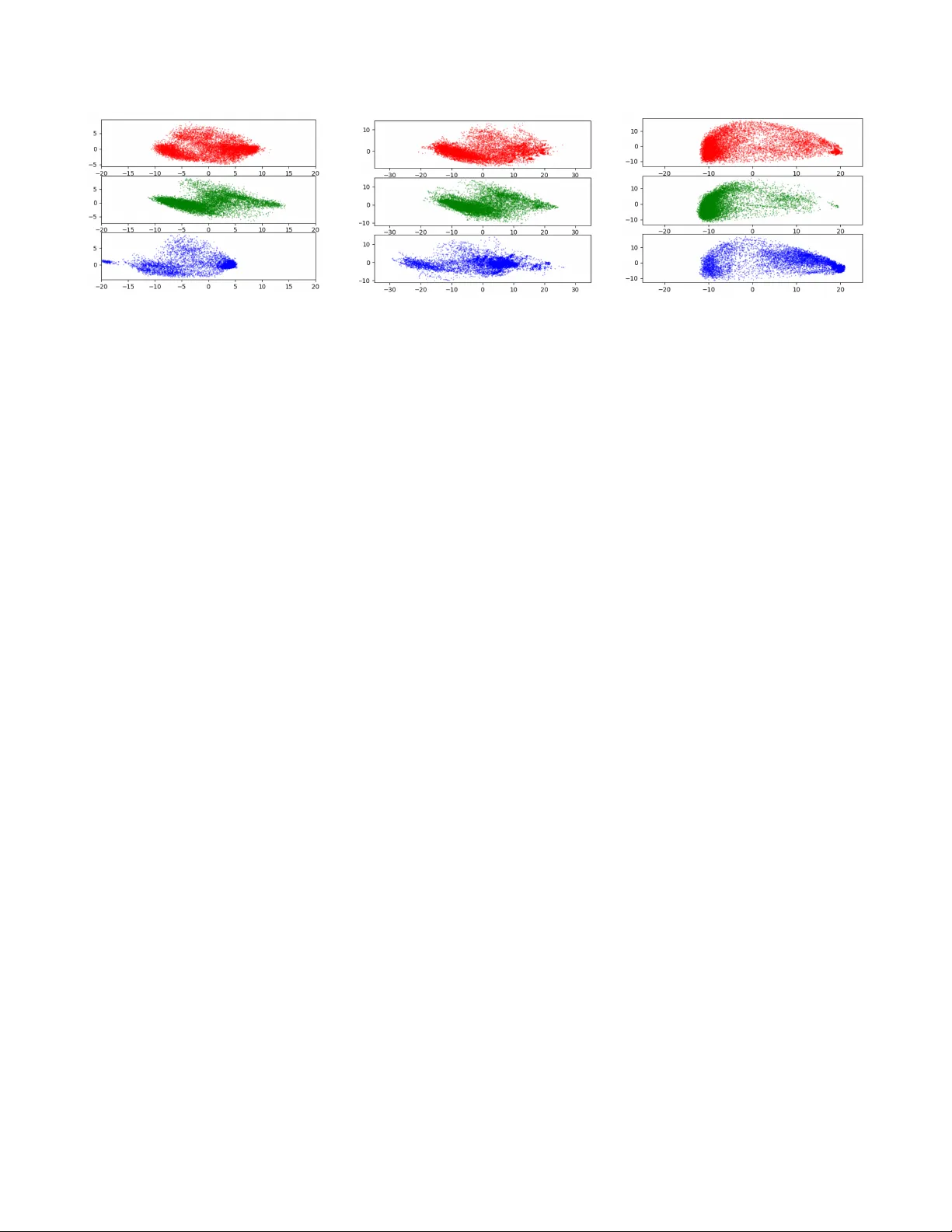
DOMAIN R OBUST FEA TURE EXTRA CTION FOR RAPID LO W RESOURCE ASR DEVELOPMENT Siddharth Dalmia ∗ , Xinjian Li ∗ , Florian Metze and Alan W . Black Language T echnologies Institute, Carne gie Mellon Uni versity; Pittsb urgh, P A; U.S.A. { sdalmia|xinjianl|fmetze|awb } @cs.cmu.edu ABSTRA CT Dev eloping a practical speech recognizer for a low re- source language is challenging, not only because of the (po- tentially unknown) properties of the language, but also be- cause test data may not be from the same domain as the av ail- able training data. In this paper , we focus on the latter challenge, i.e. domain mismatch, for systems trained using a sequence-based crite- rion. W e demonstrate the effecti veness of using a pre-trained English recognizer, which is robust to such mismatched con- ditions, as a domain normalizing feature extractor on a lo w resource language. In our example, we use T urkish Con ver - sational Speech and Broadcast News data. This enables rapid dev elopment of speech recognizers for new languages which can easily adapt to any domain. T est- ing in v arious cross-domain scenarios, we achie ve relati ve im- prov ements of around 25 % in phoneme error rate, with im- prov ements being around 50 % for some domains. Index T erms : domain mismatch, rapid prototyping, cross- lingual adaptation, robust speech recognition, lo w-resource ASR, CTC loss. 1. INTRODUCTION There is usually a lack of in-domain training data for lo w re- source languages, b ut it is often easier to collect audio data from a dif ferent domain for training for eg. using scripted speech (religious audio books), broadcast news or conv er- sation speech. This data may often not match the required domain of the original test data. Such out-of-domain audio might have different speaking styles, channels, background noise etc. Deep Neural Networks (DNN) based speech recog- nizers can be quite sensiti ve to such data mismatches and can fail completely when tested on unseen data. Data Augmentation has been found to be quite useful in these cases [1]. This technique can be used to produce vari- ations of training data that match the acoustic conditions of the e valuation data. Recently , the authors in [2] built a robust model aimed at performing well in mismatched data condi- tions. They employed various techniques like data augmen- ∗ Equal Contribution tation, time delay neural networks and i-v ectors to deal with late rev erberations, unseen channels and speaker v ariability . Howe ver , for scenarios like DARP A ’ s LORELEI project [3], which require rapid de velopment of ASR systems on lo w resource languages, these post-processing steps are a dis- pensable overhead, and there is instead a need for domain- normalizing features which can be extracted in advance and used cross-lingually or multi-lingually depending on the amount of data av ailable in the language provided. In this paper , we take an English ASR model which has been trained to perform well in v arious re verberation settings for multiple different domains of speech and use it to ex- tract “domain in variant” features for training models in T urk- ish. W e demonstrate that this cross-lingual transfer of features makes the model robust tow ards speaking style and channel variability by showing significant improvement in the ASR performance for cross-domain e xperiments, i.e., Broadcast News to Scripted Speech, Con versational Speech to Broad- cast News. Interestingly , we also see considerable improve- ments for in-domain experiments, i.e., within Broadcast News and Con versational Speech, indicating higher quality features than filter banks and the feasibility of a future “domain in vari- ant” feature extractor . W e focus on techniques that can be pre-computed and be adapted to a new language rapidly . The techniques that we discuss ensure that there is minimum language-dependent en- gineering or domain expertise needed to de velop the speech recognizer . W e begin by discussing various research direc- tions that have been explored in the fields of robustness in ASR and lo w resource ASR dev elopment, and ho w our w ork compares with the existing research. W e establish a baseline, explain the datasets used and outline the different domain mismatch scenarios that we explored. This is followed by qualitativ e visualization to explain the working of the domain normalizing features. W e provide a detailed discussion on the performance of the acoustic model on various mismat ch con- ditions, along with some diagnostic experiments. Published in the 2018 IEEE W orkshop on Spoken Language T echnology (SL T 2018), Athens, Greece c IEEE 2018 2. RELA TED WORK AND D A T ASETS 2.1. Related W ork Applying DNN-based speech recognition models on domain mismatched data has been one of the major problems in the speech recognition community . Sev eral challenges including CHiME [4], ASpIRE [5] and REVERB [6] have been pro- posed to facilitate creation of robust speech recognition sys- tems under v arious acoustic en vironments. A lar ge number of techniques ha ve been proposed to overcome this issue, which can be lar gely classified into 3 categories: robust feature ex- traction, data augmentation and unsupervised domain adapta- tion. Robust F eature Extraction: While most speech recognition systems depend on filterbank or MFCCs as input features, it was demonstrated that using robust features could improve accuracy over unseen en vironment [7]. Some examples of such robust features are gammatone wa velet cepstral coef fi- cients (GWCC) [8], normalized amplitude modulation fea- ture [9] and damped oscillator cepstral coefficient [10]. In addition to applying each rob ust feature separately , fus- ing those robust features after encoding each using different CNNs was sho wn to improve performance significantly [7]. Another line of work has shown that extracting bottleneck features can be useful to increase recognition accuracy by us- ing either denoising autoencoder [11] or RBM [12]. Data A ugmentation: Data augmentation is an alternati ve way for improving the robustness of speech recognition. Augmenting data by dif ferent approaches enables the model to be prepared for unseen audio en vironments. There are var - ious strategies to perform data augmentation. For instance, one study reported that augmenting the audio with different speed f actors can be helpful for the model [1]. Adding noise or reverberation was also shown to make recognition more robust [13, 14]. Unsupervised Domain Adaptation: In addition, there has been work on unsupervised methods for adapting the neu- ral network model to the test data acoustics. The authors in [15, 16] adapt their acoustic model to test data by learn- ing an adaptation function between the hidden unit contribu- tions of the training data and the development data. Howe ver , as pointed by [17], these methods require reliable tri-phone alignment and this may not always be successful in a mis- matched condition. Recently , there has been a lot of work [17, 18, 19] using adversarial training to adapt to the target domain data in a completely unsupervised way . The authors in [18] and [19] use a gradient rev ersal layer to train a domain classifier and try to learn domain in variant representations by passing a ne g- ativ e gradient on classification of domains. The use of Do- main Seperation Networks [17] has also shown significant improv ements by having two separate networks: a domain in v ariant network and a network that is unique to the domain. Although there has been a lot of relev ant work tow ards ro- bustness to mismatched conditions, there has been very little work that shows its working on models trained using a se- quence based criterion. Further , techniques like unsupervised domain adaptation and data augmentation either require in- formation about the testing conditions or require presence of some test-domain data for adaptation. This makes these ap- proaches expensiv e in terms of both time and expertise re- quired, making them irrelev ant for our use case. Thus, we hav e not compared our work to these approaches in our ex- periments. Rapid Development of ASR: There have been a lot of projects that need rapid adaptation and dev elopment of ASR systems with little to no data [20, 21, 22]. There has been works that show that using the features from the bottleneck layer of a large multilingual model [23, 24, 25, 26] or trans- ferring weights from a pre-trained ASR [27, 28, 29, 30] can improv e recognition and con vergence of ASR in low resource languages. Capturing speaker and en vironment information in the form of i-vectors [31] has been shown to be useful for adaptation of neural networks [22, 32]. Howe ver , most of these methods are trained using con ventional HMM/DNN systems which requires careful crafting of context dependent phonemes and can be time consuming and expensi ve. Recently , [33, 34] studied these behaviours in sequence based models. Authors in [34] sho wed ho w phonological fea- tures can be exploited to hav e faster dev elopment of ASR. Authors in [33] showed that in a multi-lingual setting, it is beneficial to just train on large amounts of well-prepared data in any language. They also showed that including different languages introduced the model to v arious acoustic properties which helped the model generate better language-in variant features, thereby improving the cross-lingual performance. Although most of this prior work looked at cross-lingual aspects of dev elopment of lo w resource ASR, the issue of do- main mismatch between training and testing data has not been addressed. In this paper we look at how we can build se- quence based ASR models for lo w resource languages where there is a domain mismatch in the data which is a vailable for adaptation to the language. 2.2. Datasets W e use three datasets for this work: T urkish Con versational dataset ( Con versational Speech ), T urkish Scripted dataset ( Scripted Speech ) and T urkish Broadcast Ne ws dataset ( Broad- cast News ). T urkish Con versational dataset and Scripted dataset are part of the Babel corpus provided by the IARP A Babel Pro- gram (IARP A Babel T urkish Full Language P ack IARP A- babel105b-v0.5). This contains telephone con versation speech recorded at 8khz. T o b uild Con versational Speech systems, we use the standard Full Language Pack provided along-with the dataset (around 80 hours of training data). The dataset also comes with Scripted Speech audio which is 2 recorded by providing prompt sheets to speakers, and asking them to read some text or answer a short question. Since the T urkish Scripted Dataset is small and mismatched to the other corpora, we use it for testing only . While testing our models, we do not score on human noises and silences to allow cross-domain testing of the models. The Broadcast Ne ws corpus (LDC2012S06, LDC2012T21) has approximately 130 hours audio from V oice of America (V O A) in T urkish. The data is sampled with 16kHz origi- nally , and it was down-sampled to 8kHz for our e xperiments. About 5 % of the data is randomly selected as the test set. This data is a public subset of the data used in [35], so the results are not directly comparable. 3. PIPELINE W e use CTC-based Sequence Models decoded with WFSTs to train our ASR systems, as detailed in [36]. The target labels are generated using a common grapheme-to-phoneme (G2P) library [37] that we use to maintain uniformity of phonemes across datasets, allowing us to do cross-domain experiments. W e start this section by briefly explaining the baseline setup and the G2P library , followed by the explana- tion of the ASpIRE Chain Models [2] (b uilt for the ASpIRE challenge) along with its adv antages and how we use it to extract domain inv ariant features to train our CTC-based models. 3.1. Baseline Featur es and Epitran G2P Library Baseline Input Features : For the baseline experiments we use the basic features used in EESEN [36], 40 dimensional fil- terbank features along with their first and second order deriv a- tiv es and 3 pitch features. W e also apply mean and variance normalization to the features for each speaker . Model Structure : As done in [33] we use a 6 layer Bi-LSTM model with 360 cells in each direction with a window of size 3. Each utterance is sub-sampled with a stride of 2 frames to make 3 equiv alent copies of the same utterance. They are trained using the CTC loss function described in [36]. T arget Labels : T o maintain uniformity of the target la- bels across all the T urkish datasets, we use the Epitran [37] grapheme-to-phoneme library to generate lexicons for the words present in the training, dev elopment and test set. T o verify that the lexicons generated by the Epitran system are reasonable, we compute WER on each of the datasets. A WFST based decoding was performed using a language model that was built on the training data (lowest perplexity language models was chosen between 3-gram and 4-gram models) and acoustic model output was scaled with the pri- ors of the phonemes in the training data. T able 1 sho ws the Phoneme error rates (PER) and the corresponding W ord er- ror rates (WER) on baseline models built on Turkish Babel Dataset and T urkish Broadcast news data. T able 1 . Phoneme (% PER) and W ord error rate (% WER) of baseline systems trained on T urkish Broadcast News and Con versational Datasets using the Epitran Phoneme Set. Model PER WER Con versational Speech 34.5 49.6 Broadcast News 5.8 20.2 Going forward, we will analyze the trends in phoneme error rate, which is a good measure of the success of the acoustic-only adaptation performed in this paper . This would also a void any kind of re-scoring of phoneme sequences done using the language model. 3.2. ASpIRE Chain Model Originally dev eloped in response to the IARP A ASpIRE chal- lenge [5], and trained on augmented English Fisher data [2] using a TDNN architecture [38], the ASpIRE model 1 is ro- bust against various acoustic environments, including noisy and rev erberant domains. Proposed Input Featur es : Since the ASpIRE model is sup- posed to do well in mismatched conditions, follo wing the ideas from [33], we want to use the internal features of the English trained ASpIRE chain model to rapidly dev elop a T urkish CTC based ASR and test for its robustness, which has been explained in detail in the follo wing section. W e use the same model structure as the baseline model, except, we keep a windo w of size 1 to decrease the training time of the model. Further , the effect of the window size on the result is less prominent when using the domain robust fea- ture extraction technique discussed belo w . 4. DOMAIN ROB UST FEA TURE EXTRA CTION As the previous section suggests, the ASpIRE chain model is robust to noisy and rev erberant en vironments. W e expect that features from the pre-trained ASpIRE model can be helpful when testing on unseen domains even under a cross-lingual settings. T o extract the ASpIRE feature from the TDNN layers, we first prepare the input features into a pre-trained ASpIRE model. 40-dimensional Mel-frequency cepstral coefficients (MFCCs) are used as the main input features to the ASpIRE model. Then 100-dimensional i-vector is appended to each frame, which can capture information of both speaker and en- vironment. The TDNN architecture used in the ASpIRE chain model is a 5 layer sub-sampled TDNN netw ork. TDNN0 layer is di- rectly connected to the input layer which splices frames from t − 1 to t + 1 for time step t . W e write {− 1 , 0 , 1 } as the 1 The pre-trained model is av ailable at dl.kaldi- asr.org/ models/0001_aspire_chain_model.tar.gz 3 (a) Baseline Input Features (b) Input to ASpIRE Model (c) Output of TDNN3 layer Fig. 1 . This figure sho ws the distribution of the various input features across dif ferent datasets. The one on the left are the filterbank + pitch features with CMVN used in the baseline e xperiments, figure in center shows the features that are used as the input to the ASpIRE model (MFCC and i-vector), the right side plots are the domain in variant output of the TDNN3 layer from the ASpIRE model. The red poi nts are Con versational Speech , the green ones are Broadcast Ne ws and the blue points are from Scripted Speech . W e can see that the features become normalized across domains after passing through the ASpIRE model. T o visualize this in a 2D space 10000 frames were randomly selected from each of the three datasets and reduced to 2 dimension using Principle Component Analysis (PCA). context window for this layer . The TDNN1 layer uses one more future frame, and its context window is {− 1 , 0 , 1 , 2 } . The subsequent three TDNN layers (TDNN2, 3, 4) share the same context window {− 3 , 0 , 3 } . Finally , the last TDNN layer (TDNN5) uses {− 6 , − 3 , 0 } . In total, each frame after TDNN5 layer has 17 frames as its left conte xt and 12 frames as the right context. In our experiments, we explore acti vations of TDNN3 layer as we observed that it achie ved the best WER when compared to the other layers in the cross-lingual adaptation setting. W e believe this could be possible because shallow layers such as TDNN1 or TDNN2 might not have learned informativ e acoustic features that are independent of the in- put domain. On the other hand, the later layers could be too adapted to the target language and the target domain condi- tion and thus not suitable for cross-lingual and domain mis- match scenarios. For example TDNN5 layer has a conte xt of {− 6 , − 3 , 0 } which was added to handle re verberations [38]. T o in vestigate robustness of the TDNN3 acti vations, in Figure 1, we visualize its distribution on v arious domains of T urkish datasets that we have and compare it qualitati vely with the baseline input features. W e also visualize the input to the ASpIRE chain model and show ho w by the 3rd TDNN layer the model learns to normalize the domain mismatch. The TDNN3 layer acti vations ha ve v ery similar distribu- tions for the three corpus which motiv ates us to wards using it as a robust “domain in variant” feature e xtractor . 5. RESUL TS AND DISCUSSIONS 5.1. Proposed A pproach W e inv estigate the performance of the domain rob ust ASpIRE features in a model of windo w size 1 and compare them with systems trained using baseline input features (filter banks). W e train separate models on both Con versational Speech and Broadcast Ne ws and ev aluate them using the other 2 datasets, along with Scripted Speech . This ev aluation helps us under - stand the rob ustness of our model and its ability to recognize speech of unseen en vironments. Our results are summarized in T able 2. The table shows phoneme error rate (PER) of various train/test combina- tions. Here, for example, the upper-right number, 40.1 % denotes the PER when the model is trained with Con versa- tional Speech and ev aluated with Scripted Speech . W e can see that these features help in both in-domain and out-of-domain setting. W e see a relati ve improv ement 15.5% for Broadcast Ne ws and 5.5% for Con versational Speech when testing on the same dataset. This corroborates the in- domain adaptation improvements sho wn in [33], and we thus believ e that a well trained ASpIRE model is a good starting point for adaptation. As expected, the gains on cross-domain experiments are much larger and more significant. W e see a relati ve im- prov ement of 29.0% PER when testing a Con versational Speech Model on Broadcast News and a relati ve 47.8% PER improvement when testing a Broadcast News system on Scripted Speech . Other cross-domain systems also show improv ements of around 15% relative. These results show strong indication that using these ASpIRE activ ations cross- lingually can generalize well to adapt a new low resource language in different domains. 5.2. Diagnostic Experiments T o understand the gains that come from the cross-lingual transfer , we performed an experiment by using data aug- mentation and i-vector components (key-f actors towards 4 T able 2 . Phoneme Error Rates (% PER) using different datasets. T wo features are ev aluated here: CMVN filterbank + pitch with window size 3 and cross-lingual ASpIRE features from the TDNN3 layer . Each model is trained with either con versational speech or broadcast news, and then tested using all three datasets to sho w their ability of adapt to a new en vironment. The colored corpus in the first row denotes the test dataset, and the second column is the training dataset. Model Con versational Broadcast Scripted Speech News Speech Baseline Con versational Speech 34.5 34.8 40.1 CMVN FBank + Pitch W in-3 Broadcast News 60.8 5.8 67.1 Domain Robust Con versational Speech 32.6 24.7 33.2 ASPIRE TDNN3 layer Broadcast News 53.4 4.9 35.0 robustness as mentioned in [2]), and applying them to our baseline model. The results are sho wn in in T able 3 (notable improv ements in bold). 5.2.1. Data Augmentation For this experiment we follo w the data augmentation pro- cedure in [2] by creating multi-condition training data by using a collection of 7 datasets, (R WCP [39], AIRD [40], Re- verb2014 [41], OpenAIR [42], MARD Y [43], QMUL [44], Impulse responses from V arechoic chamber [45]), to get dif- ferent real world room impulse responses (RIR) and noise recordings. Three different copies of the original dataset were created with a randomly chosen room impulse response. Noise was added when av ailable with randomly chosen SNR value between 0, 5, 10, 15 and 20 dB. The 3 copies along with the original copy was used to train a model with baseline filterbank features with a windo w size of 3. As per the results in T able 3, we note that the Broadcast News system tested on Scripted Speech improv es by 15% relati ve PER w .r .t. to baseline system shown in T able 2. Other cross-domain sys- tems don’ t sho w any notable improv ements. W e belie ve that this may be because data augmentation is meant to simu- late the testing conditions and we did not use any such prior information while creating the augmentations. T able 3 . Phoneme Error Rates (% PER) on Baseline (CMVN filterbank+pitch) features with window size of 3 using data augmentation and i-vectors. Model Con v . Broad. Scripted Speech News Speech Data Con v . Speech 35.8 37.2 41.5 Aug. Broad. News 60.0 6.1 56.9 i-vec. Con v . Speech 34.1 34.3 40.2 Broad. News 61.0 5.7 78.7 5.2.2. i-vectors For this experiment, we use the same background model as that of the pre-trained ASpIRE model to extract i-vectors for each sub-speaker (6000 frames of a single speaker is called a subspeaker) in the dataset, as getting reliable background model and training a good i-vector can be difficult for “real” low-resource languages. As per the results in T able 3, we see that i-vectors did not see any notable improvements in performance. Ho wev er , it had a big drop when testing the Broadcast News system on Scripted Speech . W e think that this maybe be because of using ASpIRE background model to extract i-vectors and it maybe a better idea to train them from scratch. The diagnostics sho w that techniques like data augmenta- tion and i-vectors need to be prepared carefully and require a lot of tuning in the development data before it actually be- comes helpful. Therefore for scenarios like LORELEI, where rapid prototyping is needed, this maybe to difficult to tune. 5.3. Decoding using a matched Language Model - LORELEI Simulation The described approach responds to the requirements of the D ARP A LORELEI (Low Resource Languages for Emer gent Incidents) program. Using the robust feature extractor , it is possible to rapidly develop a speech recognition system in an “incident’ language, ev en if there is significant channel mis-match between av ailable training data and the test data. In past NISTs LoReHL T e valuations, 2 we found that for prac- tical systems, channel and domain mis-match is a significant problem, which is ignored by existing cross- and multi- lingual training work. F or the 2018 LoReHL T e valuation, the authors built two speech recognizers (for Kinyarwanda and Sinhala) within about 24 hours, using “av ailable’ and minimal (or modest) data resources. A description of these systems will be submitted to a later conference, as soon as analysis of the evaluation results has concluded. On our internal test set, we found that the robust feature extractor described in 2 https://www .nist.gov/itl/iad/mig/lorehlt-ev aluations 5 this paper was similarly effecti ve for the two LoReHL T 2018 languages (where only clean training and dev elopment data from fe w speakers was a vailable, while the test data consists of broadcast material), as for T urkish. T able 4 . W ord Error Rates (% WER) on Broadcast Ne ws data for different Con versational Speech models Con v . Speech Broadcast News WER (%) Baseline feats 50.4 ASpIRE TDNN3 feats 34.7 T o get an estimate of the overall improvement in the word error rate, we can simulate a LORELEI-like scenario by usi ng our Conv ersational Speech model to decode Broadcast News with an in-domain language model. T able 4 shows that the WER goes down considerably (30% relativ e improvement) after using the domain robust ASpIRE TDNN3 layer features. 6. CONCLUSIONS In this paper , we present a simple yet effecti ve approach to improv e domain robustness in low-resource, cross-lingual ASR. Our target phoneme error rate on T urkish Broadcast News data improved by 10 % absolute (almost 30 % relati ve) by porting a robust feature extractor from a well-resourced source language to the target language, and training on mis- matched (Babel FLP) data. With a target-domain language model, w ord error rate impro ves similarly by about 15 % ab- solute (30 % relativ e). Large impro vements are also observed for the recognition of scripted speech, independent of training material. The feature extractor does not depend on the target language, so the approach is suitable for rapid prototyping and bootstrapping; we believ e it will be ev en more beneficial for ev en smaller training corpora (Babel LLP , VLLP). 7. A CKNO WLEDGEMENTS This project was sponsored by the Defense Advanced Re- search Projects Agency (D ARP A) Information Innovation Of- fice (I2O), program: Low Resource Languages for Emer gent Incidents (LORELEI), issued by D ARP A/I2O under Contract No. HR0011-15-C-0114. W e gratefully acknowledge the support of NVIDIA Cor - poration with the donation of the T itan X Pascal GPU used for this research. The authors would like to thank Anant Sub- ramanian, Soumya W adhwa and Shiv ani Poddar for sharing their insights. The authors would also like to thank Murat Saraclar and Ebru Arisoy for their help in establishing the T urkish BN baselines. 8. REFERENCES [1] T om K o, V ijayaditya Peddinti, Daniel Povey , and San- jeev Khudanpur, “ Audio augmentation for speech recog- nition, ” in Sixteenth Annual Confer ence of the Interna- tional Speech Communication Association , 2015. [2] V ijayaditya Peddinti, Guoguo Chen, V imal Manohar , T om K o, Daniel Pove y , and Sanjee v Khudanpur , “JHU aspire system: Robust L VSCR with TDNNs, i vector adaptation and RNN-LMs, ” in Automatic Speech Recog- nition and Understanding (ASR U), 2015 IEEE W ork- shop on . IEEE, 2015, pp. 539–546. [3] “Low Resource Languages for Emergent In- cidents (LORELEI), howpublished= https: //www.darpa.mil/program/low- resource- languages- for- emergent- incidents , ” . [4] Jon Barker , Ricard Marxer , Emmanuel V incent, and Shinji W atanabe, “The third CHiMEspeech separation and recognition challenge: Dataset, task and baselines, ” in Automatic Speech Recognition and Understanding (ASR U), 2015 IEEE W orkshop on . IEEE, 2015, pp. 504– 511. [5] Mary Harper, “The automatic speech recogition in re- verberant environments (ASpIRE) challenge, ” in A uto- matic Speech Recognition and Understanding (ASR U), 2015 IEEE W orkshop on . IEEE, 2015, pp. 547–554. [6] Keisuk e Kinoshita, Marc Delcroix, Sharon Gannot, Emanu ¨ el AP Habets, Reinhold Haeb-Umbach, W al- ter Kellermann, V olker Leutnant, Roland Maas, T omo- hiro Nakatani, Bhiksha Raj, et al., “ A summary of the REVERB challenge: state-of-the-art and remaining challenges in reverberant speech processing research, ” EURASIP Journal on Advances in Signal Processing , vol. 2016, no. 1, pp. 7, 2016. [7] V ikramjit Mitra and Horacio Franco, “Coping with un- seen data conditions: In vestigating neural net architec- tures, robust features, and information fusion for ro- bust speech recognition., ” in INTERSPEECH , 2016, pp. 3783–3787. [8] Aniruddha Adiga, Mathew Magimai, and Chan- dra Sekhar Seelamantula, “Gammatone wav elet cepstral coefficients for rob ust speech recognition, ” in TENCON 2013-2013 IEEE Re gion 10 Confer ence (31194) . IEEE, 2013, pp. 1–4. [9] V ikramjit Mitra, Horacio Franco, Martin Graciarena, and Arindam Mandal, “Normalized amplitude modu- lation features for lar ge v ocabulary noise-rob ust speech recognition, ” in Acoustics, Speech and Signal Pr ocess- ing (ICASSP), 2012 IEEE International Confer ence on . IEEE, 2012, pp. 4117–4120. 6 [10] V ikramjit Mitra, Horacio Franco, and Martin Gracia- rena, “Damped oscillator cepstral coef ficients for robust speech recognition., ” in Interspeec h , 2013, pp. 886–890. [11] Jonas Gehring, Y ajie Miao, Florian Metze, and Alex W aibel, “Extracting deep bottleneck features using stacked auto-encoders, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE International Confer- ence on . IEEE, 2013, pp. 3377–3381. [12] Dong Y u and Michael L Seltzer , “Improv ed bottle- neck features using pretrained deep neural networks, ” in T welfth Annual Confer ence of the International Speech Communication Association , 2011. [13] Martin Karafi ´ at, Franti ˇ sek Gr ´ ezl, Luk ´ a ˇ s Burget, Igor Sz ¨ oke, and Jan ˇ Cernock ` y, “Three ways to adapt a CTS recognizer to unseen rev erberated speech in BUT sys- tem for the ASpIRE challenge, ” in Sixteenth Annual Confer ence of the International Speech Communication Association , 2015. [14] Roger Hsiao, Jeff Ma, W illiam Hartmann, Martin Karafi ´ at, Franti ˇ sek Gr ´ ezl, Luk ´ a ˇ s Burget, Igor Sz ¨ oke, Jan Honza ˇ Cernock ` y, Shinji W atanabe, Zhuo Chen, et al., “Robust speech recognition in unkno wn rev erber- ant and noisy conditions, ” in Automatic Speech Recogni- tion and Understanding (ASR U), 2015 IEEE W orkshop on . IEEE, 2015, pp. 533–538. [15] Pa wel Swietojanski and Stev e Renals, “Learning hidden unit contributions for unsupervised speaker adaptation of neural network acoustic models, ” in Spoken Lan- guage T echnology W orkshop (SLT), 2014 IEEE . IEEE, 2014, pp. 171–176. [16] Pa wel Swietojanski and Stev e Renals, “Dif ferentiable pooling for unsupervised speaker adaptation, ” in Acous- tics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on . IEEE, 2015, pp. 4305–4309. [17] Zhong Meng, Zhuo Chen, V adim Mazalov , Jinyu Li, and Y ifan Gong, “Unsupervised adaptation with do- main separation networks for robust speech recogni- tion, ” arXiv pr eprint arXiv:1711.08010 , 2017. [18] Sining Sun, Binbin Zhang, Lei Xie, and Y anning Zhang, “ An unsupervised deep domain adaptation approach for robust speech recognition, ” Neur ocomputing , vol. 257, pp. 79–87, 2017. [19] Y usuke Shinohara, “ Adversarial multi-task learning of deep neural networks for robust speech recognition., ” Pr oc. Interspeech 2016 , 2016. [20] T anja Schultz and Ale x W aibel, “Fast bootstrapping of L VCSR systems with multilingual phoneme sets, ” in F ifth Eur opean Conference on Speech Communication and T echnology , 1997. [21] Florian Metze, Ankur Gandhe, Y ajie Miao, Zaid Sheikh, Y un W ang, Di Xu, Hao Zhang, Jungsuk Kim, Ian Lane, W on K yum Lee, et al., “Semi-supervised training in low-resource ASR and KWS, ” in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Confer ence on . IEEE, 2015, pp. 4699–4703. [22] Shaofei Xue, Ossama Abdel-Hamid, Hui Jiang, Lirong Dai, and Qingfeng Liu, “Fast adaptation of deep neural network based on discriminant codes for speech recog- nition, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 22, no. 12, pp. 1713–1725, 2014. [23] Ngoc Thang V u, Florian Metze, and T anja Schultz, “Multilingual bottle-neck features and its application for under-resourced languages, ” in Spoken Language T ech- nologies for Under -Resour ced Languages , 2012. [24] Samuel Thomas, Sriram Ganapathy , and Hynek Her - mansky , “Multilingual MLP features for low-resource L VCSR systems, ” in Acoustics, Speech and Signal Pr o- cessing (ICASSP), 2012 IEEE International Confer ence on . IEEE, 2012, pp. 4269–4272. [25] Kate M Knill, Mark JF Gales, Shakti P Rath, Philip C W oodland, Chao Zhang, and S-X Zhang, “Inv estigation of multilingual deep neural networks for spoken term detection, ” in Automatic Speech Recognition and Un- derstanding (ASR U), 2013 IEEE W orkshop on . IEEE, 2013, pp. 138–143. [26] Frantisek Gr ´ ezl, Martin Karafi ´ at, and Karel V esely , “ Adaptation of multilingual stacked bottle-neck neural network structure for new language, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE In- ternational Conference on . IEEE, 2014, pp. 7654–7658. [27] Y ajie Miao, Hao Zhang, and Florian Metze, “Dis- tributed learning of multilingual DNN feature extractors using GPUs, ” in Fifteenth Annual Confer ence of the In- ternational Speech Communication Association , 2014. [28] Jui-T ing Huang, Jinyu Li, Dong Y u, Li Deng, and Y ifan Gong, “Cross-language knowledge transfer using multi- lingual deep neural network with shared hidden layers, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE International Confer ence on . IEEE, 2013, pp. 7304–7308. [29] Arnab Ghoshal, Pawel Swietojanski, and Steve Re- nals, “Multilingual training of deep neural networks, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE International Confer ence on . IEEE, 2013, pp. 7319–7323. 7 [30] Andreas Stolck e, Frantisek Grezl, Mei-Y uh Hwang, Xin Lei, Nelson Morg an, and Dimitra V ergyri, “Cross- domain and cross-language portability of acoustic fea- tures estimated by multilayer perceptrons, ” in Acous- tics, Speech and Signal Pr ocessing, 2006. ICASSP 2006 Pr oceedings. 2006 IEEE International Confer ence on . IEEE, 2006, vol. 1, pp. I–I. [31] Najim Dehak, Patrick J Kenny , R ´ eda Dehak, Pierre Du- mouchel, and Pierre Ouellet, “Front-end factor analysis for speaker v erification, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 19, no. 4, pp. 788–798, 2011. [32] Y ajie Miao, Hao Zhang, and Florian Metze, “Speaker adaptiv e training of deep neural network acoustic mod- els using i-vectors, ” IEEE/ACM T ransactions on A udio, Speech and Langua ge Pr ocessing (T ASLP) , v ol. 23, no. 11, pp. 1938–1949, 2015. [33] Siddharth Dalmia, Ramon Sanabria, Florian Metze, and Alan W Black, “Sequence-based multi-lingual low re- source speech recognition, ” in 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 4909–4913. [34] Sibo T ong, Philip N Garner , and Herv ´ e Bourlard, “F ast language adaptation using phonological information, ” Pr oc. Interspeech 2018 , pp. 2459–2463, 2018. [35] Ebru Arisoy , Dogan Can, Siddika Parlak, Hasim Sak, and Murat Sarac ¸ lar , “T urkish broadcast ne ws tran- scription and retriev al, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 17, no. 5, pp. 874–883, 2009. [36] Y ajie Miao, Mohammad Go wayyed, and Florian Metze, “EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding, ” in A utomatic Speech Recognition and Understanding (ASRU), 2015 IEEE W orkshop on . IEEE, 2015, pp. 167–174. [37] David R. Mortensen, Siddharth Dalmia, and P atrick Lit- tell, “Epitran: Precision G2P for many languages, ” in Pr oceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) , May 2018. [38] V ijayaditya Peddinti, Daniel Povey , and Sanjeev Khu- danpur , “ A time delay neural network architecture for efficient modeling of long temporal contexts, ” in Six- teenth Annual Confer ence of the International Speech Communication Association , 2015. [39] Satoshi Nakamura, Kazuo Hiyane, Futoshi Asano, T akanobu Nishiura, and T akeshi Y amada, “ Acoustical sound database in real en vironments for sound scene understanding and hands-free speech recognition., ” in LREC , 2000. [40] Marco Jeub, Magnus Schafer , and Peter V ary , “ A bin- aural room impulse response database for the ev aluation of derev erberation algorithms, ” in Digital Signal Pr o- cessing, 2009 16th International Confer ence on . IEEE, 2009, pp. 1–5. [41] Keisuk e Kinoshita, Marc Delcroix, T akuya Y oshioka, T omohiro Nakatani, Armin Sehr , W alter K ellermann, and Roland Maas, “The REVERB challenge: A common e valuation frame work for derev erberation and recognition of rev erberant speech, ” in Applications of Signal Pr ocessing to Audio and Acoustics (W ASP AA), 2013 IEEE W orkshop on . IEEE, 2013, pp. 1–4. [42] Damian T Murphy and Simon Shelley , “Openair: An interactiv e auralization web resource and database, ” in Audio Engineering Society Con vention 129 . Audio En- gineering Society , 2010. [43] Jimi YC W en, Nikolay D Gaubitch, Emanuel AP Ha- bets, T ony Myatt, and Patrick A Naylor, “Ev aluation of speech derev erberation algorithms using the MARD Y database, ” in in Proc. Intl. W orkshop Acoust. Echo Noise Contr ol (IW AENC . Citeseer , 2006. [44] Dan Stowell and Mark D Plumble y , “ An open dataset for research on audio field recording archives: freefield1010, ” arXiv pr eprint arXiv:1309.5275 , 2013. [45] Simao Ferraz De Campos Neto, “The ITU-T software tool library , ” International journal of speech technology , vol. 2, no. 4, pp. 259–272, 1999. 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment