A model for system developers to measure the privacy risk of data
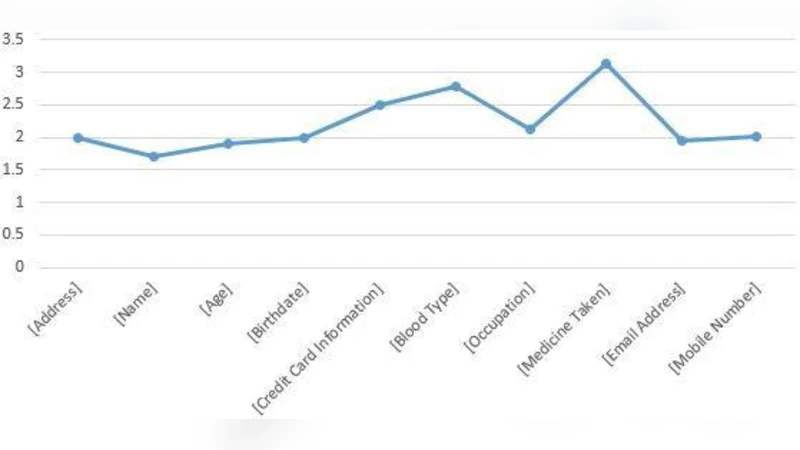
In this paper, we propose a model that could be used by system developers to measure the privacy risk perceived by users when they disclose data into software systems. We first derive a model to measure the perceived privacy risk based on existing knowledge and then we test our model through a survey with 151 participants. Our findings revealed that users’ perceived privacy risk monotonically increases with data sensitivity and visibility, and monotonically decreases with data relevance to the application. Furthermore, how visible data is in an application by default when the user discloses data had the highest impact on the perceived privacy risk. This model would enable developers to measure the users’ perceived privacy risk associated with data items, which would help them to understand how to treat different data within a system design.
💡 Research Summary
The paper addresses a gap in privacy engineering by proposing a quantitative model that enables system developers to estimate the privacy risk perceived by users when they disclose personal data to software applications. Drawing on established concepts from the privacy literature—data sensitivity, data visibility, and data relevance—the authors construct a three‑dimensional framework that translates these qualitative attributes into numeric scores. Sensitivity captures the intrinsic potential harm of a data item (e.g., identifiability, legal or financial consequences). Visibility reflects how prominently the data is displayed or shared by default within the user interface, encompassing UI design choices, logging practices, and third‑party transmission. Relevance measures the necessity of the data for the core functionality of the application, acknowledging that users are more willing to accept risk when the data is essential.
The model combines the three factors in a multiplicative‑divisive formula:
Perceived Privacy Risk (PPR) = α × Sensitivity × Visibility ÷ γ × Relevance
where α, β, and γ are empirically derived weights. To estimate these weights, the authors conducted an online survey with 151 participants drawn primarily from university and professional populations. Respondents evaluated twelve hypothetical data items (e.g., name, email, location, health records, financial information) on a 7‑point Likert scale for each of the three dimensions and for overall perceived risk. Demographic variables (age, gender, education, IT proficiency) and privacy‑related behaviors (frequency of reading privacy policies) were also collected to control for individual differences.
Statistical analysis employed multiple linear regression and structural equation modeling (SEM). The regression revealed that the visibility coefficient (β = 0.62, p < 0.001) had the strongest positive association with perceived risk, confirming the authors’ hypothesis that how openly data is presented to the user dominates risk perception. Sensitivity also contributed positively (α = 0.41, p < 0.01), while relevance exerted a mitigating effect (γ = ‑0.35, p < 0.05). The overall model explained 58 % of the variance in risk scores (R² = 0.58). SEM fit indices (CFI = 0.96, RMSEA = 0.04) indicated an excellent fit, supporting the theoretical structure.
The findings have direct implications for privacy‑by‑design practices. Since visibility is the most influential factor, developers can reduce perceived risk by default‑hiding sensitive fields, employing progressive disclosure, and minimizing unnecessary data exposure in UI elements. When data relevance is high, designers should transparently communicate why the data is needed, thereby aligning user expectations with system requirements. The model’s simplicity—requiring only three input scores—makes it readily integrable into design review checklists, risk assessment tools, or automated privacy impact analysis pipelines.
Nevertheless, the study has limitations. The use of hypothetical scenarios may not capture the complexity of real‑world data flows, where contextual cues, trust in the provider, and regulatory signals interact with the three core dimensions. The participant pool, skewed toward younger, tech‑savvy individuals, limits generalizability across age groups and cultures. Moreover, the visibility construct is tied to UI design choices that differ between platforms (mobile vs. desktop) and may evolve with emerging interaction paradigms such as voice assistants or augmented reality.
Future research directions include validating the model with actual usage logs from live applications, extending the factor set to incorporate trust, perceived control, and regulatory awareness, and testing cross‑cultural variations in the weighting of sensitivity, visibility, and relevance. Additionally, integrating the model into continuous privacy monitoring systems could enable dynamic risk scoring as user behavior and system configurations change over time.
In conclusion, the paper delivers a pragmatic, empirically grounded tool for quantifying user‑perceived privacy risk. By highlighting visibility as the dominant driver, it offers actionable guidance for developers seeking to balance functionality with privacy protection, thereby contributing to more trustworthy and user‑centric software design.
Comments & Academic Discussion
Loading comments...
Leave a Comment