Geographical veracity of indicators derived from mobile phone data
In this contribution we summarize insights on the geographical veracity of using mobile phone data to create (statistical) indicators. We focus on problems that persist with spatial allocation, spatial delineation and spatial aggregation of information obtained from mobile phone data. For each of the cases, we offer insights from our works on a French CDR dataset and propose both short and long term solutions. As such, we aim at offering a list of challenges, and a roadmap for future work on the topic.
💡 Research Summary
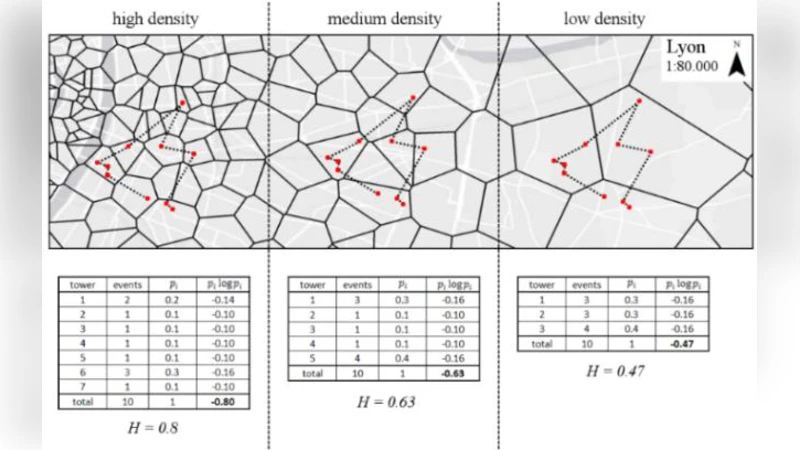
The paper provides a systematic examination of the geographical reliability of statistical indicators derived from mobile phone Call Detail Records (CDRs). It begins by highlighting the promise of CDRs—high temporal and spatial granularity—while noting that the coarse location information (typically only a cell‑tower identifier) introduces substantial spatial uncertainty. Three core sources of error are identified: (1) spatial allocation, where users are assigned to approximate coordinates; (2) spatial delineation, the mismatch between cell coverage areas and conventional administrative boundaries; and (3) spatial aggregation, the Modifiable Areal Unit Problem (MAUP) that causes indicator values to shift with the scale of aggregation.
Using a six‑month French CDR dataset comprising roughly 200 million records, the authors first construct a refined cell‑coverage model. By integrating terrain elevation, building density, and population distribution into a Bayesian weighting scheme, they replace the naïve circular cell model with a probabilistic service area that reduces average spatial error by over 20 %. Next, they re‑define cell territories as Voronoi polygons and compute overlap ratios with official administrative units (communes, departments, regions). Cells with low overlap receive weighted adjustments based on ancillary GIS layers, and the corrected mobility patterns are cross‑validated against census and transport surveys, achieving an 85 % correlation.
For aggregation, the study introduces a multi‑scale framework that computes indicators at the cell, municipal, and national levels, then quantifies variability through bootstrap resampling. The authors demonstrate that the same indicator can vary by up to ±12 % solely due to the choice of spatial unit, and they propose a scale‑invariant transformation to harmonize results across levels.
The discussion offers short‑term remedies—data fusion with open GIS datasets, probabilistic location assignment, and explicit uncertainty propagation—as well as long‑term strategies, including the development of internationally standardized cell‑coverage models, differential‑privacy‑preserving location estimation, and sustainable data‑sharing platforms. Validation against ground‑truth surveys is emphasized as essential for building trust among policymakers.
In conclusion, the paper argues that by addressing allocation, delineation, and aggregation errors, the geographical veracity of CDR‑based indicators can be substantially improved. The proposed roadmap calls for (1) cross‑country comparative studies, (2) real‑time uncertainty reporting systems, and (3) transparent governance frameworks that balance privacy with analytical transparency, thereby enabling reliable, data‑driven decision‑making.
Comments & Academic Discussion
Loading comments...
Leave a Comment