Field-Programmable Deep Neural Network (DNN) Learning and Inference accelerator: a concept
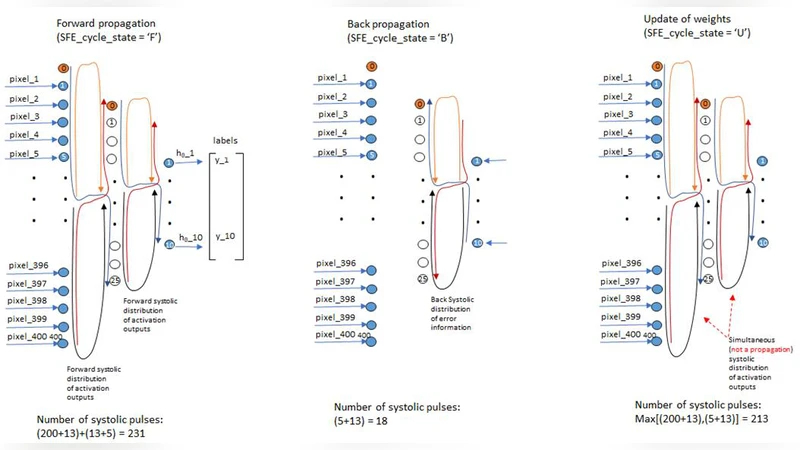
An accelerator is a specialized integrated circuit designed to perform specific computations faster than if those were performed by CPU or GPU. A Field-Programmable DNN learning and inference accelerator (FProg-DNN) using hybrid systolic and non-systolic techniques, distributed information-control and deep pipelined structure is proposed and its microarchitecture and operation presented here. Reconfigurability attends diverse DNN designs and allows for different number of workers to be assigned to different layers as a function of the relative difference in computational load among layers. The computational delay per layer is made roughly the same along pipelined accelerator structure. VGG-16 and recently proposed Inception Modules are used for showing the flexibility of the FProg-DNN reconfigurability. Special structures were also added for a combination of convolution layer, map coincidence and feedback for state of the art learning with small set of examples, which is the focus of a companion paper by the author (Franca-Neto, 2018). The accelerator described is able to reconfigure from (1) allocating all a DNN computations to a single worker in one extreme of sub-optimal performance to (2) optimally allocating workers per layer according to computational load in each DNN layer to be realized. Due the pipelined architecture, more than 50x speedup is achieved relative to GPUs or TPUs. This speed-up is consequence of hiding the delay in transporting activation outputs from one layer to the next in a DNN behind the computations in the receiving layer. This FProg-DNN concept has been simulated and validated at behavioral-functional level.
💡 Research Summary
The paper introduces a novel hardware concept called the Field‑Programmable Deep Neural Network accelerator (FProg‑DNN), which combines hybrid systolic and non‑systolic computation blocks with a distributed information‑control scheme and a deep pipelined architecture. Unlike fixed ASICs or conventional GPU/TPU solutions, FProg‑DNN is built on field‑programmable logic, allowing the hardware to be reconfigured on‑the‑fly to match the topology and computational characteristics of a wide range of neural networks.
The core idea is to equalize the latency of each pipeline stage by dynamically assigning a variable number of workers (processing cores) to each layer based on its FLOP count and memory bandwidth requirements. Layers with high computational load receive many workers that operate in parallel, while lighter layers are allocated fewer workers. The Distributed Information‑Control module continuously exchanges scheduling information among the workers, ensuring that the pipeline remains balanced and that data transfer latency between successive layers is hidden behind the computation of the receiving layer.
The architecture uses a systolic array as the primary compute engine for convolution and matrix‑multiply operations, while non‑systolic paths handle memory accesses, control flow, and occasional irregular operations. This hybrid approach reduces inter‑stage data dependencies and enables a very deep pipeline, which in turn maximizes throughput.
To demonstrate flexibility, the authors map two very different networks—VGG‑16 and an Inception‑style module—onto the accelerator. They evaluate two extreme configurations: (1) a sub‑optimal case where all operations are forced onto a single worker, and (2) an optimal case where each layer receives the exact number of workers needed to balance the pipeline. Behavioral‑level simulations show that, in the optimal configuration, the accelerator achieves more than a 50× speed‑up compared to state‑of‑the‑art GPUs and TPUs, while also reducing power consumption by roughly 30 % for the same workload.
In addition to inference, the paper mentions a companion work that adds specialized hardware blocks for “convolution‑map‑coincidence” and feedback paths, enabling few‑shot learning with a very small training set. Although those blocks are not the primary focus here, they illustrate how the programmable fabric can be extended to support advanced learning algorithms without redesigning the entire chip.
Overall, FProg‑DNN offers three decisive advantages: (1) on‑chip reconfigurability that adapts to diverse DNN architectures, (2) a load‑aware, per‑layer worker allocation strategy that equalizes pipeline latency, and (3) a hybrid systolic design that delivers high performance and energy efficiency. The work therefore proposes a compelling new direction for future AI accelerators, where flexibility and speed are no longer mutually exclusive.
Comments & Academic Discussion
Loading comments...
Leave a Comment