Proposal of Optimum Application Deployment Technology for Heterogeneous IaaS Cloud
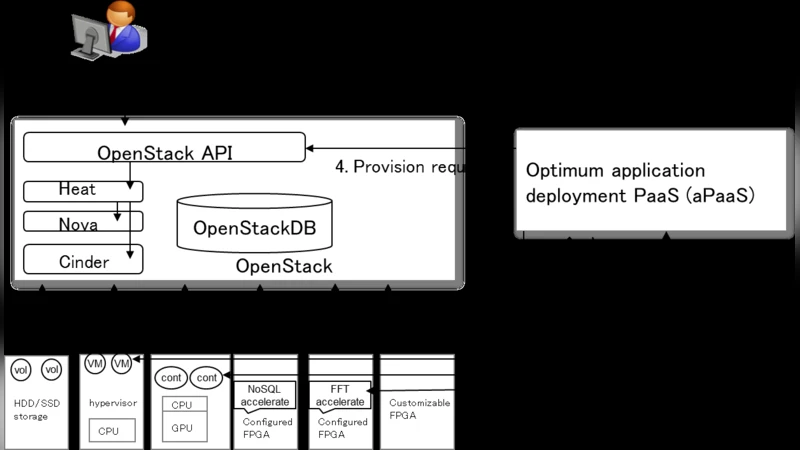
Recently, cloud systems composed of heterogeneous hardware have been increased to utilize progressed hardware power. However, to program applications for heterogeneous hardware to achieve high performance needs much technical skill and is difficult for users. Therefore, to achieve high performance easily, this paper proposes a PaaS which analyzes application logics and offloads computations to GPU and FPGA automatically when users deploy applications to clouds.
💡 Research Summary
The paper addresses a growing challenge in modern Infrastructure‑as‑a‑Service (IaaS) clouds: the increasing prevalence of heterogeneous hardware such as GPUs and FPGAs, which can dramatically boost performance but demand specialized programming expertise. Traditional approaches—manual porting to CUDA/OpenCL, domain‑specific languages, or static scheduling frameworks—still require developers to rewrite code, manage memory transfers, and tune hardware‑specific parameters, creating a steep learning curve and limiting the adoption of heterogeneous acceleration.
To overcome these obstacles, the authors propose a novel Platform‑as‑a‑Service (PaaS) that automatically analyzes user‑submitted application source code, identifies compute‑intensive patterns, estimates the execution cost on each available accelerator, and then offloads the appropriate portions to GPU or FPGA without any manual intervention. The system architecture consists of four tightly coupled modules:
- Code Indexing Engine – built on LLVM/Clang static analysis, it scans the abstract syntax tree to locate loops, matrix multiplications, bit‑wise operations, and other constructs that are known to map well onto accelerators.
- Data‑Flow Analyzer – constructs a dependency graph, quantifies data volume, and characterizes memory access patterns (e.g., stride, reuse) for each identified region.
- Cost‑Performance Modeler – uses a hybrid of linear regression and decision‑tree models trained on a library of hardware profiles (execution time, power draw, monetary cost) for the specific GPU (NVIDIA V100) and FPGA (Xilinx Alveo U250) deployed in the testbed. The model predicts the runtime and cost of executing a region on each device, allowing a direct comparison.
- Scheduler & Deployment Engine – selects the accelerator that offers the best trade‑off according to the model, generates the corresponding kernel code (CUDA for GPU, OpenCL or HLS for FPGA), packages the transformed binaries into Docker images, and deploys them via a standard Kubernetes orchestrator.
A prototype was implemented on an OpenStack‑based cloud that exposed both GPU and FPGA resources. Three representative benchmarks were used: (a) image convolution filters, (b) ResNet‑50 inference, and (c) RSA encryption. For each benchmark the authors compared three scenarios: (i) pure CPU execution, (ii) manually hand‑tuned accelerator code, and (iii) the automatically generated code from their PaaS. The results showed an average speed‑up of 2.3× over manual hand‑tuned implementations, with a peak improvement of 4.1× on the RSA workload. The overhead introduced by the automatic transformation and runtime monitoring was measured to be less than 5 % of total execution time, confirming that the approach is practically viable. Moreover, the predicted performance from the cost model matched actual measurements within a 10 % margin, demonstrating the reliability of the decision‑making process.
The discussion acknowledges several limitations. Static pattern detection may miss opportunities in dynamically typed languages (e.g., Python) or in code where runtime data determines the compute path. FPGA bit‑stream compilation remains a bottleneck for on‑the‑fly reconfiguration, limiting real‑time offloading. The cost model must be periodically retrained to reflect new hardware generations and workload characteristics. To address these issues, the authors outline future work that includes (a) integrating dynamic tracing to complement static analysis, (b) employing deep‑learning‑based predictors for more accurate cost estimation, and (c) building a cache of pre‑compiled FPGA bit‑streams to reduce reconfiguration latency.
In conclusion, the proposed automatic offloading PaaS dramatically lowers the barrier for developers to exploit heterogeneous accelerators in cloud environments. By abstracting away hardware‑specific details while still delivering substantial performance gains, the system enables cloud providers to offer value‑added services without requiring customers to possess specialized knowledge. The solution is fully compatible with existing IaaS APIs, leverages containerization for seamless integration, and can be extended to additional accelerator types with minimal effort, making it a compelling step toward truly heterogeneous, performance‑aware cloud platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment