Reversing the asymmetry in data exfiltration
Preventing data exfiltration from computer systems typically depends on perimeter defences, but these are becoming increasingly fragile. Instead we suggest an approach in which each at-risk document is supplemented by many fake versions of itself. An attacker must either exfiltrate all of them; or try to discover which is the real one while operating within the penetrated system, and both are difficult. Creating and maintaining many fakes is relatively inexpensive, so the advantage that typically accrues to an attacker now lies with the defender. We show that algorithmically generated fake documents are reasonably difficult to detect using algorithmic analytics.
💡 Research Summary
The paper proposes a novel defensive paradigm that flips the usual asymmetry in data‑exfiltration scenarios by flooding a target system with thousands of automatically generated fake versions of each sensitive document. Traditional perimeter defenses (firewalls, traffic throttling, invisible watermarks, etc.) become ineffective once an attacker has already penetrated the network, because exfiltration can be performed via low‑and‑slow channels, DNS tunneling, audio signals, or removable media. Instead of trying to block the document itself, the authors suggest creating a large pool of “chaff” that looks statistically similar to the real document, forcing the attacker either to exfiltrate the entire pool (which is costly in bandwidth and storage) or to spend considerable effort inside the compromised host to identify the genuine file.
Fake‑generation methodology
The system builds each fake by preserving roughly 70 % of the original word set and then performing controlled substitutions. For nouns, verbs, adjectives, and adverbs the algorithm queries WordNet and the Words API to obtain synonyms, antonyms, and semantically associated terms, caches these lists, and randomly selects a replacement. After each substitution a grammar‑checking API ensures the sentence remains syntactically valid. Numbers are generated according to Benford’s Law so that the distribution of leading digits matches real‑world data; credit‑card numbers receive special handling because of the Luhn check digit, while dates are shifted by random offsets but with a bias toward earlier dates to avoid a simple midpoint attack. Paragraph‑level insertions or deletions are also supported, using a user‑provided bank of sample paragraphs that can be inserted to increase variability.
Secret sharing and file‑name randomisation
Because the attacker is assumed to have full read access to the host, the system cannot store an explicit flag indicating which file is genuine. The authors therefore employ a (2, 2) Shamir secret‑sharing scheme: one share is stored on the server (useless by itself) and the other is kept by the legitimate user. When a user requests a document, both shares are combined to reconstruct the secret, which maps deterministically to the real file’s name. All files—including the real one—are renamed to random alphanumeric strings, and they are saved in an order determined by these random names, thereby scrambling timestamps. Background processes make trivial edits to fake files at random intervals so that the real document’s modification time never stands out.
Attack‑side detection techniques
The red‑team component attempts to rank files by “suspicion score” using several statistical signals:
- n‑gram frequency – The product of individual word frequencies divided by the joint frequency of the pair (f(w₁)·f(w₂)/(f(w₁w₂)+1)). Low‑frequency collocations indicate possible substitutions.
- Rate of new words – The cumulative count of unique words versus total words follows a predictable digamma‑shaped curve in normal prose. Sudden bumps suggest paragraph‑level insertions.
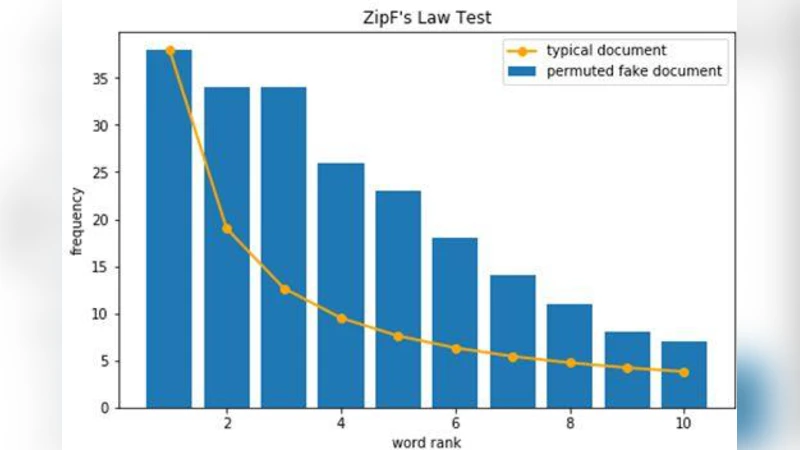
- Zipf’s law – Real documents exhibit a classic Zipfian distribution of word frequencies. Deviations, especially in the tail of high‑frequency function words, can reveal a fake.
- Benford’s law – For non‑date numeric strings, the distribution of leading digits is compared to the expected Benford frequencies; large deviations raise suspicion.
Each metric yields a normalized score; the scores are combined (e.g., weighted sum) to produce an overall ranking. The real document should ideally appear at the top, but the authors demonstrate that with a sufficiently large fake pool the ranking becomes noisy and the attacker must still exfiltrate a substantial fraction of files to guarantee inclusion of the genuine one.
Experimental evaluation
A red‑team/blue‑team prototype was built. The blue‑team generated thousands of fakes for a sample confidential report, applied secret sharing, random naming, and timestamp obfuscation. The red‑team implemented the detection pipeline described above. Results showed that individual detectors (n‑gram, new‑word rate, Zipf, Benford) each produced modest discrimination, but when combined the overall detection accuracy dropped sharply as the number of fakes increased. For pools of a few hundred fakes, the attacker could identify the real file with ~70 % success; for pools of several thousand, success fell below 20 %, effectively forcing the attacker to exfiltrate most of the pool.
Discussion of costs and limitations
The primary cost to the defender is storage (tens of gigabytes for thousands of medium‑size PDFs) and modest CPU for periodic fake updates. Operational overhead includes managing secret shares, ensuring users have access to their share, and handling the random‑name/timestamp mechanisms. The approach does not prevent exfiltration per se; it merely raises the attacker’s cost. The authors acknowledge that sophisticated language models (e.g., large transformer‑based generators) could eventually produce fakes that are even harder to distinguish, potentially narrowing the defender’s advantage. Moreover, an insider with both the user‑share and system‑share could bypass the protection entirely.
Conclusion
The paper demonstrates that “fake document flooding” is a feasible and effective way to invert the usual attacker‑defender asymmetry in data‑exfiltration scenarios. By automating the creation of statistically plausible decoys and hiding the identity of the genuine file through secret sharing and metadata randomisation, defenders can impose arbitrarily large work factors on adversaries. Future work should explore more advanced generation techniques, scalable secret‑management infrastructures, and integration with existing DLP solutions.
Comments & Academic Discussion
Loading comments...
Leave a Comment