Investigation of Frame Alignments for GMM-based Digit-prompted Speaker Verification
Frame alignments can be computed by different methods in GMM-based speaker verification. By incorporating a phonetic Gaussian mixture model (PGMM), we are able to compare the performance using alignments extracted from the deep neural networks (DNN) and the conventional hidden Markov model (HMM) in digit-prompted speaker verification. Based on the different characteristics of these two alignments, we present a novel content verification method to improve the system security without much computational overhead. Our experiments on the RSR2015 Part-3 digit-prompted task show that, the DNN based alignment performs on par with the HMM alignment. The results also demonstrate the effectiveness of the proposed Kullback-Leibler (KL) divergence based scoring to reject speech with incorrect pass-phrases.
💡 Research Summary
This paper investigates how different frame‑alignment strategies affect the performance and security of Gaussian‑Mixture‑Model (GMM) based speaker verification in a digit‑prompted scenario. In such systems the speaker must utter a short sequence of spoken digits that is known in advance; the verification task therefore requires both speaker identity confirmation and content validation.
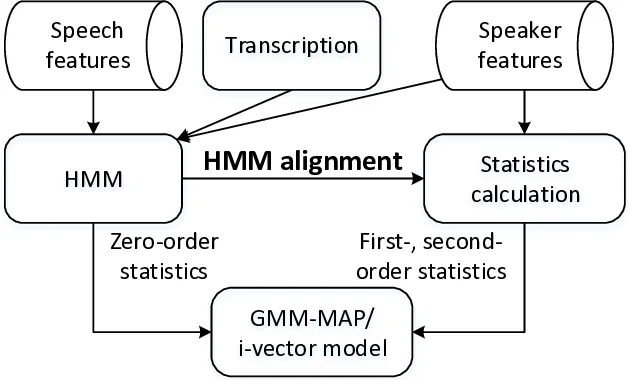
Two alignment methods are examined under exactly the same phonetic unit set and using a phonetic GMM (PGMM) to model each unit with a mixture of Gaussians. The first method is the conventional hidden‑Markov‑model (HMM) forced alignment. Each digit is modeled as a three‑state HMM, each state by a 16‑component GMM, and Viterbi or forward‑backward (FB) decoding is performed given the known transcription. This yields a soft posterior P(s|x_t, h) that is highly accurate when the spoken digits match the prompt, but degrades sharply if the user mis‑reads the prompt.
The second method uses a deep neural network (DNN). The DNN has four fully‑connected layers (512 units each) and 33 output nodes corresponding to the HMM states. It is trained on the same data using the HMM‑Viterbi alignments as targets, and at test time provides frame‑wise posteriors P(s|x_t, τ) that depend only on local acoustic cues, not on the supplied transcription. Consequently, DNN posteriors are robust to transcription errors but can be more sensitive to acoustic noise.
Both alignments feed the PGMM to compute Baum‑Welch statistics (zero‑order N, first‑order F, second‑order Σ). These statistics are then used in two downstream speaker‑modeling pipelines: (i) GMM‑MAP adaptation, where the speaker‑specific means are updated with a relevance factor of 5.0 and verification scores are log‑likelihood ratios; (ii) i‑vector extraction, where a total‑variability matrix of rank 400 is trained, followed by LDA, length normalization, and PLDA scoring. The universal background model (UBM) contains 512 mixtures and is gender‑independent.
Experiments are conducted on the RSR2015 Part‑3 digit‑prompted corpus. The evaluation set contains four trial types: target‑correct (TC), target‑wrong (TW), imposter‑correct (IC), and imposter‑wrong (IW). Primary speaker‑verification metrics (EER, minDCF) are reported for TC‑IC trials, while the ability to reject wrong content is measured on TC‑TW trials. Results show that both HMM‑based and DNN‑based alignments achieve virtually identical speaker‑verification performance for both GMM‑MAP and i‑vector systems, confirming that, when the content is correct, the choice of alignment does not materially affect speaker discrimination.
The most innovative contribution is a lightweight content‑verification technique that exploits the complementary nature of the two alignments. Because HMM alignment relies on the supplied transcription, a mismatch between spoken digits and the prompt forces the HMM to produce an erroneous state sequence, whereas the DNN alignment remains unchanged (it is blind to the transcription). The authors therefore compute a Kullback‑Leibler (KL) divergence between the two posterior distributions for each frame:
KL = (1/T) Σ_t Σ_p γ_HMM(p,t) log
Comments & Academic Discussion
Loading comments...
Leave a Comment