Representing Social Media Users for Sarcasm Detection
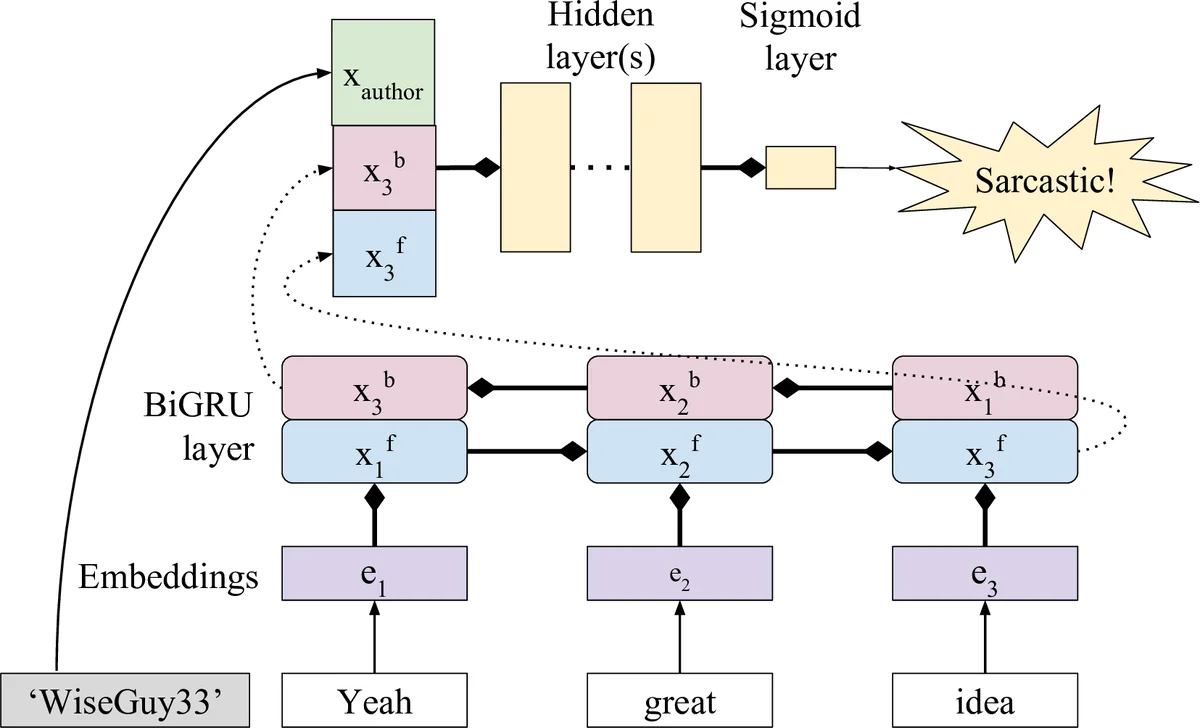
We explore two methods for representing authors in the context of textual sarcasm detection: a Bayesian approach that directly represents authors’ propensities to be sarcastic, and a dense embedding approach that can learn interactions between the author and the text. Using the SARC dataset of Reddit comments, we show that augmenting a bidirectional RNN with these representations improves performance; the Bayesian approach suffices in homogeneous contexts, whereas the added power of the dense embeddings proves valuable in more diverse ones.
💡 Research Summary
The paper investigates how to incorporate author information into sarcasm detection on Reddit comments. Using the large Self‑Annotated Reddit Corpus (SARC), the authors compare two author‑modeling strategies added to a bidirectional GRU (BiGRU) text encoder. The first strategy treats each author’s historical sarcasm and non‑sarcasm counts as a Bayesian prior: a simple two‑dimensional integer vector (s, n) is converted into a Bernoulli probability and concatenated with the text representation. Unseen authors receive a neutral (0, 0) prior. The second strategy assigns each author a learnable 15‑dimensional dense embedding; a special UNK embedding is used for authors not seen during training. Both author representations are fed into one or two fully‑connected layers before a sigmoid output that predicts the probability of sarcasm.
Experiments are conducted on five splits: the balanced full SARC sample, and balanced and unbalanced subsets of the r/politics and r/AskReddit subreddits. Performance is measured with macro‑averaged F1, reported as the mean of ten runs with bootstrapped 95 % confidence intervals. Results show that adding any author information improves over the text‑only baseline. In the focused subreddits (politics and AskReddit), the Bayesian prior consistently outperforms the dense embeddings, likely because the limited number of comments per author makes a simple frequency estimate more reliable. On the full, heterogeneous dataset, the dense author embeddings achieve the highest scores, indicating that they can capture richer interactions between an author’s stylistic habits and the comment content.
Qualitative analysis of selected examples illustrates the complementary strengths of the two approaches. The Bayesian prior can correct a misprediction when an author is known to be highly sarcastic, while the embedding can rescue cases where sarcasm is signaled by idiosyncratic lexical patterns unique to a user. However, the embedding sometimes over‑estimates sarcasm for authors with few training examples, leading to false positives on non‑sarcastic comments.
The study situates its contributions within prior work on sarcasm detection, noting that many earlier systems relied on Twitter data, hashtags, or extensive feature engineering (e.g., stylometric or personality cues). Compared to the state‑of‑the‑art CASCADE model (Hazarika et al., 2018), which uses author, forum, and text embeddings plus heavy feature engineering, the proposed approach achieves comparable or better performance while using far fewer resources—no forum embeddings and only simple or randomly initialized author vectors.
Key insights include: (1) author information is a powerful signal for sarcasm detection; (2) a simple Bayesian prior suffices when data per author is scarce or the community is topically focused; (3) dense embeddings become advantageous as the amount of author‑specific data grows and the task requires modeling complex author‑text interactions. The authors suggest future work on adaptive models that dynamically adjust the complexity of author representations based on the amount of available data per user, and on integrating subreddit‑level context to further improve performance.
In conclusion, the paper demonstrates that both a lightweight Bayesian prior and a modestly sized dense embedding can meaningfully enhance sarcasm detection on Reddit, offering practical guidelines for leveraging user‑level metadata in large‑scale social‑media NLP tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment