Ensemble-based Overlapping Community Detection using Disjoint Community Structures
While there has been a plethora of approaches for detecting disjoint communities from real-world complex networks, some methods for detecting overlapping community structures have also been recently proposed. In this work, we argue that, instead of developing separate approaches for detecting overlapping communities, a promising alternative is to infer the overlapping communities from multiple disjoint community structures. We propose an ensemble-based approach, called EnCoD, that leverages the solutions produced by various disjoint community detection algorithms to discover the overlapping community structure. Specifically, EnCoD generates a feature vector for each vertex from the results of the base algorithms and learns which features lead to detect densely connected overlapping regions in an unsupervised way. It keeps on iterating until the likelihood of each vertex belonging to its own community maximizes. Experiments on both synthetic and several real-world networks (with known ground-truth community structures) reveal that EnCoD significantly outperforms nine state-of-the-art overlapping community detection algorithms. Finally, we show that EnCoD is generic enough to be applied to networks where the vertices are associated with explicit semantic features. To the best of our knowledge, EnCoD is the second ensemble-based overlapping community detection approach after MEDOC [1].
💡 Research Summary
EnCoD (Ensemble‑based Overlapping Community Detection) introduces a novel framework for detecting overlapping community structures by exploiting the diversity of multiple disjoint community detection (CD) algorithms. The authors begin with the observation that many state‑of‑the‑art disjoint CD methods produce markedly different partitions when the input vertex ordering is varied. By running M distinct disjoint CD algorithms on K random vertex orderings each, EnCoD collects M × K diverse community structures, which serve as “multiple views” of the underlying network topology.
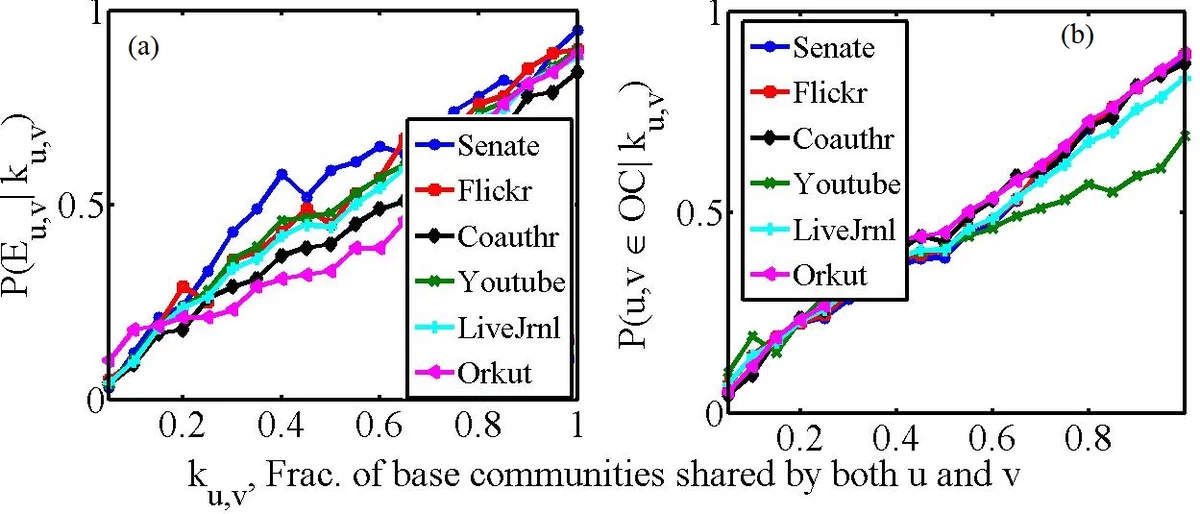
Each vertex v is then represented by a high‑dimensional feature vector Fᵥ. The vector encodes v’s membership across all base communities: for every base community C, an involvement function INV(v, C) (binary or weighted) indicates the extent to which v belongs to C. After normalisation, these vectors place all vertices into a common feature space where similarity can be measured (e.g., cosine or Jaccard similarity). Empirical analysis on six real‑world networks shows a strong positive correlation between the fraction of shared base communities (k_uv) and both (i) the probability of an edge existing between u and v, and (ii) the probability that u and v belong to the same ground‑truth overlapping community. This validates the hypothesis that shared base memberships are informative cues for overlapping structure.
The core of EnCoD is an unsupervised iterative optimisation. Initially each vertex is assigned to a singleton community with a high similarity threshold τ_L. In each iteration the algorithm (1) randomly removes vertices from their current communities, (2) reassigns them to any community whose average similarity with its members exceeds the community‑specific threshold τ_j, and (3) updates τ_j to the current average similarity of its members. The objective function is the log‑likelihood of vertices belonging to their assigned communities; it is guaranteed not to decrease across iterations, and the process stops when convergence is reached. The final result is a set of overlapping communities OC = {OC₁, OC₂, …}, where a vertex may belong to multiple communities simultaneously.
EnCoD’s design rests on two assumptions: (a) overlapping communities are densely connected subgraphs, and (b) vertices within the same community exhibit high similarity in the feature space derived from base partitions. The method is largely agnostic to the specific base algorithms; experiments with a variety of disjoint CD methods (e.g., Louvain, Infomap, Label Propagation) demonstrate that even weak base algorithms do not degrade EnCoD’s performance, though stronger bases provide modest gains. Moreover, performance saturates after a certain number of base solutions, indicating robustness to the quantity of input partitions.
Comprehensive evaluation uses three standard overlapping‑community metrics: Overlapping Normalized Mutual Information (ONMI), Ω‑index, and F‑Score. Across synthetic LFR benchmarks and six large real‑world networks with known ground truth, EnCoD consistently outperforms nine state‑of‑the‑art overlapping CD algorithms, including MEDOC, PVOC, and PEACOCK. Notably, when vertices carry additional semantic attributes (e.g., text tags, user profiles), EnCoD can incorporate these features alongside the base‑community features, further improving detection accuracy.
In summary, EnCoD demonstrates that an ensemble of disjoint community detections can be transformed into a powerful feature representation, and that unsupervised similarity‑driven optimisation on this representation yields superior overlapping community detection. It bridges the gap between disjoint and overlapping CD, offers a flexible framework for integrating heterogeneous vertex information, and sets a new benchmark for ensemble‑based community analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment