Using Randomness to Improve Robustness of Machine-Learning Models Against Evasion Attacks
Machine learning models have been widely used in security applications such as intrusion detection, spam filtering, and virus or malware detection. However, it is well-known that adversaries are always trying to adapt their attacks to evade detection. For example, an email spammer may guess what features spam detection models use and modify or remove those features to avoid detection. There has been some work on making machine learning models more robust to such attacks. However, one simple but promising approach called {\em randomization} is underexplored. This paper proposes a novel randomization-based approach to improve robustness of machine learning models against evasion attacks. The proposed approach incorporates randomization into both model training time and model application time (meaning when the model is used to detect attacks). We also apply this approach to random forest, an existing ML method which already has some degree of randomness. Experiments on intrusion detection and spam filtering data show that our approach further improves robustness of random-forest method. We also discuss how this approach can be applied to other ML models.
💡 Research Summary
The paper addresses a fundamental vulnerability of machine‑learning‑based security systems: evasion attacks in which an adversary subtly modifies input features (e.g., removing certain words from a spam email or altering malware signatures) to bypass detection. While prior work has explored robust learning, game‑theoretic defenses, and adversarial training, most of these approaches rely on deterministic models that still concentrate predictive power on a relatively small set of features. According to the Minimum Description Length principle, a concise model tends to over‑fit training data and consequently depends heavily on a few high‑impact attributes, making it easy for an attacker to target those attributes.
To mitigate this problem, the authors propose a two‑stage randomization framework that injects uncertainty both during model construction (training time) and during model deployment (application time). The framework is instantiated on Random Forest, an ensemble method that already contains randomness via bagging and random subspace selection, but the authors enhance it in two specific ways:
-
Weighted Random Forest (Training‑time Randomization).
- For each feature, a weight proportional to its frequency of use across the forest is computed.
- When growing each decision tree, a random subset of F features is drawn (as in standard Random Forest), but the split is chosen from the subset with the smallest weight, i.e., from features that have been used less often.
- This penalizes “over‑used” attributes and forces the ensemble to distribute importance more uniformly across the feature space. Consequently, an attacker cannot rely on a handful of dominant features to evade the entire model pool.
-
Cluster‑based Random Model Subset Selection (Application‑time Randomization).
- After training, the M trees are clustered based on structural similarity (e.g., overlapping splits, similar decision paths).
- At prediction time, a small subset of k trees is sampled uniformly at random, but one tree is taken from each of k different clusters, ensuring low correlation among the selected models.
- The final decision is made by a strict rule (e.g., the instance is classified as “spam” only if all selected trees output “spam”). This rule, combined with the random selection, makes it difficult for an attacker to know which trees will be consulted, thereby increasing the cost of a successful evasion.
The authors also provide a theoretical analysis that bounds the minimal number of feature modifications an adversary must perform given the size of the model pool (M) and the number of models consulted at inference (k). The bound shows a monotonic increase in required modifications as k grows, illustrating the trade‑off between robustness and computational overhead.
Experimental Evaluation.
Two canonical security datasets are used: the Spambase dataset (57 binary/continuous word‑frequency features) and the KDD‑99 intrusion detection dataset. The authors compare three configurations:
- Standard Random Forest (baseline).
- Weighted Random Forest (only training‑time randomization).
- Weighted Random Forest + Cluster‑based Random Subset (full framework).
Key findings:
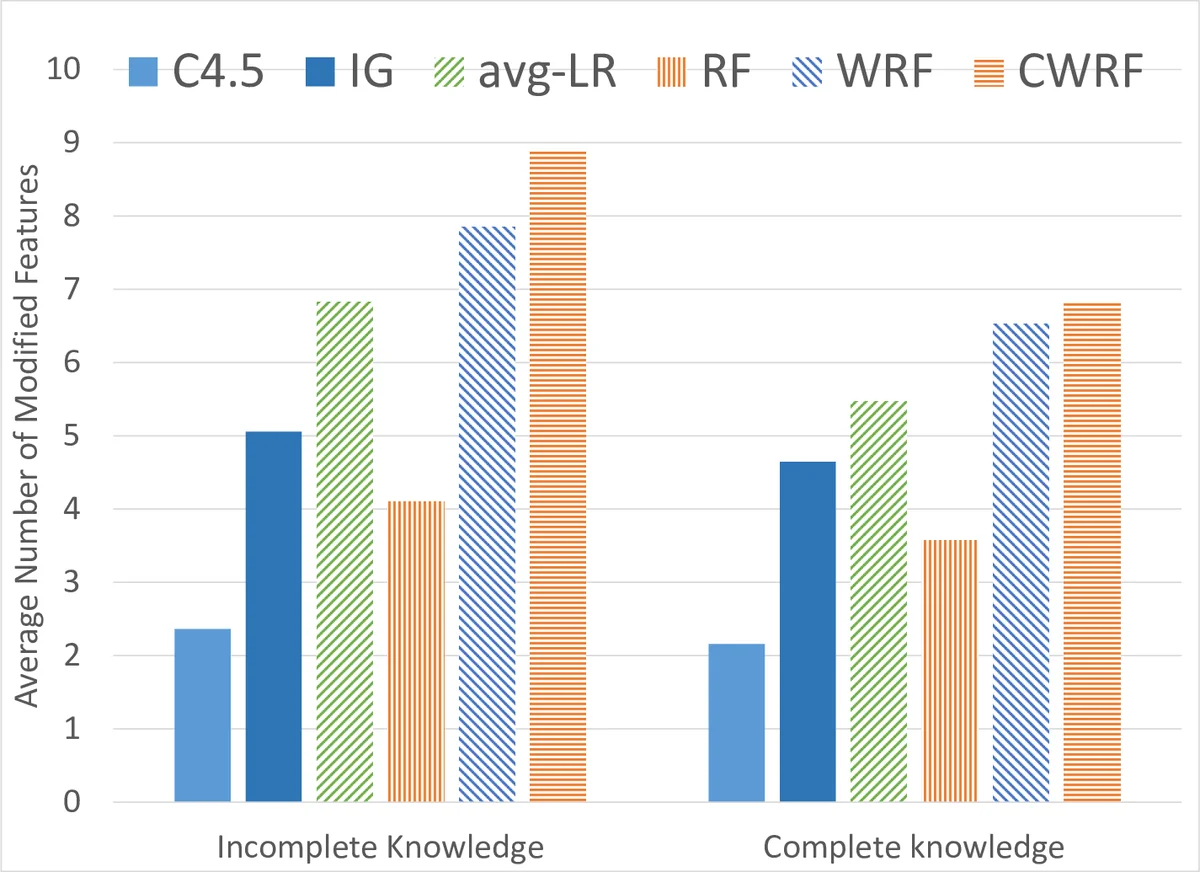
- Classification accuracy remains essentially unchanged (within 1 % of baseline), confirming that robustness gains do not come at the expense of predictive performance.
- In simulated evasion attacks where the adversary can modify any feature at unit cost, the baseline forest can be fooled by altering 1–2 features. The weighted forest raises this requirement to 3–4 features, and the full framework pushes it further to 5–6 features.
- The cost increase is consistent across both datasets, demonstrating the approach’s generality.
Broader Impact and Extensions.
The paper argues that the same randomization principles can be applied to other learners such as Support Vector Machines, Logistic Regression, or even deep neural networks, by designing analogous feature‑weighting schemes and model‑selection strategies. Moreover, because the modifications to existing algorithms are minimal (mostly additional bookkeeping of feature frequencies and a clustering step), the approach is practical for real‑world deployments where retraining large models is costly.
Conclusion.
By deliberately injecting randomness at both training and inference, the proposed framework transforms a deterministic, feature‑concentrated classifier into a diversified ensemble whose decision boundary is harder to predict and manipulate. The empirical results substantiate that this simple yet principled technique can significantly raise the adversary’s cost without sacrificing detection accuracy, offering a compelling, low‑overhead defense for security‑critical machine‑learning applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment