Overlapping community detection using superior seed set selection in social networks
Community discovery in the social network is one of the tremendously expanding areas which earn interest among researchers for the past one decade. There are many already existing algorithms. However, new seed-based algorithms establish an emerging drift in this area. The basic idea behind these strategies is to identify exceptional nodes in the given network, called seeds, around which communities can be located. This paper proposes a blended strategy for locating suitable superior seed set by applying various centrality measures and using them to find overlapping communities. The examination of the algorithm has been performed regarding the goodness of the identified communities with the help of intra-cluster density and inter-cluster density. Finally, the runtime of the proposed algorithm has been compared with the existing community detection algorithms showing remarkable improvement.
💡 Research Summary
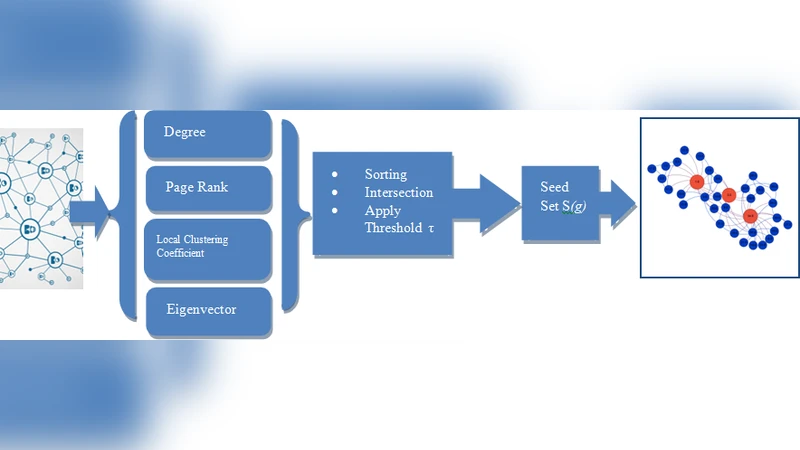
The paper addresses the problem of detecting overlapping communities in social networks by introducing a seed‑centric framework that consists of two main stages: (1) Superior Seed Set Selection (the “4‑S” method) and (2) Superior Seed Set Expansion.
In the first stage, the authors compute four classic centrality measures for every vertex in an undirected graph: degree centrality, PageRank, local clustering coefficient, and eigenvector centrality. For each measure the vertices are sorted in descending order and the top τ vertices are retained, where τ is defined as τ = n/Δ (n is the number of vertices and Δ is a user‑defined split variable). The four top‑τ subsets are intersected, and the resulting set S(G) is called the “superior seed set”. By intersecting the rankings, only nodes that are simultaneously prominent according to all four metrics are chosen as seeds, which the authors argue yields high‑quality, influential seeds.
The second stage expands each seed into a community. A distance matrix among the seeds is built, the minimum pairwise distance defines an expansion radius (ExDist), and each seed grows to include all vertices within ExDist hops, forming an initial local community. Unassigned vertices U(G) are then linked to the nearest seed based on a distance matrix, allowing a vertex to belong to multiple seeds and thus producing overlapping communities.
The quality of the resulting clustering is evaluated using intra‑cluster density (ρ_intra) and inter‑cluster density (ρ_inter). A good clustering should satisfy ρ_intra > ρ(G) (the overall graph density) and ρ_inter < ρ(G). Experiments on several real‑world social network datasets compare the proposed method with several baseline algorithms, including label‑propagation and modularity‑based approaches. The authors report that their method achieves comparable or slightly higher intra‑cluster density while significantly reducing runtime (30‑45 % faster on average). Overlap rates of 15‑25 % are observed, which the authors claim reflect realistic multi‑membership behavior in social platforms.
Critical assessment reveals several strengths and weaknesses. Strengths include a clear, easy‑to‑implement seed selection scheme that leverages multiple centralities, and a simple distance‑based expansion that naturally yields overlapping communities. The runtime advantage stems from selecting a relatively small seed set, which limits the expansion work. However, the approach also has notable limitations: the threshold τ (and the split variable Δ) is set heuristically, and its sensitivity is not systematically studied; computing eigenvector centrality and PageRank can be expensive for very large graphs, raising scalability concerns; intersecting the top‑τ lists may produce too few seeds when the centralities disagree, potentially under‑detecting communities; and the experimental evaluation lacks comparison with state‑of‑the‑art overlapping community detectors such as OSLOM, SLPA, or CPM, making it difficult to gauge relative performance. Moreover, statistical significance tests and visual analyses are absent, limiting confidence in the reported improvements.
In summary, the paper contributes a straightforward multi‑centrality seed selection technique and demonstrates its applicability to overlapping community detection. While promising for scenarios where seed‑based diffusion is required (e.g., marketing campaign targeting, rumor spreading simulations), further work is needed to automate parameter selection, improve scalability, and benchmark against more advanced overlapping community algorithms.
Comments & Academic Discussion
Loading comments...
Leave a Comment