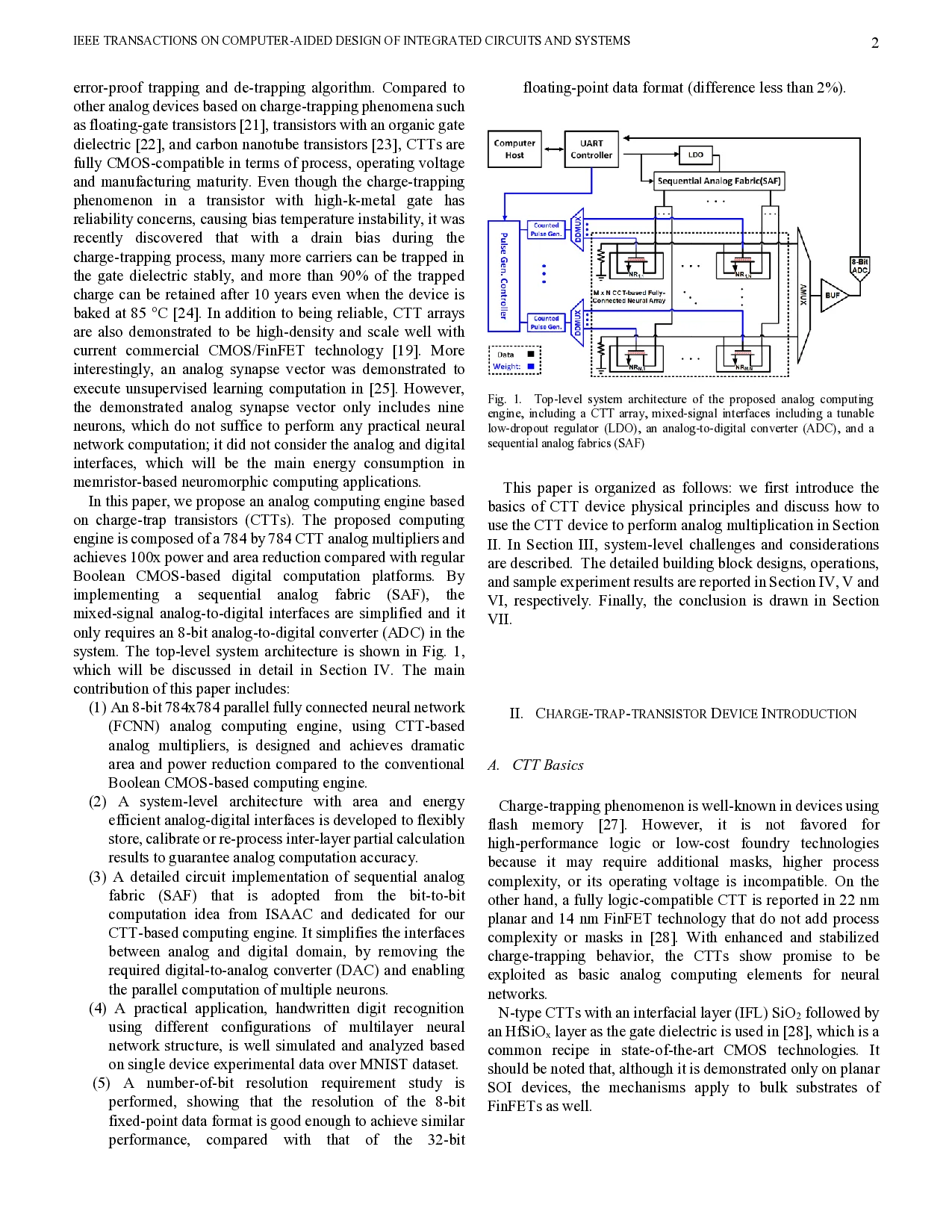
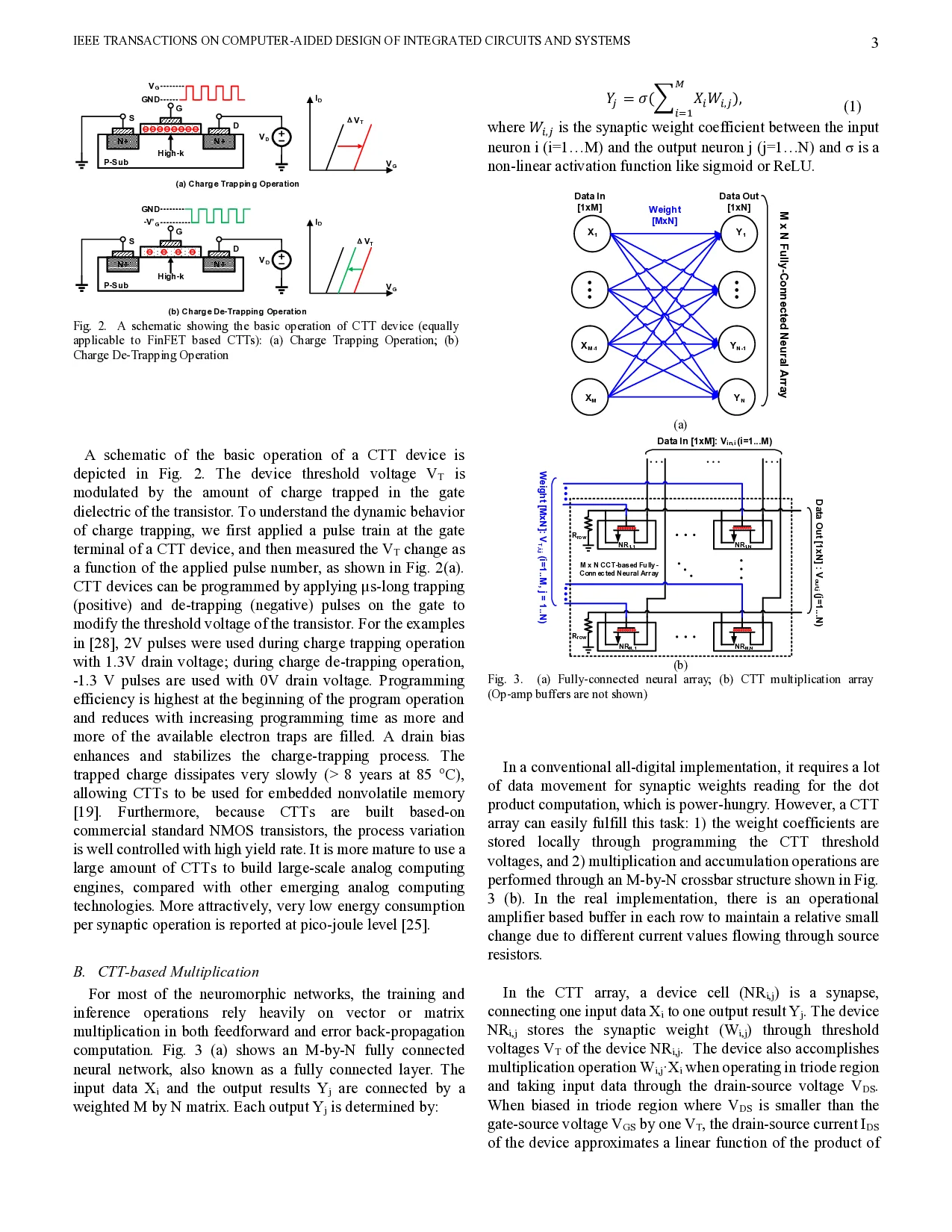
An analog neural network computing engine based on CMOS-compatible charge-trap transistor (CTT) is proposed in this paper. CTT devices are used as analog multipliers. Compared to digital multipliers, CTT-based analog multiplier shows significant area and power reduction. The proposed computing engine is composed of a scalable CTT multiplier array and energy efficient analog-digital interfaces. Through implementing the sequential analog fabric (SAF), the engine mixed-signal interfaces are simplified and hardware overhead remains constant regardless of the size of the array. A proof-of-concept 784 by 784 CTT computing engine is implemented using TSMC 28nm CMOS technology and occupied 0.68mm2. The simulated performance achieves 76.8 TOPS (8-bit) with 500 MHz clock frequency and consumes 14.8 mW. As an example, we utilize this computing engine to address a classic pattern recognition problem -- classifying handwritten digits on MNIST database and obtained a performance comparable to state-of-the-art fully connected neural networks using 8-bit fixed-point resolution.
Deep Dive into An Analog Neural Network Computing Engine using CMOS-Compatible Charge-Trap-Transistor (CTT).
An analog neural network computing engine based on CMOS-compatible charge-trap transistor (CTT) is proposed in this paper. CTT devices are used as analog multipliers. Compared to digital multipliers, CTT-based analog multiplier shows significant area and power reduction. The proposed computing engine is composed of a scalable CTT multiplier array and energy efficient analog-digital interfaces. Through implementing the sequential analog fabric (SAF), the engine mixed-signal interfaces are simplified and hardware overhead remains constant regardless of the size of the array. A proof-of-concept 784 by 784 CTT computing engine is implemented using TSMC 28nm CMOS technology and occupied 0.68mm2. The simulated performance achieves 76.8 TOPS (8-bit) with 500 MHz clock frequency and consumes 14.8 mW. As an example, we utilize this computing engine to address a classic pattern recognition problem – classifying handwritten digits on MNIST database and obtained a performance comparable to state-
IEEE TRANSACTIONS ON COMPUTER-AIDED DESIGN OF INTEGRATED CIRCUITS AND SYSTEMS
1
Abstract— An analog neural network computing engine based
on CMOS-compatible charge-trap transistor (CTT) is proposed in
this paper. CTT devices are used as analog multipliers. Compared
to digital multipliers, CTT-based analog multiplier shows
significant area and power reduction. The proposed computing
engine is composed of a scalable CTT multiplier array and energy
efficient analog-digital interfaces. By implementing the sequential
analog fabric (SAF), the engine’s mixed-signal interfaces are
simplified and hardware overhead remains constant regardless of
the size of the array. A proof-of-concept 784 by 784 CTT
computing engine is implemented using TSMC 28nm CMOS
technology and occupies 0.68mm2. The simulated performance
achieves 76.8 TOPS (8-bit) with 500 MHz clock frequency and
consumes 14.8 mW. As an example, we utilize this computing
engine to address a classic pattern recognition problem --
classifying handwritten digits on MNIST database and obtained a
performance comparable to state-of-the-art fully connected
neural networks using 8-bit fixed-point resolution.
Index
Terms—Artificial
neural
networks,
Charge-trap
transistors, Fully-connected neural networks, Analog computing
engine
I. INTRODUCTION
EEP learning using convolutional and fully connected
neural networks has achieved unprecedented accuracy on
many modern artificial intelligence (AI) applications, such as
image, voice, and DNA pattern detection and recognition
[1-10]. However, one of the major problems that hinder its
commercial feasibility is that neural networks require great
computational resources and memory bandwidth even for very
simple tasks. The insufficient ability of modern computing
platforms to deliver simultaneously energy-efficient and high
performance leads to a gap between supply and demand.
Unfortunately, with current Boolean logic and Complementary
*These authors contributed equally to this work.
Y. Du, L. Du, X. Gu, J. Du, X.S. Wang, B. Hu, M.C. F. Chang are with the High Speed Electronics Lab
(HSEL), University of California, Los Angeles, CA, 420 Westwood Plaza, Los Angeles, CA 90095
X. Gu, S. S. Iyer are with Center for Heterogeneous Integration and Performance Scaling (CHIPS),
Electrical Engineering Department, University of California, Los Angeles , CA 90095
X. Chen is with University of California, Irvine, CA 92697
M.-C. F. Chang is also with National Chiao Tung University, No. 1001, Daxue Rd, Hsinchu, Taiwan
Y. Du, L. Du, M. Jiang, J. Su are also with Kneron, Inc, San Diego, CA 92121
Metal Oxide Semiconductor (CMOS)-based computing
platforms, the gap keeps growing mainly due to limitations in
both devices and architectures. State-of-the-art digital
computation processors such as CPUs, GPUs or DSPs in the
system-on-chip (SoC) systems [11-13] cannot meet the
required computational throughput within the power and cost
constraints in many practical applications. Most of the modern
computational
processors
are
all
implemented
on
Von-Neumann architecture where the processor and main
memory are separated. However, as transistor technology
scaling reaches its physical limits, the computational
throughput using current architectures will inevitably saturate
[14]. Furthermore, the extensive processor-memory data
movements have become the dominated energy consumption
[39].
To improve the performance and energy efficiency of the
neuromorphic system, several analog computing architectures
have been reported to significantly reduce the power-hungry
data transfer and avoid the memory wall [15-16, 34-35, 37-38].
By integrating computation into memory, these architectures
show great potential to achieve high performance and
efficiency.
For
example,
PRIME
[34]
employing
ReRAM-based memory array for neuromorphic computation
shows a potential of 2~3 orders improvement in terms of
system performance and energy efficiency. ISAAC [35]
proposes a crossbar-based pipeline architecture and data
encoding techniques to reduce data converters’ complexity.
Eight memristors each storing 2-bit is used to support 16-bits
resolution and multi-bit data are calculated in a bit-to-bit
sequential fashion to reduce DAC/ADC resolution. However,
ISAAC does not provide circuit level implementation and
simulations. Even though the simulation results from PRIME
and ISAAC show great potential, the task of fabricating large
memristor arrays is still very challenging. In addition, various
analog devices have also been demonstrated for these
applications [17-18]. However, these devices require the
introduction of new materials or extra manufacture processes,
which are not currently supported by major CMOS foundries.
Thus, they cannot be embedded into the large volume
commercial CMOS chips.
Recently, charge-trap transistors (CTTs) were demonstrated
to be used as digital mem
…(Full text truncated)…
This content is AI-processed based on ArXiv data.