The Effect of the Digit Slicing Architecture on the FFT Butterfly
Most communications systems tend to achieve bandwidth, power and cost efficiencies to capable to describe modulation scheme. Hence for signal modulation, orthogonal frequency division multiplexing (OFDM) transceiver is introduced to cover communications demand in four generation. However high-performance Fast Fourier Transforms (FFT) as a main heart of OFDM acts beyond the view. In order to achieve capable FFT, design, and realization of its efficient internal structure is key issues of this research work. In this paper implementation of a high-performance butterfly for FFT by applying digit slicing technique is presented. The proposed design focused on the trade-off between the speed and active silicon area for the chip implementation. The new architecture was investigated and simulated with the MATLAB software. The Verilog HDL code in Xilinx ISE environment was derived to describe the FFT Butterfly functionality and was downloaded to Virtex II FPGA board.
💡 Research Summary
The paper addresses the performance bottleneck in FFT implementations for OFDM transceivers, namely the butterfly unit that performs complex multiplications. Traditional radix‑2 DIT butterflies require four real multipliers and two adders for each complex multiplication, consuming significant FPGA DSP resources and limiting the achievable clock frequency. To overcome this, the authors propose a digit‑slicing architecture that eliminates the need for a conventional multiplier by exploiting the fact that FFT twiddle factors are known constants in advance.
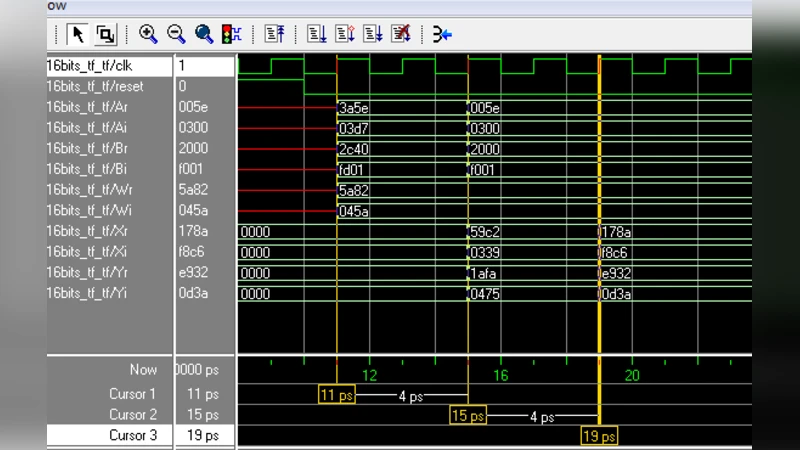
In the proposed scheme, 16‑bit fixed‑point inputs (in 2’s‑complement) are partitioned into four 4‑bit slices. Each slice is multiplied by the constant twiddle factor using only shift‑and‑add operations, effectively implementing a multiplier‑less constant‑coefficient multiplier. The twiddle factors are stored in a ROM lookup table. The sliced results are weighted by their positional significance (2^(p·k)) and summed to reconstruct the full‑precision complex product. This approach reduces the critical path to a series of simple adders and shifters, which map efficiently onto FPGA lookup tables (LUTs) and registers.
The design was modeled in MATLAB, coded in Verilog HDL, synthesized with Xilinx ISE/XST, and verified on a Virtex‑II XC2V500‑6FG456 FPGA. Two butterfly implementations were compared: (1) a conventional design using the FPGA’s built‑in high‑speed multiplier, and (2) the digit‑slicing multiplier‑less design. Synthesis results show that the digit‑slicing butterfly achieves a maximum operating frequency of 535.9 MHz, more than 2.7× higher than the conventional butterfly’s 198.98 MHz. However, the slice‑based design consumes more logic resources (≈31 k equivalent gates versus ≈18 k gates for the conventional design). The dedicated 16‑bit digit‑slicing multiplier itself can run at 609.6 MHz, indicating that the remaining bottleneck lies in the surrounding adder/subtractor network.
Key insights include: (i) digit‑slicing is highly effective when the multiplier operand is a known constant, allowing the replacement of a full‑precision multiplier with a network of small adders and shifters; (ii) the method preserves the radix‑2 DIT butterfly’s functional correctness while substantially increasing throughput; (iii) the trade‑off is increased LUT usage, which may affect area and power budgets; (iv) the approach is scalable to other radix sizes or mixed‑radix FFTs, provided the twiddle factors remain constant; (v) the design demonstrates a practical path for high‑speed, low‑latency FFT cores on mid‑range FPGAs without relying on dedicated DSP blocks.
The authors conclude that digit‑slicing offers a compelling solution for ultra‑fast FFT processing in real‑time communication systems, especially where clock speed is critical. Future work is suggested on optimizing slice width to balance resource usage, extending the technique to larger FFT sizes and different radix algorithms, and conducting detailed power consumption analyses to assess suitability for low‑power applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment