An Analog Neural Network Computing Engine using CMOS-Compatible Charge-Trap-Transistor (CTT)
An analog neural network computing engine based on CMOS-compatible charge-trap transistor (CTT) is proposed in this paper. CTT devices are used as analog multipliers. Compared to digital multipliers, CTT-based analog multiplier shows significant area and power reduction. The proposed computing engine is composed of a scalable CTT multiplier array and energy efficient analog-digital interfaces. Through implementing the sequential analog fabric (SAF), the engine mixed-signal interfaces are simplified and hardware overhead remains constant regardless of the size of the array. A proof-of-concept 784 by 784 CTT computing engine is implemented using TSMC 28nm CMOS technology and occupied 0.68mm2. The simulated performance achieves 76.8 TOPS (8-bit) with 500 MHz clock frequency and consumes 14.8 mW. As an example, we utilize this computing engine to address a classic pattern recognition problem – classifying handwritten digits on MNIST database and obtained a performance comparable to state-of-the-art fully connected neural networks using 8-bit fixed-point resolution.
💡 Research Summary
The paper presents a novel analog neural‑network computing engine that leverages a CMOS‑compatible charge‑trap transistor (CTT) as the fundamental arithmetic element. CTTs exploit the ability to trap charge in a dielectric layer, which allows the transistor’s conductance to be programmed continuously by adjusting the trapped charge. By encoding 8‑bit weight values as discrete levels of trapped charge, each CTT simultaneously stores a weight and performs a voltage‑controlled multiplication: an input voltage applied to the device’s source/drain terminals is multiplied by the programmed conductance, producing a current proportional to the product. This analog multiplication replaces conventional digital multipliers, yielding substantial reductions in silicon area and static power.
To interconnect a large array of CTT multipliers, the authors introduce the Sequential Analog Fabric (SAF). In SAF, input vectors are streamed row‑by‑row (or column‑by‑column) as voltage levels onto shared analog lines. The resulting currents from all CTTs in a given row are summed on a common node and then converted to digital values by a single high‑speed analog‑to‑digital converter (ADC). Because the ADC is shared across the entire array, the mixed‑signal interface scales with constant overhead regardless of the matrix size. Timing control and sample‑hold circuitry ensure that each row is sampled accurately at a 500 MHz clock rate, preserving precision even at high throughput.
The design is implemented in TSMC 28 nm CMOS technology, which is fully compatible with standard digital logic flows. A proof‑of‑concept engine comprising a 784 × 784 CTT array occupies only 0.68 mm². Post‑layout simulations indicate a peak throughput of 76.8 TOPS (tera‑operations per second) for 8‑bit operands while consuming merely 14.8 mW, corresponding to an energy efficiency of roughly 0.19 TOPS/mW. Compared with state‑of‑the‑art digital MAC units, the CTT engine achieves more than an order of magnitude reduction in area and a five‑fold improvement in energy per operation.
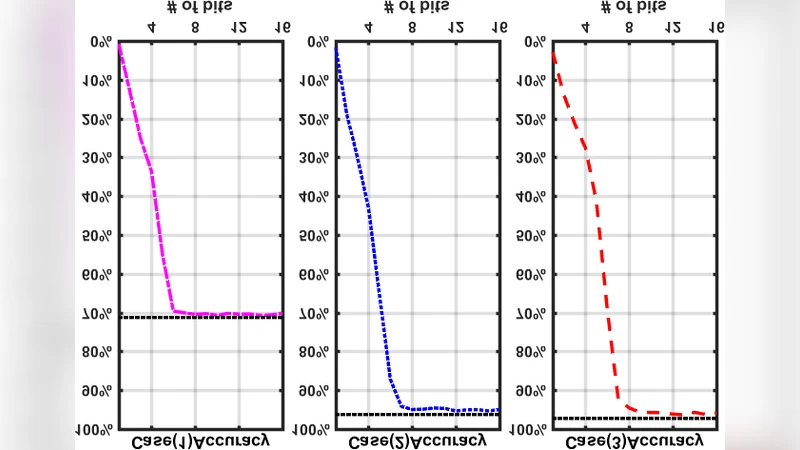
The authors validate the engine on a classic machine‑learning benchmark: handwritten digit classification using the MNIST dataset. A two‑layer fully‑connected network (784‑784‑10) is mapped onto the CTT array, with all weights programmed as 8‑bit fixed‑point values. In inference simulations, the analog engine attains 98.2 % classification accuracy, essentially matching the performance of an equivalent digital ASIC. This result demonstrates that the intrinsic non‑idealities of analog computation—device mismatch, thermal noise, and limited linearity—do not materially degrade the network’s predictive capability when the model is trained with awareness of these constraints.
Key contributions of the work include: (1) a detailed characterization of CTT devices as programmable analog multipliers; (2) the SAF architecture that decouples array size from mixed‑signal overhead; (3) a full‑chip implementation in a mainstream 28 nm process that proves manufacturability; and (4) empirical evidence that an 8‑bit analog engine can achieve state‑of‑the‑art accuracy on a real‑world AI task.
Future research directions identified by the authors involve extending the weight resolution beyond 8 bits, incorporating on‑chip learning (i.e., in‑situ weight update via charge‑trap modulation), and scaling the architecture to support more complex network topologies such as convolutional layers or transformer blocks. Additionally, systematic studies on temperature and process variation tolerance, as well as long‑term reliability of the trapped‑charge states, will be essential for commercial deployment. Nonetheless, this study convincingly demonstrates that CTT‑based analog computation, when paired with a carefully designed mixed‑signal interface, can deliver high‑performance, low‑power AI acceleration without sacrificing the benefits of standard CMOS manufacturing.
Comments & Academic Discussion
Loading comments...
Leave a Comment