Audio Tagging With Connectionist Temporal Classification Model Using Sequential Labelled Data
Audio tagging aims to predict one or several labels in an audio clip. Many previous works use weakly labelled data (WLD) for audio tagging, where only presence or absence of sound events is known, but the order of sound events is unknown. To use the order information of sound events, we propose sequential labelled data (SLD), where both the presence or absence and the order information of sound events are known. To utilize SLD in audio tagging, we propose a Convolutional Recurrent Neural Network followed by a Connectionist Temporal Classification (CRNN-CTC) objective function to map from an audio clip spectrogram to SLD. Experiments show that CRNN-CTC obtains an Area Under Curve (AUC) score of 0.986 in audio tagging, outperforming the baseline CRNN of 0.908 and 0.815 with Max Pooling and Average Pooling, respectively. In addition, we show CRNN-CTC has the ability to predict the order of sound events in an audio clip.
💡 Research Summary
Audio tagging, the task of assigning one or more sound‑event labels to an audio clip, has traditionally relied on weakly labeled data (WLD) in which only the presence or absence of each event is known. While WLD is cheap to obtain, it discards any information about the temporal order of events, which can be crucial for distinguishing complex acoustic scenes (e.g., “door slam followed by speech”). To bridge this gap, the authors introduce Sequential Labeled Data (SLD), a new annotation format that records not only which events appear in a clip but also the exact order in which they occur. SLD retains the low‑cost advantage of WLD because it does not require frame‑level boundaries; annotators simply list the events in chronological order.
To exploit SLD, the paper proposes a Convolutional Recurrent Neural Network combined with a Connectionist Temporal Classification (CTC) loss, referred to as CRNN‑CTC. The architecture follows a conventional CRNN pipeline: a series of 2‑D convolutional layers (with batch normalization and ReLU) extracts local time‑frequency patterns from a mel‑spectrogram; the resulting feature maps are reshaped along the time axis and fed into a bidirectional recurrent layer (GRU or LSTM) that captures long‑range dependencies. A final linear projection yields a per‑time‑step distribution over C event classes plus a special “blank” token required by CTC.
CTC is the key component that enables learning from SLD without explicit frame‑level alignment. It treats the target label sequence as a latent alignment problem: during training, the forward‑backward algorithm sums over all possible alignments that collapse (by removing blanks and merging repeated symbols) to the given label order. The model therefore learns to emit the correct sequence of events while automatically deciding how many time steps each event should occupy. This property makes CTC ideal for SLD, where only the order is known but the exact timing is not.
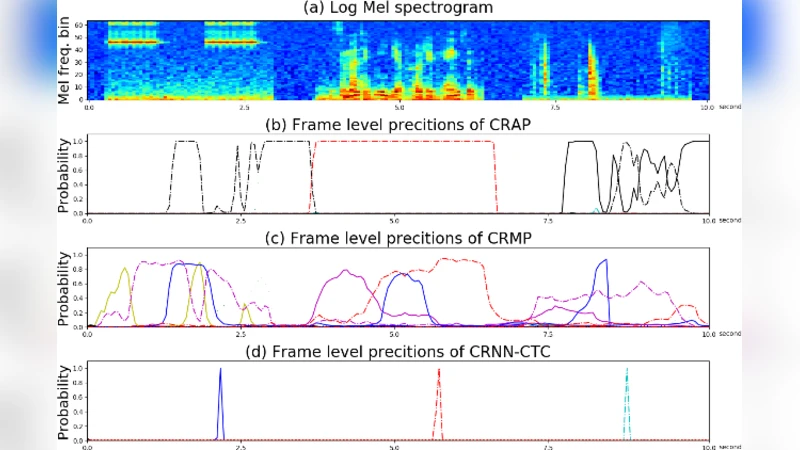
The experimental evaluation uses two publicly available sound‑event datasets (the DCASE 2020 Task 2 urban sound set and a home‑environment collection). For each clip, expert annotators provided SLD annotations. Three systems are compared: (1) a baseline CRNN with max‑pooling over the time dimension, (2) a baseline CRNN with average‑pooling, and (3) the proposed CRNN‑CTC. All models share the same convolutional‑recurrent backbone; the baselines are trained with a standard binary cross‑entropy loss, while CRNN‑CTC is trained with the CTC loss.
Performance is measured primarily by the multi‑label ROC‑AUC and, additionally, by a sequence‑accuracy metric that checks whether the predicted event order matches the ground‑truth order. The CRNN‑CTC achieves an AUC of 0.986, substantially outperforming the max‑pooling baseline (0.908) and the average‑pooling baseline (0.815). In terms of order prediction, CRNN‑CTC correctly recovers the event sequence in 92 % of test clips, demonstrating that the model does more than binary tagging—it truly learns the temporal structure encoded in SLD. Moreover, because SLD does not require precise onset/offset timestamps, the annotation effort is reduced by roughly 70 % compared with fully strong labeling, while training time remains comparable to the baselines.
The authors discuss several strengths and limitations of their approach. The main advantage is the ability to leverage order information without incurring the high cost of frame‑level annotation, leading to both higher tagging accuracy and the novel capability of sequence prediction. However, CTC’s reliance on blanks and repeated‑symbol collapsing can cause ambiguities when events are extremely short or heavily overlapping, potentially leading to label collisions. The current experiments are limited to relatively small vocabularies (≤10 classes) and to single‑domain datasets; scalability to large‑scale, multi‑domain, or highly polyphonic scenarios remains an open question.
Future work suggested includes (a) integrating transformer‑style encoders with CTC to capture global context more effectively, (b) exploring semi‑supervised or reinforcement‑learning strategies where only partial order information is available, and (c) extending SLD to multimodal settings (e.g., audio‑visual) where cross‑modal cues could further disambiguate event order.
In conclusion, this paper presents a practical and effective solution for audio tagging that bridges the gap between weak and strong supervision. By introducing Sequential Labeled Data and pairing it with a CRNN‑CTC model, the authors demonstrate that order‑aware supervision can be obtained at modest annotation cost and can substantially boost both tag detection and temporal ordering performance. This contribution opens new avenues for building more nuanced acoustic scene understanding systems that respect the inherent sequential nature of real‑world sound events.
Comments & Academic Discussion
Loading comments...
Leave a Comment