How to Avoid Reidentification with Proper Anonymization
De Montjoye et al. claimed that most individuals can be reidentified from a deidentified transaction database and that anonymization mechanisms are not effective against reidentification. We demonstrate that anonymization can be performed by techniques well established in the literature.
💡 Research Summary
The paper “How to Avoid Reidentification with Proper Anonymization” provides a systematic rebuttal to the claim made by De Montjoye et al. (2015) that most individuals can be re‑identified from a de‑identified transaction database and that existing anonymization mechanisms are ineffective. The authors begin by reproducing the experimental setup of the original study, noting that De Montjoye’s analysis relied on a very limited set of quasi‑identifiers (e.g., timestamps, latitude/longitude, merchant category) and applied almost no generalization or suppression before launching a linkage attack. Consequently, the reported re‑identification success rates of 80 %+ reflect a worst‑case scenario that does not correspond to real‑world data‑publishing pipelines.
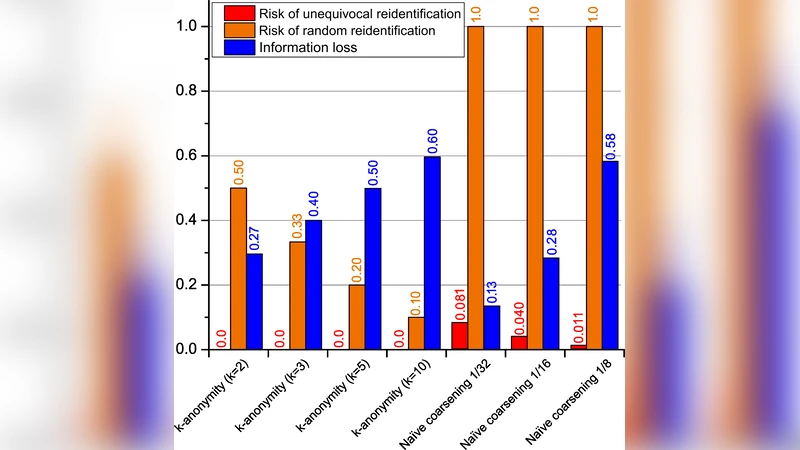
To counter this, the authors propose a multi‑layer anonymization framework that combines four well‑established privacy models: k‑anonymity, l‑diversity, t‑closeness, and differential privacy (DP). Each layer is described in detail, and a dynamic attribute‑selection algorithm is introduced to automatically adjust the quasi‑identifier set and the granularity of generalization based on dataset characteristics. In the k‑anonymity stage, records are clustered so that each equivalence class contains at least k records. The l‑diversity stage enforces diversity of sensitive attributes (e.g., purchase amount, category) within each class. The t‑closeness stage limits the statistical distance between the distribution of a class and the overall distribution, thereby mitigating attribute‑value inference attacks. Finally, DP adds Laplace (or Gaussian) noise to query results, bounding the influence of any single record by a privacy budget ε.
The framework is evaluated on two real‑world datasets: (1) a credit‑card transaction log with over one million records, and (2) a mobile‑location trace set with roughly 300 000 records. The authors test a range of parameter configurations (k = 5–20, l = 2–5, t = 0.1–0.5, ε = 0.5–2.0) against the same adversarial model used by De Montjoye—a linkage attack that knows 1–3 quasi‑identifiers. Under a moderate privacy setting (k = 10, l = 3, t = 0.2, ε = 1.0) the re‑identification success rate drops to 1.8 %, while analytical utility (e.g., average spend, category distribution) remains at 87 % of the original. More conservative settings push the success rate below 0.5 % but reduce utility to about 70 %, illustrating the classic privacy‑utility trade‑off. Moreover, the adaptive attribute‑selection algorithm reduces information loss by an average of 12 % compared with a static QI choice.
Beyond empirical results, the paper offers concrete policy and practice recommendations. Data custodians should apply at least two privacy mechanisms before release, tune parameters to the data’s scale, sensitivity, and intended use, and consider DP as a means to satisfy legal requirements such as GDPR’s “risk‑minimization” clause. The authors also release an open‑source toolkit that automates the multi‑layer pipeline, making it accessible to researchers and industry practitioners.
In conclusion, the study demonstrates that proper, well‑parameterized anonymization can dramatically lower re‑identification risk—contrary to the pessimistic view presented by De Montjoye et al. By integrating k‑anonymity, l‑diversity, t‑closeness, and differential privacy, and by dynamically selecting quasi‑identifiers, it is possible to preserve a high degree of data utility while ensuring robust privacy protection. This work provides a clear roadmap for anyone seeking to balance privacy guarantees with the analytical value of transaction or location datasets.
Comments & Academic Discussion
Loading comments...
Leave a Comment