Prosodic-Enhanced Siamese Convolutional Neural Networks for Cross-Device Text-Independent Speaker Verification
In this paper a novel cross-device text-independent speaker verification architecture is proposed. Majority of the state-of-the-art deep architectures that are used for speaker verification tasks consider Mel-frequency cepstral coefficients. In contrast, our proposed Siamese convolutional neural network architecture uses Mel-frequency spectrogram coefficients to benefit from the dependency of the adjacent spectro-temporal features. Moreover, although spectro-temporal features have proved to be highly reliable in speaker verification models, they only represent some aspects of short-term acoustic level traits of the speaker’s voice. However, the human voice consists of several linguistic levels such as acoustic, lexicon, prosody, and phonetics, that can be utilized in speaker verification models. To compensate for these inherited shortcomings in spectro-temporal features, we propose to enhance the proposed Siamese convolutional neural network architecture by deploying a multilayer perceptron network to incorporate the prosodic, jitter, and shimmer features. The proposed end-to-end verification architecture performs feature extraction and verification simultaneously. This proposed architecture displays significant improvement over classical signal processing approaches and deep algorithms for forensic cross-device speaker verification.
💡 Research Summary
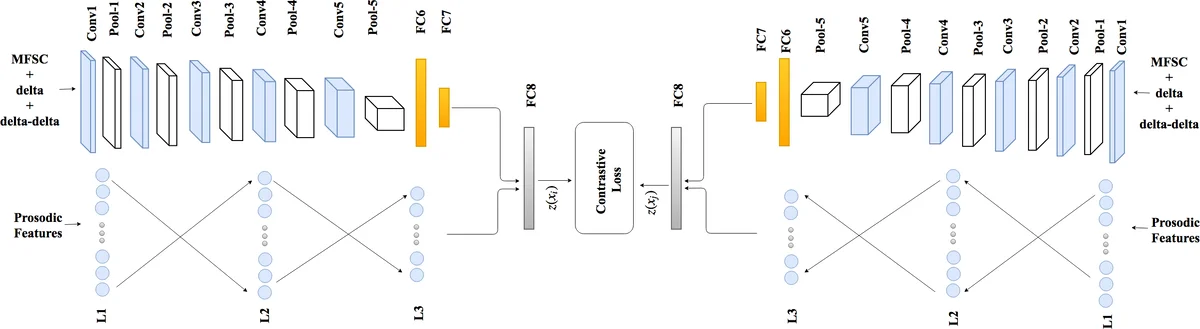
The paper introduces a novel cross‑device, text‑independent speaker verification system that combines short‑term spectral information with long‑term prosodic cues in a unified deep learning framework. The core of the system is a Siamese convolutional neural network (CNN) that processes Mel‑frequency spectrogram coefficients (MFSCs) rather than the more commonly used Mel‑frequency cepstral coefficients (MFCCs). MFSCs retain the locality of adjacent frequency bins because they are derived directly from the mel‑scaled power spectrum without a discrete cosine transform. The authors feed three channels—static MFSC, first‑order delta, and second‑order delta‑delta—into a CNN consisting of five convolutional blocks followed by two fully‑connected layers. A distinctive element is the heterogeneous max‑pooling strategy in the frequency dimension: three parallel pooling kernels of sizes 1×2, 1×3, and 1×4 are applied, and their outputs are concatenated depth‑wise. This multi‑scale pooling captures spectral patterns at different resolutions, improving the network’s ability to model speaker‑specific timbral characteristics.
To address the limitation of short‑term features, the system incorporates 18 prosodic descriptors extracted from the entire utterance, including duration‑related measures, fundamental‑frequency statistics, and jitter/shimmer indices that quantify voice‑quality perturbations. These prosodic features are processed by a multilayer perceptron (MLP) with two hidden layers of 64 units each and a 32‑unit output layer. The 32‑dimensional prosodic embedding is fused with the 128‑dimensional CNN embedding (output of the FC7 layer) through a joint fully‑connected fusion layer (FC8), yielding a final 128‑dimensional representation for each side of the Siamese pair.
Both branches of the Siamese network share weights, ensuring that the model learns device‑invariant representations. During training, the CNN is first pre‑trained as a speaker classifier using a softmax loss to encourage discriminative spectral features. Afterwards, the entire Siamese architecture is fine‑tuned with a contrastive loss: for genuine pairs (same speaker) the Euclidean distance between embeddings is minimized, while for impostor pairs (different speakers) the distance is forced to exceed a margin m. This loss directly embeds speaker identity information into the distance metric, producing a highly discriminative embedding space.
At inference time, each long utterance is first processed to obtain its prosodic vector. Then, several fixed‑length short segments (e.g., 3‑second windows) are randomly sampled from each utterance. Each segment pair, together with the corresponding prosodic vectors, is fed through the Siamese network to compute a distance. The final similarity score for the two long utterances is the average of these segment‑level distances, making the system robust to variable utterance lengths and to channel mismatches caused by different recording devices.
The authors claim that this end‑to‑end architecture, which jointly learns spectral and prosodic representations, outperforms traditional signal‑processing pipelines and existing deep learning baselines in forensic cross‑device verification scenarios. The main contributions are: (i) integration of prosodic, jitter, and shimmer features with a CNN‑based Siamese model; (ii) construction of a text‑independent embedding space that captures both short‑term and supra‑segmental cues; (iii) a fully data‑driven pipeline that eliminates the need for a separate enrollment phase, enabling real‑time verification; and (iv) a heterogeneous frequency‑domain pooling scheme that enriches multi‑scale spectral feature extraction.
Potential limitations include the computational overhead of extracting prosodic features and sampling multiple short segments, which may affect latency in real‑time deployments. Moreover, the paper does not provide extensive ablation studies across diverse languages, noise conditions, or device types, leaving open questions about the model’s generalizability. Future work could explore attention mechanisms to select the most informative segments, or end‑to‑end learning of prosodic representations to reduce preprocessing costs. Overall, the work presents a compelling approach to bridging the gap between short‑term acoustic modeling and long‑term voice characteristics for robust speaker verification across heterogeneous recording environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment