Learning Policy Representations in Multiagent Systems
Modeling agent behavior is central to understanding the emergence of complex phenomena in multiagent systems. Prior work in agent modeling has largely been task-specific and driven by hand-engineering domain-specific prior knowledge. We propose a general learning framework for modeling agent behavior in any multiagent system using only a handful of interaction data. Our framework casts agent modeling as a representation learning problem. Consequently, we construct a novel objective inspired by imitation learning and agent identification and design an algorithm for unsupervised learning of representations of agent policies. We demonstrate empirically the utility of the proposed framework in (i) a challenging high-dimensional competitive environment for continuous control and (ii) a cooperative environment for communication, on supervised predictive tasks, unsupervised clustering, and policy optimization using deep reinforcement learning.
💡 Research Summary
This paper, “Learning Policy Representations in Multiagent Systems,” introduces a novel, general-purpose framework for modeling agent behavior by learning continuous vector representations (embeddings) of their policies in an unsupervised manner. The core innovation lies in reframing agent modeling as a representation learning problem, eliminating the need for task-specific engineering or extensive domain knowledge. The framework requires only a limited set of interaction episodes—sequences of observations and actions—between agents.
The proposed method learns an encoder function, f_θ, that maps interaction episodes to a latent embedding space. To train this encoder effectively, the authors design a hybrid objective function combining generative and discriminative goals. The generative objective is based on conditional imitation learning. For a given agent, two distinct interaction episodes are sampled. The embedding derived from one episode conditions a policy network (decoder), which is then trained to imitate the behavior (observation-action pairs) from the other episode. Crucially, a single conditional policy network is shared across all agents, balancing sample efficiency with the flexibility to represent diverse behaviors through conditioning.
The discriminative objective promotes agent identification using a triplet loss. It encourages embeddings from different episodes of the same agent (positive and reference) to be closer in the latent space than embeddings from episodes of a different agent (negative). This ensures the learned representations are distinctive and cluster by agent identity.
The final loss is a weighted sum of these imitation and identification components, optimized via stochastic gradient descent with neural network parameterizations for both the encoder and the conditional policy network.
A significant conceptual contribution is the introduction of the “agent-interaction graph” to formalize and evaluate generalization in multiagent systems. Nodes represent agent policies, and edges represent interaction episodes. This formalism clearly distinguishes between different generalization regimes: “weak generalization” tests on unseen interactions between agents observed during training, while “strong generalization” tests on interactions involving entirely new agents, with only a few of their interactions with known agents seen during training.
The empirical evaluation demonstrates the framework’s utility across diverse downstream tasks in two contrasting environments: 1) RoboSumo, a high-dimensional competitive continuous control environment where humanoid robots wrestle, and 2) ParticleWorld, a cooperative environment where agents must communicate to navigate to landmarks.
The learned policy representations were evaluated on three types of tasks:
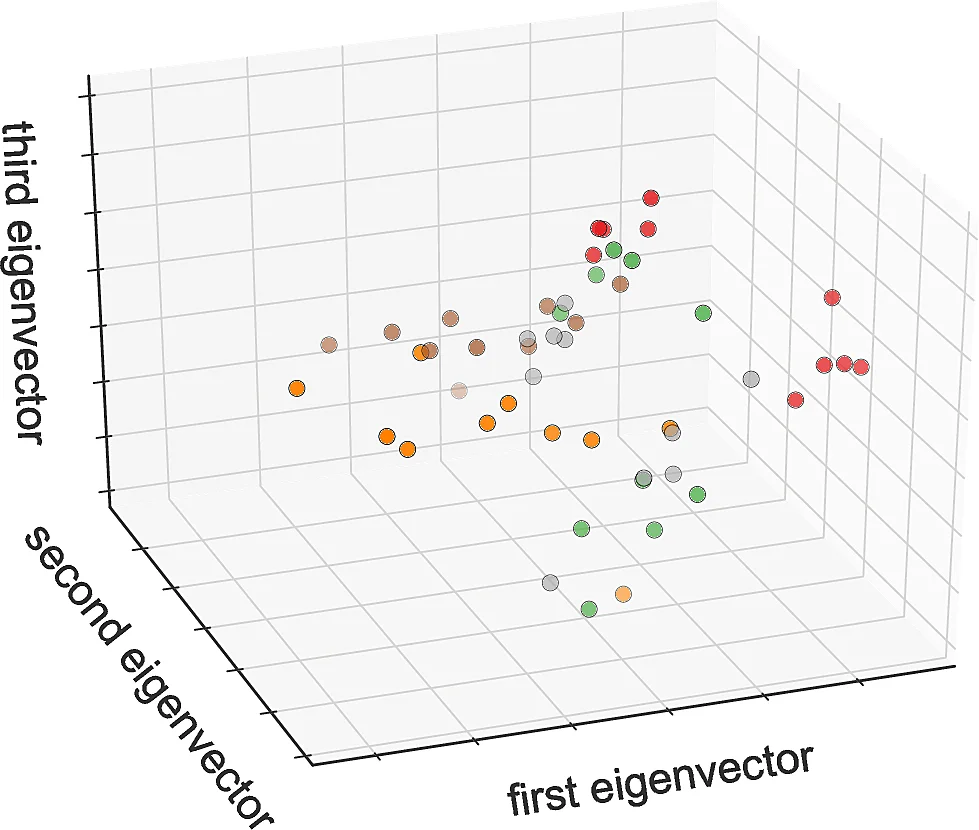
- Unsupervised Tasks: The embeddings successfully clustered agent policies based on behavioral similarity, enabling visualization and interpretation.
- Supervised Tasks: The embeddings served as effective feature vectors for predictive tasks, such as classifying the winner of a competitive match or an agent’s role in cooperation.
- Reinforcement Learning Tasks: This was the most compelling demonstration. The embeddings were used as “privileged information” to condition agent policies during RL training. In RoboSumo, policies that conditioned on the opponent’s embedding achieved superior win rates and learned much faster than baseline policies. In ParticleWorld, speaker agents conditioned on listener embeddings learned to communicate effectively with a much wider variety of listeners than standard approaches.
In conclusion, the paper presents a robust, unsupervised framework for learning disentangled and meaningful representations of agent policies from interaction data. The representations generalize well to novel agents and interactions and provide substantial benefits for core challenges in multiagent systems, including prediction, clustering, and—most notably—policy optimization via reinforcement learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment