Darwinian Data Structure Selection
Data structure selection and tuning is laborious but can vastly improve an application’s performance and memory footprint. Some data structures share a common interface and enjoy multiple implementations. We call them Darwinian Data Structures (DDS), since we can subject their implementations to survival of the fittest. We introduce ARTEMIS a multi-objective, cloud-based search-based optimisation framework that automatically finds optimal, tuned DDS modulo a test suite, then changes an application to use that DDS. ARTEMIS achieves substantial performance improvements for \emph{every} project in $5$ Java projects from DaCapo benchmark, $8$ popular projects and $30$ uniformly sampled projects from GitHub. For execution time, CPU usage, and memory consumption, ARTEMIS finds at least one solution that improves \emph{all} measures for $86%$ ($37/43$) of the projects. The median improvement across the best solutions is $4.8%$, $10.1%$, $5.1%$ for runtime, memory and CPU usage. These aggregate results understate ARTEMIS’s potential impact. Some of the benchmarks it improves are libraries or utility functions. Two examples are gson, a ubiquitous Java serialization framework, and xalan, Apache’s XML transformation tool. ARTEMIS improves gson by $16.5$%, $1%$ and $2.2%$ for memory, runtime, and CPU; ARTEMIS improves xalan’s memory consumption by $23.5$%. \emph{Every} client of these projects will benefit from these performance improvements.
💡 Research Summary
The paper introduces ARTEMIS, a cloud‑based, multi‑objective search‑based optimisation framework that automatically selects and tunes “Darwinian Data Structures” (DDS) in Java (and C++) programs. A DDS is defined as any concrete implementation of an abstract data type (ADT) for which multiple interchangeable implementations exist (e.g., List → ArrayList, LinkedList). The authors formalise the DDS selection and tuning problem as a multi‑objective optimisation over execution time, memory consumption, and CPU usage, subject to the constraint that the program must still pass its test suite.
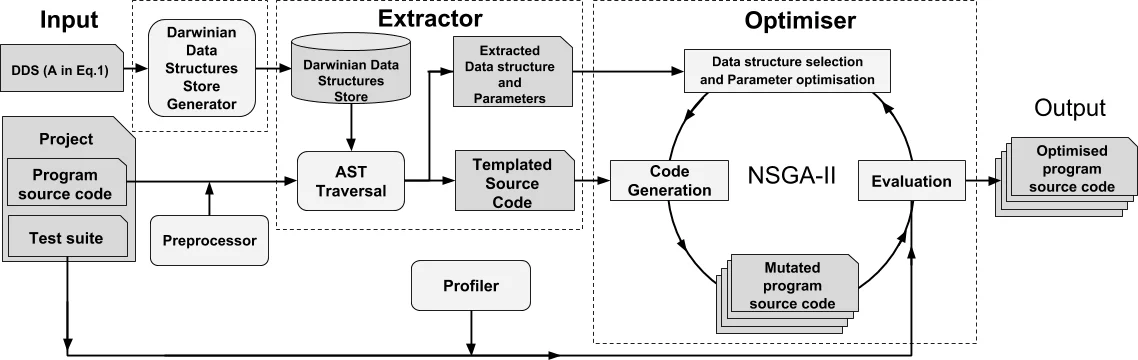
ARTEMIS consists of three main components. First, the Darwinian Data Structure Store Generator (DDSSG) analyses the target code’s class hierarchy and builds a store mapping each ADT to all its known implementations, using the Java Collections API as the default source. Second, the Extractor traverses the program’s abstract syntax tree, identifies all DDS usage sites, and rewrites them into parameterised placeholders (e.g., new D<T>(S) where D denotes the concrete implementation and S the constructor parameter such as initial capacity). Third, the Optimiser employs the NSGA‑II multi‑objective genetic algorithm to explore the combinatorial space of implementation substitutions and constructor parameter values. Fitness is evaluated by running the supplied regression test suite (to guarantee functional correctness) and measuring the three non‑functional metrics with an integrated profiler.
The search is guided by a Pareto‑front preservation strategy that focuses variation on the most promising regions of the search space, thereby keeping computational cost manageable even for large code bases. When a promising variant is found, ARTEMIS emits a source‑to‑source transformation together with a diff file, allowing developers to inspect, accept, or reject each change, thus limiting technical debt.
The authors evaluated ARTEMIS on a corpus of 43 Java projects: five DaCapo benchmark suites, eight popular open‑source GitHub projects, and thirty randomly sampled GitHub repositories that satisfied the tool’s constraints. Each project was run 30 times with its test suite to obtain statistically robust measurements. The results are striking: in 86 % of the projects (37 out of 43) ARTEMIS produced at least one variant that improved all three objectives simultaneously. Across the best variants, median improvements were 4.8 % in execution time, 10.1 % in memory usage, and 5.1 % in CPU consumption. Notably, library‑level improvements were observed: the Gson serialization library saw a 16.5 % reduction in memory, a 1 % speed‑up, and a 2.2 % CPU reduction; the Xalan XSLT processor achieved a 23.5 % memory reduction with unchanged runtime. Since these are libraries, every downstream client benefits from the gains.
The paper also discusses limitations. ARTEMIS requires a reasonably comprehensive test suite; without adequate coverage, the optimisation may over‑fit to the test harness and not reflect real‑world performance. Moreover, while the framework is language‑agnostic in principle, the current implementation only supports Java and C++, and extending it to other ecosystems would require building appropriate DDS stores and parsers.
In conclusion, the work makes a substantial contribution to Search‑Based Software Engineering by automating a traditionally manual optimisation task—data‑structure selection and parameter tuning—while handling multiple performance objectives. By integrating the optimisation into a cloud service that runs in the background, ARTEMIS reduces developer effort, enables small but cumulative performance gains, and demonstrates that even modest improvements at the library level can have far‑reaching impact across the software ecosystem.
Comments & Academic Discussion
Loading comments...
Leave a Comment