Unsupervised Domain Adaptation by Adversarial Learning for Robust Speech Recognition
In this paper, we investigate the use of adversarial learning for unsupervised adaptation to unseen recording conditions, more specifically, single microphone far-field speech. We adapt neural networks based acoustic models trained with close-talk cl…
Authors: Pavel Denisov, Ngoc Thang Vu, Marc Ferras Font
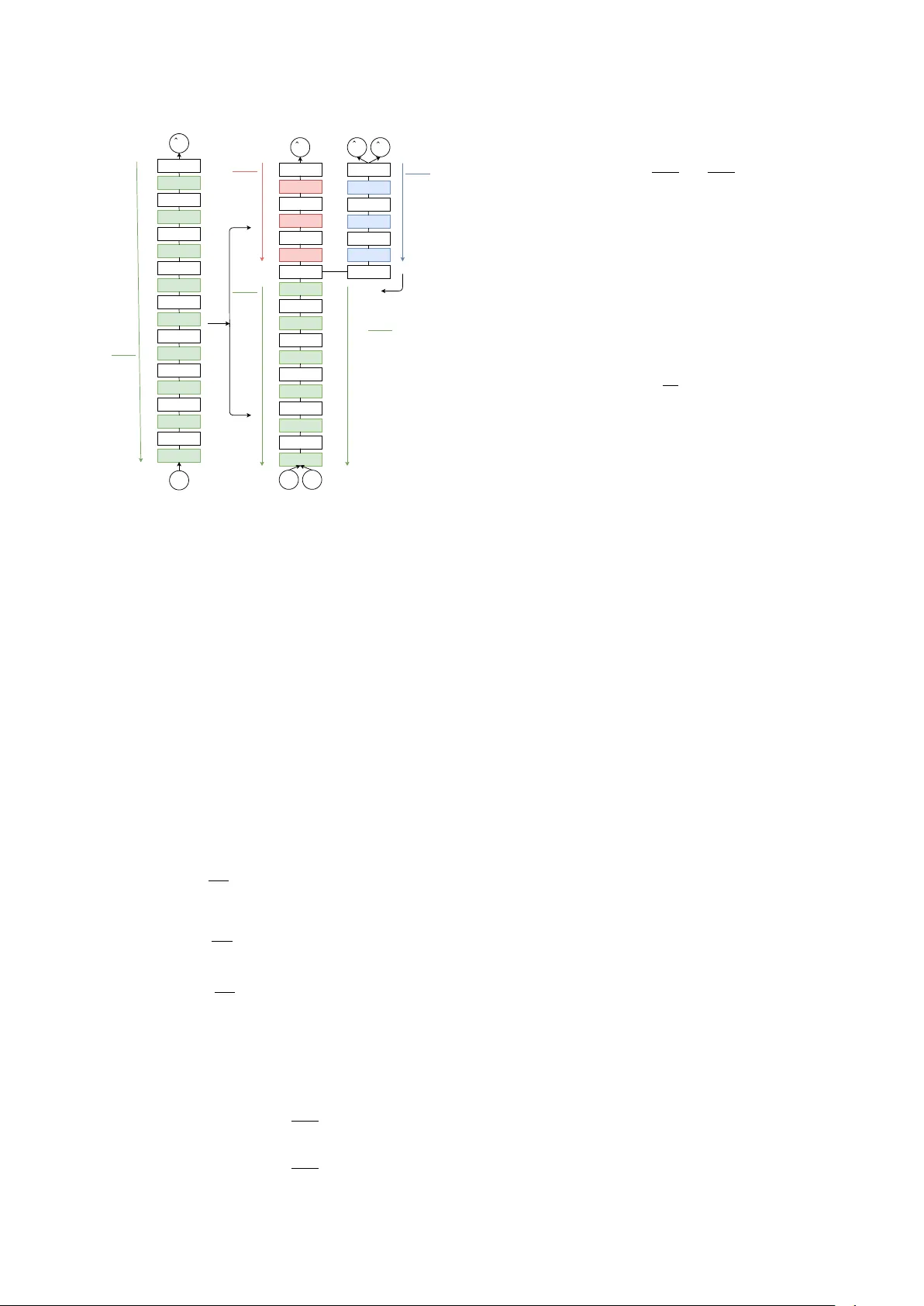
Unsupervised Domain Adaptation by Adversarial Learning f or Robust Speech Recognition P avel Denisov , Ngoc Thang V u, Mar c F err as F ont Institute for Natural Language Processing, Univ ersity of Stuttgart, German y Email: {pavel.denisov,thang.vu,marc.ferras}@ims.uni-stuttgart.de Abstract In this paper , we in vestigate the use of adversarial learn- ing for unsupervised adaptation to unseen recording condi- tions, more specifically , single microphone far-field speech. W e adapt neural networks based acoustic models trained with close-talk clean speech to the new recording condi- tions using untranscribed adaptation data. Our experimen- tal results on Italian SPEECON data set show that our pro- posed method achie ves 19.8% relativ e word error rate (WER) reduction compared to the unadapted models. Furthermore, this adaptation method is beneficial even when performed on data from another language (i.e. French) giving 12.6% relativ e WER reduction. 1 Intr oduction Recently with the success of deep learning methods, auto- matic speech recognition (ASR) has achieved human per- formance in con versational speech recognition [1, 2]. How- ev er, far-field speech, especially when recorded with single microphone, remains one of the major obstacles to achie v- ing complete human parity , mainly because of challenging en vironments with a lot of noises and rev erberations [3 – 7]. Another challenge is that it is almost impossible to collect data covering all recording en vironments to train and to test on due to variations of reverberations/noises and dis- tances to microphones. While there were some advance- ments in this direction for a fe w widespread languages, a large number of lo w-resource languages will ine vitably re- main uncov ered by such kind of resources. These facts motiv ate our interest for methods to improv e rob ustness of acoustic model by utilizing a vailable data, especially data from resource rich languages [8]. It is well known that a mismatch between training and testing conditions is likely to de grade accuracy of acoustic models. In case of Deep Neural Netw ork (DNN) acoustic modeling, this issue can be addressed by the wide range of transfer learning methods developed by the deep learning community . T wo well researched transfer learning meth- ods in ASR are weights transfer and multi-task learning. These two closely related methods were sho wn to be effi- cient in case of language mismatch [9 – 11], recording con- ditions mismatch [12] and combination of them [13]. Common ways to improv e accuracy of acoustic models on speech with dif ferent noises and re verberation strengths and forms, as well as used recording equipment, are speech enhancement techniques [14], feature engineering [15 – 17], simultaneous training on recordings from different en vi- ronments, particularly from simulated ones [18], and such standard deep learning techniques as dropout [19]. Do- main adaptation is another form of transfer learning, which is often used to perform speaker adaptation in ASR, but can also be applied to solve the problem of recording condi- tions mismatch. Adversarial multi-task learning was pro- posed for domain adaptation in image classification [20] and later shown to be ef ficient on other tasks [21]. The goal of adversarial multi-task learning is to com- bine feature extraction and domain adaptation problems to the single training process in a such w ay that learned fea- tures are discriminant to the main task and in variant to the domain. This is achie ved by joint optimization for two ob- jectiv es with well kno wn multi-task training method, which in volves sharing of some lo wer DNN layers between tasks and employing the output of the last shared layer as im- plicitly learned features for the two smaller task specific sub-networks. In adversarial multi-task learning, one of the tasks is the main classification task and another one is the domain discrimination task. Gradient of the loss func- tion is propagated to the shared layers as usual from the main classification task; howe ver , gradient of the domain classification loss function is inv ersed before being prop- agated to the shared layers, what promotes minimization of domain classification accurac y and domain in variance of the output of the last shared layer , thus making the in- put of the main classifier discriminant to the main task and domain in variant at the same time. Recent works inv estigated application of this method to improv e the robustness of ASR to variations in noise types and levels [22 – 24], to accented speech [25] and to speaker variation [26]. W e ev aluate applicability of adv er - sarial learning for unsupervised adaptation of an acoustic model trained on clean close-talk speech to speech recorded with a single microphone and in a far-field scenario. W e explore both cases, within the language (Italian) and lan- guage mismatch (Italian as target language and adaptation data is French) and compare its efficiency with other su- pervised training methods. T o the best of our knowledge, this study is the first ev aluation of unsupervised domain adaptation for ASR in a crosslingual setup. 2 Method Inspired by [27], we first perform regular training of DNN acoustic model on labeled source domain data (clean speech) and then adapt learned weights using mixture of same la- beled source domain data and unlabeled tar get domain data (noisy re v erberated speech). An o vervie w of the method is shown in Fig. 1. At the training stage, we only use data samples from the source domain X s = { x s 1 , . . . , x s N s } and correspond- ing senone labels Y s = { y s 1 , . . . , y s N s } . Based on DNN parameters θ , we calculate predicted senone labels ˆ Y s = { ˆ y s 1 , . . . , ˆ y s N s } and the v alue of cross-entropy loss function L y ( θ ) = − 1 N s N s ∑ i = 1 log P ( ˆ y s i = y s i | x s i ; θ ) , (1) The parameters are then updated via back-propagation for minimization of the loss function: θ ← θ − ∂ L y ∂ θ , (2) Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Softmax y ˆ s x s x t Linear Softmax d ˆ s d ˆ t GRL θ d θ f ∂ L y ∂ θ y ∂ L d ∂ θ d − λ − λ ∂ L d ∂ θ f θ y ∂ L y ∂ θ f Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Sigmoid Linear Softmax y ˆ s x s θ ∂ L y ∂ θ 1. T raining 2. Adaptation θ θ y θ f LReLU Linear LReLU Linear Figure 1: The architecture of DNN during the training and adaptation stages. where is the learning rate. At the adaptation stage, we use the same data samples from the source domain X s = { x s 1 , . . . , x s N s } and corre- sponding senone labels Y s = { y s 1 , . . . , y s N s } . W e also add data samples from the target domain X t = { x t 1 , . . . , x t N t } , for which we do not ha ve senone labels. In addition to that, we introduce secondary task of domain classification. The set of parameters θ , which were learned at the train- ing stage, is decomposed into two sets: the parameters of the first f hidden layers θ f , which are shared between the senone and domain classification tasks and act as a feature extractor , and the rest of the parameters θ y , which are used by senone classification part of DNN. New set of param- eters θ d is added for the domain classification task. Loss functions for the senone and domain classification tasks are defined as follows: L y ( θ f , θ y ) = − 1 N s N s ∑ i = 1 log P ( ˆ y s i = y s i | x s i ; θ f , θ y ) (3) L d ( θ f , θ d ) = − 1 N s N s ∑ i = 1 log P ( ˆ d s i = 1 | x s i ; θ f , θ d ) − 1 N t N t ∑ i = 1 log P ( ˆ d t i = 2 | x t i ; θ f , θ d ) (4) Note that we do not take into account senone label predic- tions for the target domain data samples X t , because we do not know true senone labels for them. T ask specific pa- rameters are updated to minimize corresponding loss func- tions: θ y ← θ y − ∂ L y ∂ θ y (5) θ d ← θ d − ∂ L d ∂ θ d (6) The update of shared parameters is performed so that it minimizes the senone classification loss function and max- imizes the domain classification loss function: θ f ← θ f − ∂ L y ∂ θ f − λ ∂ L d ∂ θ f (7) Maximization of the domain classification loss function aims making the output of the last shared hidden layer as less informativ e for the domain classifier as possible, and thus similar for data samples from different domains. The negati ve coefficient − λ is responsible for that and for the balance between the importance of this task and the pri- mary task of senone classification. λ is initially set to 0 and is increased gradually in the training process accord- ing to the following function: λ e = min ( e 10 , 1 ) λ, (8) where λ e is the value of gradient re versal coefficient used during epoch e . That is done in order to allo w the senone classification part of DNN to adjust its parameters to the output of the feature layer, which would be changed too fast by the domain classification part of DNN otherwise. 3 Experimental Setup 3.1 Datasets SPEECON is a family of speech corpora purposed for the dev elopment of speech recognition in consumer devices. The corpora were recorded for many languages according to the common specifications what allows us to ev aluate the propose method in case of language mismatch while other conditions are not altered in a significant way . W e use Italian data set for all the experiments and French as adaptation data in the cross-lingual experiment. Each cor- pus contains recordings of read and spontaneous speech by 550 adult speakers. The recordings are made in four acous- tic en vironments: office, entertainment, public place and car . Each recording is made with 4 microphones located on dif ferent distances from the speaker that are represented by 4 channels in SPEECON corpora: • Channel 1 corresponds to a close distance headset mi- crophone placed right in front of the speaker’ s mouth; • Channel 2 corresponds to a la valier microphone placed below the chin of the speak er; • Channel 3 corresponds to a middle distance microphone placed in 0.5–1.0 meters from the speaker; • Channel 4 corresponds to a far distance omni-directional microphone in of fice and entertainment environments or middle distance otherwise. T ranscriptions are con verted to lower case and cleaned up from punctuation marks. Summary of the used corpora is giv en in T ab . 1. In addition to that, 197 millions words of Italian Dedu- plicated CommonCrawl T ext are used to build Italian lan- guage model. Italian dictionary ILE with pronunciations for 588k words is used as a lexicon. 3.2 Baseline Our DNN-Hidden Marko v Model (HMM) acoustic model is a multilayer perceptron consisting of 8 hidden fully con- nected layers with 1024 units each and output layer with Italian French Number of utterances 174,940 182,679 Number of speakers 451 495 Duration (hours) 157 167 T able 1: Summary of SPEECON corpora. 9315 units corresponding to senones (HMM states). Sig- moid acti v ation function is used for the hidden layers and softmax activ ation function is used for the output layer . W e use Adam optimizer [28] and ne w-bob learning rate scheduler [29] with initial learning rate of 0.0001 for train- ing. The input of DNN is 23-band log Mel filterbank fea- tures with delta and delta-deltas and splicing with 5 context frames both left and right, giving 759 dimensions in total. T raining process iterates ov er data samples in randomized order with mini-batch size of 256 samples. NNabla [30] deep learning toolkit is used to implement DNN. Kaldi speech recognition toolkit [31] is used to build Gaussian Mixture Model-HMM acoustic model, to produce forced senone le vel alignments of training data required for DNN- HMM training and to perform decoding with DNN-HMM required for WER ev aluation. For decoding we also trained two 3-gram language models on the transcripts from the training data and on the CommonCrawl subset and inter - polated them with SRILM toolkit [32]. The perplexity of the language model on our testing data set is 209.47. Results of the baseline model trained on different data sets with different labels and tested on 15 hours of Italian SPEECON channel 4 are shown in T ab. 2. It is apparent from this table that decoding of noisy re verberated speech is a challenging task. While WER of the model trained on Channel 1 is incredibly high at 85.2% due to significant distortions introduced to speech by en vironmental noises and reverberations in the testing noisy speech data, the model trained on Channel 4 achie ves significantly lo wer WER by learning to normalize these distortions from the training data, and the model trained on Channels 1–4 re- sults e ven better WER because of the generalized repre- sentations of clean and noisy data samples presenting in the training data. Our analysis of problematic utterances suggests that as the majority of the mistakes are made in „Spontaneous speech”, „Numbers, times, dates” and „Named entities” categories, where the language model could not be helpful. An alternativ e to the proposed method would be to train a model on the target domain data and the labels produced by a first pass of unadapted model. As it follows from T ab. 2, this method does not seem to be practical in our setup, most likely because of extremely bad accuracy of the unadapted model. Moreover , the proposed method has an advantage of applicability in a crosslingual setup. System T raining data WER (%) Baseline Channel 1 85.2 First pass Channel 4 86.3 Oracle Channel 4 51.8 Oracle Channels 1–4 46.0 T able 2: Results of the baseline model. 3.3 Setup Description Each of the experiments starts with DNN weights trained on 125 hours of clean close-talk Italian speech training data. Adaptation stage is performed on a combination of clean speech training data with senone labels and noisy speech adaptation data without senone labels (technically they all are set to 0). The domain classification sub-network is added at adaptation stage and consists of 2 hidden fully connected layers with 512 units each and the output layer with 2 outputs corresponding to the source and target do- main classes in the adversarial task. Leak y ReLU acti v a- tion function [33] is used for the hidden layers and soft- max activ ation function is used for the output layer . Input of domain classification sub-network is output of the f - th hidden layer of the main network (feature layer) passed through a Gradient Rev ersal Layer (GRL). GRL passes its input intact to its output during the forward pass and re- turns the in versed and scaled by λ gradient value from its output to its input during the backward pass. Adaptation procedure could be then interpreted as a regularizer of the DNN training. After it is finished, the domain classifica- tion sub-netw ork is removed and decoding is performed as usual with the remaining DNN. Three experiments are conducted to inv estigate the ef- fectiv eness of the proposed method. In the first experi- ment, we in vestigate the interaction between GRL coeffi- cient λ and feature layer index f using 125 hours of chan- nel 4 (middle/far distance microphone) as adaptation data. The best GRL coefficient λ and feature layer index f are then used for further experiments. The second e xperiment explores the impact of the adaptation data size on the final performance. In the third experiment, we perform a cross- lingual study when using the same amount of adaptation data b ut from French in order to examine importance of the language of adaptation data. 4 Results 4.1 T raining Metrics Fig. 2 shows the accuracy values for senone classification and domain discrimination during the adaptation stage. T rain- ing data set consists of equal proportions of Channel 1 and Channel 4 recordings and v alidation data set consists of equal proportions of Channels 1–4 recordings of Italian SPEECON corpus. Accuracy is defined as the number of correctly classified samples di vided by the total number of samples. What stands out here is the markedly high ac- curacy of the domain classifier during the initial epochs, which suggests that the feature layer initially outputs quite distinct v alues for the clean and noisy speech. As the GRL coefficient is increased and the shared DNN parameters are adjusted tow ards more domain inv ariant representation, the accuracy of the domain classifier expectedly decreases and stabilizes slightly over the chance le vel around 55%. At the same time, the senone classification accurac y first drops quite sharply in response to changes in how the fea- ture layer represents the data and later recovers slowly due to the adaptation of the task specific layers to the ne w do- main in variant output of the feature layer made possible by the utilization of the labeled clean speech data samples. Another interesting observ ation can be made by comparing the metrics of the domain classifier for the training and val- idation data sets. The performance of the domain classifier for the training and validation data sets aligns to similar lev el after a fe w epochs of adaptation, which indicates that the representation learned by the shared DNN parameters does not just normalize seen data samples, b ut actually ex- tracts only the information not related with recording con- ditions. 0 2 4 6 8 10 12 14 32 34 36 38 40 42 44 Epoch Accuracy , % Training V alidation (a) Senone classifier 0 2 4 6 8 10 12 14 50 60 70 80 90 100 Epoch Accuracy , % Training V alidation (b) Domain discriminator Figure 2: Accuracy during the adaptation stage. 4.2 Effect of λ and f f λ 1.0 2.0 4.0 1 84.5 78.7 76.8 2 70.2 68.3 69.0 3 69.8 69.2 74.5 4 71.9 71.5 74.9 5 74.1 74.7 75.6 T able 3: Results (WER in %) of adaptation on 125 hours of Channel 4. First we use the fixed target domain data subset, namely 125 hours of Channel 4 recordings, to e valuate the effect of various combinations of the gradient rev ersal coef ficient λ and the feature layer index f . WER and relativ e error rate reduction (RERR) are listed in T ab. 3. The best com- bination is gradient re versal coefficient λ = 2 . 0 and fea- ture layer index f = 2 and it results WER of 68.3%, which is within almost twice smaller gap with the best result of 46.0%, obtained by supervised training on Channels 1–4, compared to 85.2% resulted by unadapted model trained on Channel 1. In addition to that, we repeat the same ex- periment with Channels 2–4 as adaptation data, as the best baseline system also utilizes this data. W e obtain WER of 66.6% and conclude that the gain in WER is too small in comparison to amount of additional adaptation data. 4.3 Effect of Adaptation Data Hours WER (%) RERR (%) - 85.2 - 50 69.7 18.2 40 70.5 17.2 30 71.8 15.7 20 75.4 11.5 10 85.4 -2.3 5 84.0 1.4 T able 4: Results of adaptation on Italian data with f = 2, λ = 2 . 0. Next we use the best combination of the gradient rev er- sal coefficient λ and the feature layer index f from the pre- vious experiment to ev aluate contribution of various amounts of adaptation data to accuracy of adapted model. Results are listed in T ab . 4. What emerges from the results re- ported here is that no significant drop in WER is observed if amount of adaptation data is decreased to 30 hours or one third of originally e valuated adaptation data set. On the one hand this finding suggests that one does not need to acquire large amount of the target domain data in order to get a moderate improv ement of ASR system trained on clean speech data. On the other hand, it is possible that this ef fect of 30 hours of adaptation data is due to a good chance of ha ving comparable number of distinct record- ing conditions in the adaptation and testing data and may not be generalizable to a larger testing data set with more div erse set of recording conditions. 4.4 Crosslingual Adaptation Hours WER (%) RERR (%) - 85.2 - 50 74.5 12.6 40 75.6 11.3 30 76.4 10.3 20 80.2 5.9 10 83.7 1.8 5 84.4 0.9 T able 5: Results of adaptation on French data with f = 2, λ = 2 . 0. W e also run experiments on the same amounts of French data to see if it is important to use adaptation data for the same language as the language of interest. Results are listed in T ab. 5. Interestingly , the method improv es WER ev en when used with the adaptation data for French while the language of interest is Italian. W e also observe the same trend regarding amount of French adaptation data as with Italian adaptation data, namely insignificant contri- bution of additional adaptation data, besides 30 hours, to WER. Hence, it could conceiv ably be hypothesized that the method makes DNN more robust to a number of dif- ferent recording conditions in general and not only to the recording conditions represented in the adaptation data. 5 Conclusions The present study was designed to gain a better under- standing of ability of unsupervised domain adaptation by adversarial Learning to improv e robustness of ASR. W e perform adaptation e xperiments on close-talk and far/middle distance recordings using the Italian and French SPEECON corpora. Our experimental results show that the proposed method improv ed significantly the WER in case of record- ing conditions mismatch without any transcriptions. Up to 19.8% relative WER improvement could be observed. Additionally , results on cross-lingual experiments also in- dicate that the usage of adaptation data from the same lan- guage is desirable, but not mandatory . Adaptation on French data resulted relativ e WER improvement up to 12.6%. The present in vestigation has not considered more dis- tant pairs of languages having smaller overlap in phonetic in ventory , which is one of possible directions for the fu- ture research. Further work needs to be done to establish whether our conclusions would hold for more advanced DNN architectures, such as TDNN [34, 35], LSTM [36] and CNN [37], and training methods, such as Lattice-free MMI [38]. Refer ences [1] W . Xiong, J. Droppo, X. Huang, F . Seide, M. Seltzer , A. Stolcke, D. Y u, and G. Zweig, “ Achieving human par- ity in con versational speech recognition, ” arXiv preprint arXiv:1610.05256 , 2016. [2] W . Xiong, J. Droppo, X. Huang, F . Seide, M. L. Seltzer, A. Stolcke, D. Y u, and G. Zweig, “T ow ard human parity in con versational speech recognition, ” IEEE/A CM T ransac- tions on Audio, Speech, and Langua ge Processing , vol. 25, no. 12, pp. 2410–2423, 2017. [3] V . Peddinti, V . Manohar , Y . W ang, D. Pove y , and S. Khu- danpur , “F ar-field ASR without parallel data, ” in Inter- speech , pp. 1996–2000, 2016. [4] T . Ko, V . Peddinti, D. Po ve y , M. L. Seltzer , and S. Khudan- pur , “ A study on data augmentation of re verberant speech for robust speech recognition, ” in ICASSP , pp. 5220–5224, IEEE, 2017. [5] Y . Zhang, P . Zhang, and Y . Y an, “ Attention-based LSTM with multi-task learning for distant speech recognition, ” In- terspeech , pp. 3857–3861, 2017. [6] J. Y i, J. T ao, Z. W en, and B. Liu, “Distilling knowledge using parallel data for far-field speech recognition, ” arXiv pr eprint arXiv:1802.06941 , 2018. [7] C. Spille, B. Kollmeier , and B. T . Meyer , “Comparing hu- man and automatic speech recognition in simple and com- plex acoustic scenes, ” Computer Speech & Language , 2018. [8] N. T . V u, Automatic speech r ecognition for low-resour ce languages and accents using multilingual and cr osslingual information . PhD thesis, Karlsruhe Institute of T echnology , 2014. [9] N. T . V u and T . Schultz, “Multilingual multilayer percep- tron for rapid language adaptation between and across lan- guage families, ” in Interspeech , pp. 515–519, 2013. [10] G. Heigold, V . V anhoucke, A. Senior , P . Nguyen, M. Ran- zato, M. Devin, and J. Dean, “Multilingual acoustic mod- els using distributed deep neural networks, ” in ICASSP , pp. 8619–8623, IEEE, 2013. [11] J. K unze, L. Kirsch, I. Kurenkov , A. Krug, J. Johannsmeier , and S. Stober , “T ransfer learning for speech recognition on a budget, ” ACL 2017 , p. 168, 2017. [12] P . Ghahremani, V . Manohar , H. Hadian, D. Pove y , and S. Khudanpur , “In vestigation of transfer learning for ASR using LF-MMI trained neural networks, ” in ASR U , pp. 279– 286, IEEE, 2017. [13] X. Zhuang, A. Ghoshal, A.-V . Rosti, M. Paulik, and D. Liu, “Improving DNN Bluetooth narrowband acoustic models by cross-bandwidth and cross-lingual initialization, ” Inter- speech , pp. 2148–2152, 2017. [14] Y . Zhao, Z.-Q. W ang, and D. W ang, “ A two-stage algorithm for noisy and reverberant speech enhancement, ” in ICASSP , pp. 5580–5584, IEEE, 2017. [15] C. Kim and R. M. Stern, “Power -normalized cepstral coef- ficients (PNCC) for robust speech recognition, ” in ICASSP , pp. 4101–4104, IEEE, 2012. [16] S. Ganapathy , “Multiv ariate autoregressi ve spectrogram modeling for noisy speech recognition, ” IEEE signal pr o- cessing letters , vol. 24, no. 9, pp. 1373–1377, 2017. [17] O. Ichika wa, T . Fukuda, M. Suzuki, G. K urata, and B. Ram- abhadran, “Harmonic feature fusion for robust neural network-based acoustic modeling, ” in ICASSP , pp. 5195– 5199, IEEE, 2017. [18] C. Kim, A. Misra, K. Chin, T . Hughes, A. Narayanan, T . Sainath, and M. Bacchiani, “Generation of large-scale simulated utterances in virtual rooms to train deep-neural networks for far-field speech recognition in Google Home, ” Interspeech , 2017. [19] G. Ko vács, L. T oth, D. V an Compernolle, and S. Ganap- athy , “Increasing the robustness of CNN acoustic models using autoregressiv e moving av erage spectrogram features and channel dropout, ” P attern Recognition Letters , vol. 100, pp. 44–50, 2017. [20] Y . Ganin and V . Lempitsky , “Unsupervised domain adap- tation by backpropagation, ” in International Conference on Machine Learning , pp. 1180–1189, 2015. [21] Y . Ganin, E. Ustinova, H. Ajakan, P . Germain, H. Larochelle, F . La violette, M. Marchand, and V . Lem- pitsky , “Domain-adversarial training of neural networks, ” The J ournal of Machine Learning Researc h , vol. 17, no. 1, pp. 2096–2030, 2016. [22] Y . Shinohara, “ Adversarial multi-task learning of deep neu- ral networks for robust speech recognition, ” in Interspeec h , pp. 2369–2372, 2016. [23] D. Serdyuk, K. Audhkhasi, P . Brakel, B. Ramabhad- ran, S. Thomas, and Y . Bengio, “Inv ariant represen- tations for noisy speech recognition, ” arXiv pr eprint arXiv:1612.01928 , 2016. [24] S. Sun, B. Zhang, L. Xie, and Y . Zhang, “ An unsupervised deep domain adaptation approach for robust speech recog- nition, ” Neur ocomputing , v ol. 257, pp. 79–87, 2017. [25] S. Sun, C.-F . Y eh, M.-Y . Hwang, M. Ostendorf, and L. Xie, “Domain adversarial training for accented speech recogni- tion, ” arXiv preprint , 2018. [26] Z. Meng, J. Li, Z. Chen, Y . Zhao, V . Mazalov , Y . Gong, et al. , “Speaker-in variant training via adversarial learning, ” arXiv preprint arXiv:1804.00732 , 2018. [27] Z. Meng, Z. Chen, V . Mazalo v , J. Li, and Y . Gong, “Un- supervised adaptation with domain separation networks for robust speech recognition, ” in Automatic Speech Recog- nition and Understanding W orkshop (ASR U), 2017 IEEE , pp. 214–221, IEEE, 2017. [28] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” arXiv preprint , 2014. [29] N. Morgan and H. Bourlard, “Continuous speech recog- nition, ” IEEE signal pr ocessing magazine , vol. 12, no. 3, pp. 24–42, 1995. [30] “NNabla — Neural network libraries by Sony , ” 2017. [31] D. Pov ey , A. Ghoshal, G. Boulianne, L. Burget, O. Glem- bek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz, et al. , “The Kaldi speech recognition toolkit, ” in ASR U , no. EPFL-CONF-192584, IEEE Signal Process- ing Society , 2011. [32] A. Stolcke, “SRILM — An extensible language modeling toolkit, ” in Se venth international conference on spoken lan- guage pr ocessing , 2002. [33] A. L. Maas, A. Y . Hannun, and A. Y . Ng, “Rectifier nonlin- earities improv e neural network acoustic models, ” in Pr oc. icml , vol. 30, p. 3, 2013. [34] A. W aibel, T . Hanazawa, G. Hinton, K. Shikano, and K. J. Lang, “Phoneme recognition using time-delay neural net- works, ” in Readings in speech r ecognition , pp. 393–404, Elsevier , 1990. [35] V . Peddinti, D. Pov ey , and S. Khudanpur , “ A time delay neural network architecture for ef ficient modeling of long temporal contexts, ” in Interspeech , 2015. [36] A. Grav es, A.-r . Mohamed, and G. Hinton, “Speech recog- nition with deep recurrent neural networks, ” in ICASSP , pp. 6645–6649, IEEE, 2013. [37] O. Abdel-Hamid, A.-r. Mohamed, H. Jiang, and G. Penn, “ Applying con volutional neural networks concepts to hy- brid NN-HMM model for speech recognition, ” in ICASSP , pp. 4277–4280, IEEE, 2012. [38] D. Povey , V . Peddinti, D. Galvez, P . Ghahremani, V . Manohar, X. Na, Y . W ang, and S. Khudanpur, “Purely sequence-trained neural networks for ASR based on lattice- free MMI, ” in Interspeech , pp. 2751–2755, 2016.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment