Large-Scale Weakly Labeled Semi-Supervised Sound Event Detection in Domestic Environments
This paper presents DCASE 2018 task 4. The task evaluates systems for the large-scale detection of sound events using weakly labeled data (without time boundaries). The target of the systems is to provide not only the event class but also the event t…
Authors: Romain Serizel (MULTISPEECH), Nicolas Turpault (MULTISPEECH), Hamid Eghbal-Zadeh
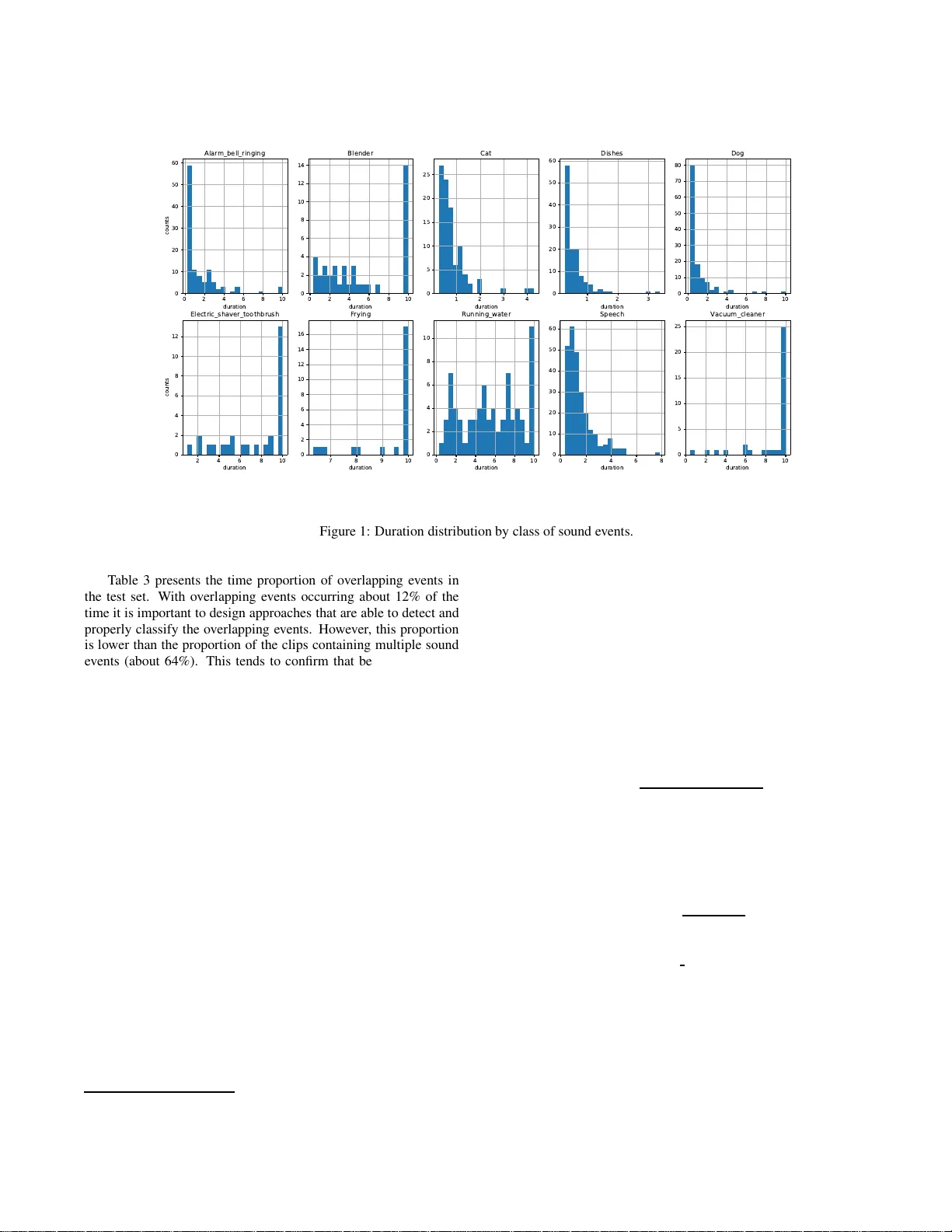
Detect ion and Cla ssificatio n of Acoustic Scene s and Ev ents 201 8 19-20 No v ember 2018, Surrey , UK LARGE-SCALE WEAKL Y LABELED SEMI-SUPER VISED SOUND EVENT DETECTION IN DOMESTIC ENVIR ONMENTS Romain Serizel 1 , Nicolas T urpault 1 ∗ , Hamid Eghbal-Zadeh 2 † , Ankit P arag Shah 2 1 Univ ersit de Lorraine, CNRS, Inria, Loria, F-54000 Nancy , France 2 Institute of Computational Perception, J ohannes Kepler Univ ersity of Lin z, Austria 3 Language T echnologies Insti tute, Carnegie Mellon U n i versity , Pittsbur gh P A, Un i ted States ABSTRA CT This paper presents DCASE 2018 task 4. The task e v aluates sys- tems for the large-scale detection of sound ev ents using weakly la- beled data (without time bounda ries). The target of the systems is to provid e not only the ev ent class but also the eve nt time boundaries gi ven that multiple even ts can be present in an audio recording. An- other challenge of the task is to explore the possibility to exploit a large amount of unbalanced and unlabeled training data together with a small weakly labeled training set to improv e system perfor- mance. The data are Y outube video excerpts from domestic context which have many applications such as ambient assisted living . T he domain was chosen due to the scientific challenges (wide variety of sounds, time-localized ev ents. . . ) and potential industrial applica- tions. Index T erms — Sound e vent detection, Large scale, W eakly la- beled data, Semi-supervised learning 1. INTRODUCTION W e are constantly surrounded by sounds and we rely heavily on these sounds to obtain important information about what is happen- ing around us. Ambient sound analysis aims at automatically ex - tracting information from these sounds. It encompasses disciplines such as sound scene classification (in which contex t does this hap- pen?), sound ev ent detection ( SED) and classification (what hap- pens during this recording?) [1]. It has been attracting a continu- ously growing attention during the past years as it can hav e a great impact in many applications including smart citi es, autonomous cars or ambient assisted living. In this task, we focus on SE D with time boundaries in domestic applications. The system then has to de tect when an soun d ev ent oc- curs and what i s the class of the ev ent (as opposed to audio tagging where only the presence of a sound e ve nt is important regardless of when it happened). Current systems heavily rely on a supervised training phase and usually require a large set of sound recordings labeled in terms of e ven t with time boundaries. Obtaining such an- notations is tedious and it is hardly feasible to gather a suf ficient amount of data to train state-of-the-art systems that are often rely- ing on complex deep networks architectures [2, 3, 4 , 5, 6]. W e propos e to follow-up on DCASE2017 task 4 [7 ] and in v es- tigate the scenario where a large scale corpus is av ailable but only a small amount of the data is labeled. W e propose t o use a subset of ∗ This work has been funded by the French region G rand-Est. † This work has been funded by the Austrian Ministri es BMVIT and BMWFW , and the Province of Upper Austria, via the COMET Center SCCH. the Audioset corpus [8] targeting classes of sound ev ents related to domestic app lications. T he l abels are provided at cli p lev el (an ev ent is present or not within a sound clip) but without the t i me bound - aries (weak labels, that can also be refereed t o as tags) i n order to further decrease the annotation time. These constraints indeed cor- responds to constraints faced in many real applications where the budg et all ocated t o annotation is limited. In order t o fully exploit this dataset, the proposed systems w i ll hav e to tackle two different problems. The first problem is related to the exploitation of t he unlabeled part of the dataset either in un- supervised approache s [9, 10] or together with the labeled subset in semi-supervised approaches [11, 12, 13]. The second problem is related to the detection of the time boundaries and how to train a system that can detect t hese boundaries from weakly labeled data. Currently , most of the state-of-the-art approaches rely mainly on smoothing technique s to ensure time consistency [6, 14 , 15] which is not sufficient to estimate the time boundaries accurately . The e v aluation metric chosen is penalizing these boundary estimation errors heavily i n order to emphasize this latt er aspect. This manuscript describes DCAS E2018 task 4 and is organized as follows. Section 2 presents the dataset used in task 4. The task e v aluation procedure is described in Section 3. The baseline system is described and e v aluated in 4. Conclusions and perspecti v es are presented in Section 5 2. A UDIO D A T ASET The task employs a subset of Audioset [8]. Audioset consists of an expanding ontology of 632 classes of sound even ts and a collec- tion of 2 mil lion human-labeled 10-seconds sound cli ps (less than 21% are shorter than 10 seconds) drawn from 2 million Y ouT ube videos. The ontology is specified as a hierarchical graph of e ve nt categories, cov ering a wide range of human and animal sounds, mu- sical instruments and genres, and common ev eryday en vironmental sounds. Audioset provides labels at clip lev el (without time boundaries for the ev ents) also kno wn as weak labels. Audio clips are collected from Y outu be videos uploaded by independent users so the number of cl i ps per class varies dramatically and the dataset is not balanced 1 . Google researchers conducted a quality assessment task where experts were exposed to 10 randomly selected clips for each class of sound ev ents and discovered that in most of the cases not all the clips contains the ev ent related to the gi ven label. More i nformation about the initi al annotation process can be found i n Gemmek e et al. [8]. 1 see also https://research.google. com/Audioset//datas et/index.h t m l Detect ion and Classification of Acoustic Scenes and Events 2018 19-20 Nove mber 2018, Surrey , UK Class Count Duration (in s) T raining T est T est clips clips ev ents mean median Alarm/bell/ringing 205 45 112 1.53 0.58 Blender 134 30 40 5.35 4.59 Cat 173 32 97 0.81 0.71 Dishes 184 35 122 0.56 0.42 Dog 214 29 127 1.03 0.66 Electric shave r/toothbrush 103 25 28 7.41 8.78 Frying 171 24 24 9.34 10.00 Running water 343 63 76 5.61 5.53 Speech 550 105 261 1.51 1.20 V acuum cleaner 167 35 36 8.66 9.99 T otal 2244 288 906 2.41 1.03 T able 1: Class-wise statisti cs Number of classes 1 2 3 and more Clip proportion 62.36% 32.89% 4.75% T able 2: Proportion of clips with multiple classes of sound ev ents (training set) W e will focus on a subset of Audioset that consists of 10 classes of sound events (T able 1). The dev elopment set pro vided for task 4 is split into a training set and a test set 2 . 2.1. T rainin g set In order t o reflect what could possibly happen in a real-world sce- nario, we prov ide 3 different splits of training data in task 4 training set: a l abeled training set, an unlabeled i n domain training set and an unlabeled out of domain training set. 2.1.1. L abeled tra ining set This set contains 1,578 cli ps (2,244 class occurrences) for which weak labels prov ided in Audioset have been verified and corrected by human annotators. The weak labels are provided in a tab- separated csv file under the follo wing format: [filename (str)][tab][cla ss label ( str)] The first column is the name of the sound clip downlo aded from Y ouTu be composed of the Y ouT ube ID of the video and the time boundaries of the 10-seconds audio clip extracted from the video. The last column correspon ds to the sound e ven ts that are present in the clip, each separated by a semi-colon. The amount of cli ps per class of sound ev ents is presented in T able 1 and the number of classes observed per clip is presented in T able 2. One-third of the clips in this set contain at least two differe nt classes of sound e ven ts. 2.1.2. U nlabeled in domain training set This set contains 14,412 clips. T he clips are selected such that the distribution per class of sound ev ent (based on Audioset labels) is close to t he distribution in the labeled set. Note howe v er that giv en 2 The annotat ions files and the script to do wnload the audio files is a v ailabl e on the git repositor y for task 4 https://github .com/DCASE- REPO/dcase2018 _baseline/tree/master/task4/dataset Number of even ts 1 2 3 and more T ime proportion 86.86% 10.40% 2.74% Clip proportion 33.68% 17.71% 48.61% T able 3: Proportion of overlapp ing e ven ts (test set) the uncertainty on Audioset labels this distri bu tion mi ght not be ex- actly similar . Audioset labels have not been verified for this subset and should not be used during the systems deve lopment. 2.1.3. U nlabeled out of domain training se t This set is co mposed of 39,99 9 clips ex tracted from classes of sound e vents that are not considered in the task. Note that these cli ps are chosen based on the Audioset l abels which are not verified for this subset and therefore might be noisy . Additionally , as the speech class is present in about half of the clips in Audioset, the unlabeled out of domain set also contains almost 20000 clips wi th speech. This was the only way to hav e a set which is somehow representa- tiv e of Audioset. Indeed, discarding speech would have also meant discarding many other classes of sound ev ents and the v ariability of the set would hav e been penalized. Audioset labels hav e not been verified for this subset and should not be used during the systems de velop ment. 2.2. T est set The test set is designed such t hat t he distribution in term of clips per class of sound ev ent is similar to that of t he weakly labeled training set. T he size of the test set is such that it represents about 20% of the size of the weakly labeled training set, it contains 288 cl i ps (906 even ts). The test set is annotated with strong labels, with time boundaries (obtained by human annotators). The minimum length for an ev ent is 250 ms. The minimum duration of the pause between two ev ents from the same class is 150 ms. When the silence between two consecuti ve eve nts from t he same class was less than 150 ms the ev ents hav e been merged to a single ev ent. T he strong labels are prov ided in a tab-separated csv file under the following format: [filename (str)][tab][o nset (float)][t a b][offset (float)][ta b ][class label ( str)] The first column, is t he name of the audio file download ed from Y ouTu be, the second column is the onset time in seconds, the third column is the offset time in seconds and t he l ast column corresponds to the class of the sound ev ent. The amount of ev ents per class is presented in T able 1. T his table also presents the mean and median duration of the even ts for each class. From these durations it is possible to categorize the e vents into three classes: short ev ents (Alarm, cat, dishes, dog and speech), events wi th v ariable duration (blender and running water) and long ev ents that span almost ov er t he whole clip (electric shaver , frying and v acuum cleaner). This classification is confirmed by t he observ ation of the duration distr ibution presented on Figure 1 . One of the focus of this task is the dev elopment of approaches that can provide fi ne time-lev el segmen tation while learning on weakly labeled data. The observ ation of t he even t duration distri- bution confirms that in order to perform well it is essential to de- sign approaches that are ef ficient at detecting both short ev ents and e vents that have a l onger duration. Detect ion and Classification of Acoustic Scenes and Events 2018 19-20 Nove mber 2018, Surrey , UK 0 2 4 6 8 1 0 d u r a ti on 0 1 0 2 0 3 0 4 0 5 0 6 0 c ou n ts A l a r m_b e l l _r i n g i n g 0 2 4 6 8 1 0 d u rati o n 0 2 4 6 8 1 0 1 2 1 4 Bl e n d e r 1 2 3 4 d ura ti on 0 5 1 0 1 5 2 0 2 5 C a t 1 2 3 d u rati o n 0 1 0 2 0 3 0 4 0 5 0 6 0 Di sh e s 0 2 4 6 8 1 0 d ura ti o n 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 Do g 2 4 6 8 1 0 d u r a ti on 0 2 4 6 8 1 0 1 2 co u nts El e c tric _sh a v e r _to o th b r u sh 7 8 9 1 0 d u rati o n 0 2 4 6 8 1 0 1 2 1 4 1 6 F r y in g 0 2 4 6 8 1 0 d ura ti on 0 2 4 6 8 1 0 R u n n i n g _wa te r 0 2 4 6 8 d u rati o n 0 1 0 2 0 3 0 4 0 5 0 6 0 S p e e c h 0 2 4 6 8 1 0 d ura ti o n 0 5 1 0 1 5 2 0 2 5 Va c u u m_c l e a n e r Figure 1: Duration distribution by class of sound even ts. T able 3 presents the time proportion of ov erlapping e ven ts in the test set. With overlapp ing ev ents occurring about 12% of the time it is important to design approaches t hat are able to detect and properly classify the overlapping ev ents. Ho we ver , this proportion is lowe r than the proportion of the clips containing multiple sound e vents (about 64%). This tends to confirm that being able to dis- criminate between ev ents that occur at different t i mes wit hin the clip is of a high importance as well. This aspect reinforces the fo- cus on efficient t i me segmentation. 2.3. Evaluation set The ev aluation set contains 880 10-seconds audio clips. The pro- cess to select the clips was similar to the process applied t o select clips in the training set and the test set, in order to obtain a set with comparable classes distribution. Labels with time boundaries (ob- tained by human annotators) will be released after the DCASE 2018 challenge is concluded. 3. T ASK DESCRIPTION The task consists of detecting sound ev ents within web videos using weakly labeled training data. The detection within a 10-seconds cli p should be performed with start and end t i mestamps. T ask rules are detailed on the challenge webpage 3 . 3.1. T ask eva luation Submissions wil l be ev aluated with event-b ased measures f or which the system output is compared t o the reference labels eve nt by e vent [16]. True positiv es are the occurrences when an ev ent present 3 http://dcase.c ommunity/challenge2 018/ in the system output corresponds to an ev ent in the reference annota- tions. The correspon dence between eve nt boundaries are estimated with a 200ms collar tolerance on onsets and a tolerance on offsets that is t he maximum of 200ms and 20% of the ev ent length. False positi ves are obtained when an ev ent is present in the system output but not in the reference annotations (or not within the tolerance on the onset or the of fset). False ne gativ es are obtained when an e ve nt is present in the reference annotations but not in the system output (or not within t he tolerance). Submissions will be ranked according to the eve nt-based F1- score. The F1-score is fi rst computed class-wise over the whole e v aluation set: F 1 c = 2 T P c 2 T P c + F P c + F N c , (1) where T P c , F P c and F N c are the number of true positiv es, false positi ves and false negati ve for class of sound ev ent c over the whole e v aluation set, respectively . The final score is the F1-score average over class regardless of the number of even ts per class (macro-av erage): F 1 macro = P c ∈C F 1 c n C , (2) where C is the classes ensemble and n C . Eva luation is done using sed e v al toolbox [16]. The choice of the macro av eraging allows for according the same importance to each class of sound event in an unbalanced scenario as in task 4. 4. BASELINE 4.1. S ystem description The baseline system is based on conv olutional recurrent neural net- works (C RNN). The number of 64 log mel-band magnitudes are Detect ion and Classification of Acoustic Scenes and Events 2018 19-20 Nove mber 2018, Surrey , UK Figure 2: Baseline system description extracted f rom 40 ms frames wit h 50% overlap. Using these fea- tures, we train a fi rst CRNN with three con volution layers (64 filters (3x3), max pooling (4) along the frequency axis and 30% dropout), one recurrent l ayer (64 Gated Recurrent Unit s with 30% dropout on the input), a dense layer (10 units si gmoid activ ation) and global av erage pooling across frames (Figure 2). The system is tr ained for 100 epochs (early st opping after 15 epochs patience) on weak labels (‘train/weak‘, 1,578 clips). 20% of this set is used for validation. This model is trained at clip lev el, the annotations only i ndicate if the e vent i s present or not during the clip. The inputs are 500 frames long for a single output frame. T his first model is used to predict labels of unlabeled fi les (‘train/unlabel in domain‘, 14,412 clips). A second model based on the same architecture (Figure 2) is trained on predictions of the first model on the unlabeled sub- set (‘ t rain/unlabel in domain‘). T he fi les wit h manual annotations (‘train/weak‘) are used for the v alidation of the model. The main differe nce with the fi rst pass model is that the output dense l ayer is time-distributed in order to be able t o predict ev ents at the frame lev el. The inputs are 500 frames l ong, each of them labeled identi- cally following clip labels. The model outputs a decision for each of these 500 frames. Median filtering ov er 51 frames ( ≈ 1 s) is applied to the output of the network, in order to obtain the ev ents onset and of fset for each fi le. The full process is described in Algorithm 1. 4.2. System performance The F1-score performance of the baseline system after the first pass (training on ‘train/weak‘ data) and aft er the second pass (training on ‘train/unlabel in domain‘ wit h labels obtained with the first pass system) are presented in T able 4. The second pass improv es per- formance compared to the first pass in macro-averag e and for all classes expec t for ‘Dishes‘. T herefore, the baseline system takes adv antage of the unlabeled data ev en though this could probably be done more efficiently by the systems submitted to the task. The F 1-score is close to zero for all the short e vent classes. It is slightly higher for ev ent with variable duration (running water Algorithm 1 Script description 1: procedure D OW N L O A D T H E D A TA ( O N LY T H E FI R S T T I M E ) 2: end procedure 3: procedure F I R S T PA S S (at clip lev el) 4: Train a CRNN on weakly labeled data (‘train/weak‘) ⊲ 20% of data used for v alidation 5: Predict class for unlabeled data (‘train/unlabel in domain‘) 6: end procedure 7: procedure S E C O N D PA S S (at frame lev el) 8: Train a CRNN on labels predicted for t he unlabeled data during the first pass (‘train/unlabel in domain‘) ⊲ weak data (‘train/weak‘) is used for validation ⊲ Labels are used at frames lev el. If a class is present in the clip, all fr ames contain the label. 9: Predict strong test labels (‘test/‘) ⊲ Predict an e ve nt with an onset and an of fset 10: end procedure 11: procedure E V A L UAT I O N (event based) 12: Evaluate the prediction on the test set with respect to man- ual annotations 13: end procedure Class 1 st pass 2 nd pass Alarm/bell/ringing 3.2% 3.9% Blender 10.1% 15.4% Cat 0.0% 0.0% Dishes 1.9% 0.0% Dog 0.0% 0.0% Electric shav er/toothbrush 18.2% 32.4% Frying 9.4% 31.0% Running water 7.6% 11.4% Speech 0.0% 0.0% V acuum cleaner 24.8% 46.5% Macro averag e 7.51% 14.06% T able 4: Event based F 1-scores and blender) and performs the best for the long ev ent class. This tends to indicate that the baseline performs very poorly i n time- segmen tation which is one of the focus of this task. Errors in segmen tation are heavily penalized by the metric as they result in both a false positiv e and a false negati ve. Therefore, in order to improv e performance, submitted systems should propose efficient time-segmentation approaches. 5. CONCLUSION This paper presents DCASE 2018 task 4 on large-scale weakly la- beled semi-supervised SED in domestic en vironments. The goal is to exploit a small dataset of weakly l abeled sound clips (without time boundaries) together with a larger unlabeled dataset to perform SED (wi t h time boun daries). This indeed corresponds to a realistic scenario as obtaining time coded annotations is time consuming and is generally considered as one of the principal bottlenecks in train- ing SED systems. The design of the dataset with a wide variability in ev ent l engths and t he choice of a metric that is heavily penalizing segmen tation errors put a strong focus on the problem of localizing the ev ents in ti me. Detect ion and Classification of Acoustic Scenes and Events 2018 19-20 Nove mber 2018, Surrey , UK 6. REFERENCES [1] T . V irtanen, M. D. P lumble y , and D. E llis, Computational analysis of sound scenes and events . Springer, 2018. [2] G. Parascando lo, H. Huttunen, and T . V irtanen, “Recurrent neural networks for polyphonic sound eve nt detection in real life recordings, ” in Pr oc. ICASSP , Mar . 2016, pp. 6440–6 444. [3] N. T akahashi, M. Gygli, B. Pfi ster , and L. V an Gool, “Deep con v olutional neural networks and data augmentation for acoustic e ven t detection, ” in P r oc. INTERSPE ECH , Apr . 2016. [4] S . Adav anne, G. Parascandolo, P . Pertil ¨ a, T . Heittola, and T . V i rtanen, “Soun d ev ent detection in multichannel au- dio using spatial and harmonic features, ” i n arXiv pr eprint arXiv:1706.022 93 , 2017. [5] E . C akir , G. Parascandolo, T . Heittola, H. Huttunen, and T . V irtanen, “Con v olutional recurrent neural networks for polyphon ic sound eve nt detection, ” IEEE/ACM T ra nsactions on Audio, Speech, and Langua ge Processin g , vol. 25, no. 6, pp. 1291–130 3, 2017. [6] Y . Xu, Q. K ong, W . W ang, and M. D. Plumbley , “Large-scale weakly supervised audio classification using gated con vo lu- tional neural network, ” in Proc. DCASE , 2017. [7] A. Mesaros, T . Heittola, A. Diment, B. Elizalde, A. Shah, E. V incent, B. Raj, and T . V irtanen, “Dcase 2017 challenge setup: T asks, datasets and baseline system, ” in Pr oc. DCASE , 2017. [8] J. F . Gemmeke, D. P . W . E l lis, D. Freedman, A. Jansen, W . Lawrence, R. C. Moore, M. P lakal, and M. Ritt er , “ Audio set: An ontology and human-labeled dataset f or audio events, ” in Pr oc. ICASSP , 2017. [9] J. Salamon and J. P . Bello, “Unsupervised feature learn- ing for urban sound classifi cation, ” in 2015 IEEE Interna- tional Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , April 2015, pp. 171–175. [10] A. Jansen, M. P lakal, R. Pandya, D. Elli s, S. Hershe y , J. Liu, C. Moore, and R. A. Saurous, “Unsupervised learning of se- mantic audio representations, ” in Pr oc. ICASSP , 2018. [11] Z. Zhang and B. Schuller , “Semi-supervised learning helps in sound ev ent classification, ” in P r oc. I CASSP , 2012, pp. 333– 336. [12] T . Komatsu, T . T oizum i, R. Kond o, and Y . Senda, “ Acoustic e vent detection method using semi-supervised non-negati v e matrix factorization with a mixture of local dictionaries, ” in Pr oc. DCASE) , 2016, pp. 45–4 9. [13] B. Elizalde, A. S hah, S. Dalmia, M. H. Lee, R. Badlani, A. Kumar , B. Raj, and I. Lane, “ An approach for self-training audio e vent detectors using web data, ” in Pro c. EUSIPCO , 2017, pp. 1863–18 67. [14] I. - Y . Jeong, S . L ee, Y . Han, and K. L ee, “ Audio even t detection using multiple-input con volution al neural network, ” in Pr oc. DCASE , 2017, pp. 51–54. [15] J. Lee, J. Park, S. Kum, Y . Jeong, and J. Nam, “Combin- ing multi-scale features using sample-lev el deep con vo lutional neural networks for weakly supervised sound ev ent detection, ” in Pr oc. DCASE , 2017, pp. 69–73. [16] A. Mesaros, T . Heittola, and T . V irtanen, “Metrics for poly- phonic sound ev ent detection, ” Applied Science s , vol. 6, no. 6, p. 162, May 2016.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment